Adaptive Online Scheduling in Storm: Enhancing Data Processing Efficiency
0 likes | 12 Views
Paper presented by Keshav Santhanam on adaptive online scheduling in Storm, focusing on efficient data processing in the era of big data. The presentation covers the motivation behind the need for complex event processing, overview of Storm as a high throughput data processing engine, key concepts such as topologies, tuples, and bolts, challenges with existing scheduling strategies, and the proposed adaptive scheduling approach. The strategy involves offline and online schedulers that aim to reduce network traffic by placing frequently communicating executors together in the same slot. Offline scheduling is based on topology analysis before deployment, while online scheduling adjusts schedules based on real-time network traffic analysis. The presentation highlights the heuristic used for executor placement, assumptions made, and the topology-based scheduling process.

Adaptive Online Scheduling in Storm: Enhancing Data Processing Efficiency
E N D
Presentation Transcript
Adaptive Online Scheduling in Storm Paper by Leonardo Aniello, Roberto Baldoni, and Leonardo Querzoni Presentation by Keshav Santhanam

-

Motivation • Big data • 2.5 quintillion bytes of data generated per day [IBM] • Volume, velocity, variety • Need complex event processing engine • Represent data as a real-time flow of events • Analyze this data as quickly as possible

-

Storm • Processing engine for high throughput data streams • Used by Groupon, Yahoo, Flipboard, etc.

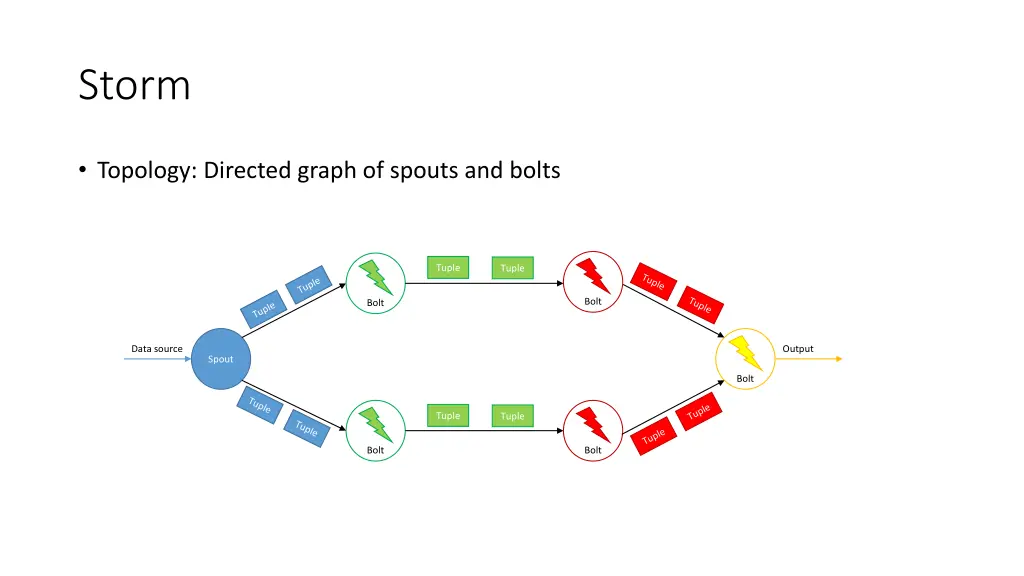
Storm • Topology: Directed graph of spouts and bolts Tuple Tuple Bolt Bolt Data source Output Spout Bolt Tuple Tuple Bolt Bolt
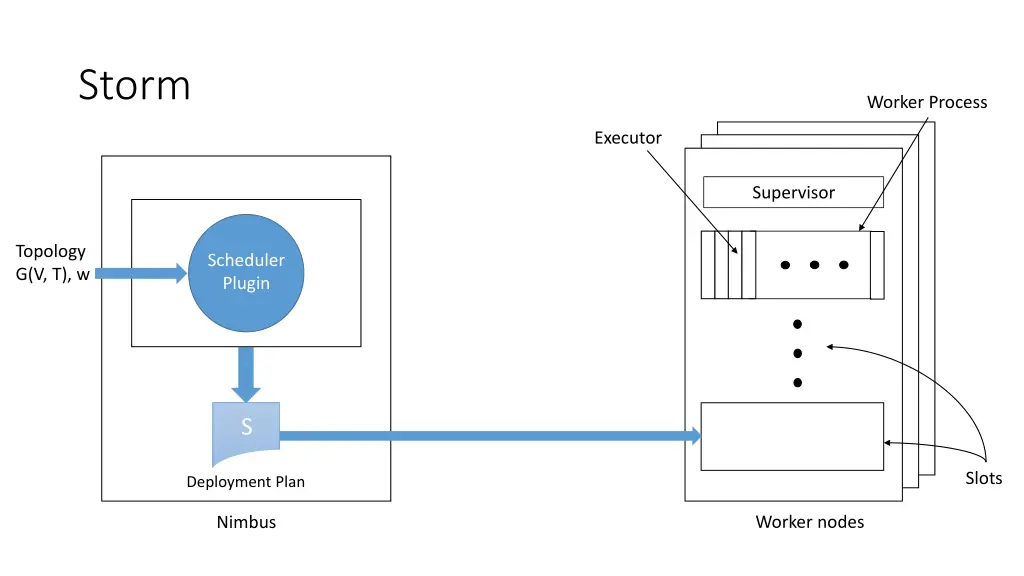
Storm Worker Process Executor Supervisor Topology G(V, T), w Scheduler Plugin S Slots Deployment Plan Worker nodes Nimbus
Storm • Grouping strategies • Shuffle grouping: target task is chosen randomly • Ensures even distribution of tuples • Fields grouping: tuple is forwarded to a task based on the content of the tuple • E.g. tuples with key beginning with A-I are sent to one task, J-R to another task, etc.

Storm • EvenScheduler • Round robin allocation strategy • First phase: assigns executors to workers evenly • Second phase: assigns workers to worker nodes evenly • Problem: does not take into account network communication overhead • Solution: • Identify “hot edges” of the topology • Map hot edges to inter-process channels

-

Adaptive Schedulers • Key idea: place executors that frequently communicate together into the same slot, thus reducing network traffic • Offline scheduler • Examine the topology before deployment and use a heuristic to place the executors • Online scheduler • Analyze network traffic at runtime and periodically re-compute a new schedule • Assumptions • Only acyclic topologies • Upper bound on number of hops for a tuple as it traverses topology • Parameter α [0, 1] affects the maximum number of executors in a single slot

-

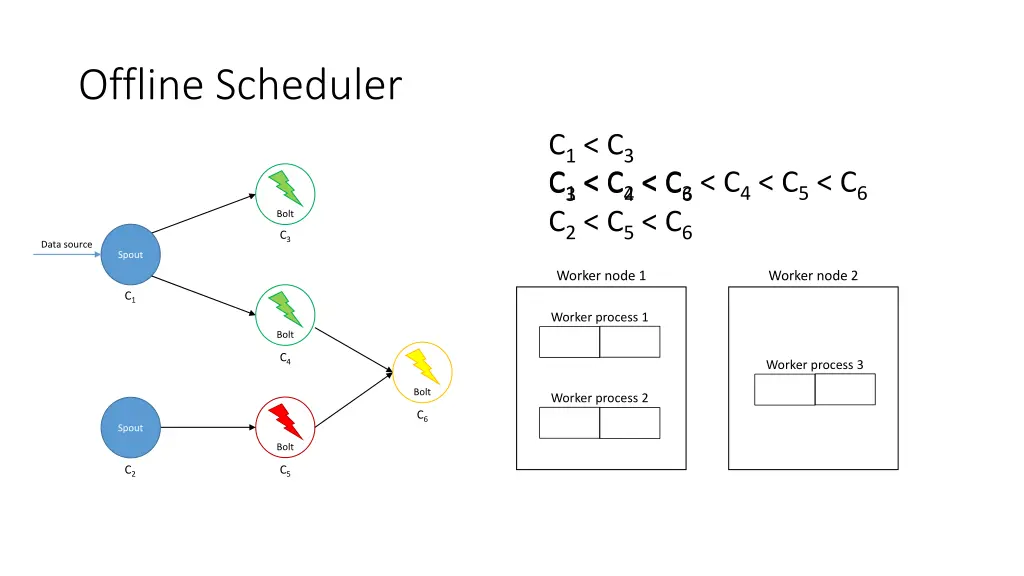
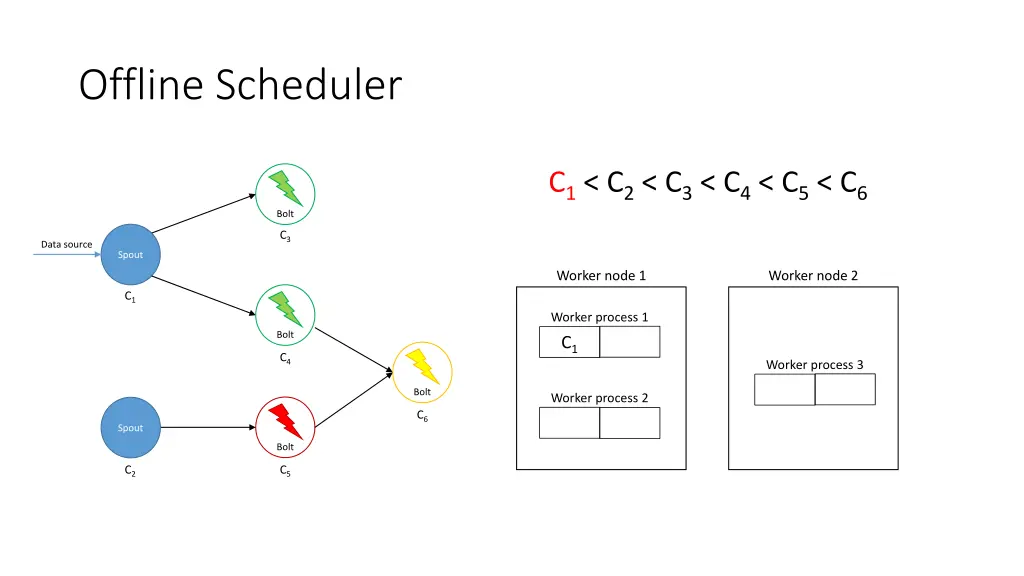
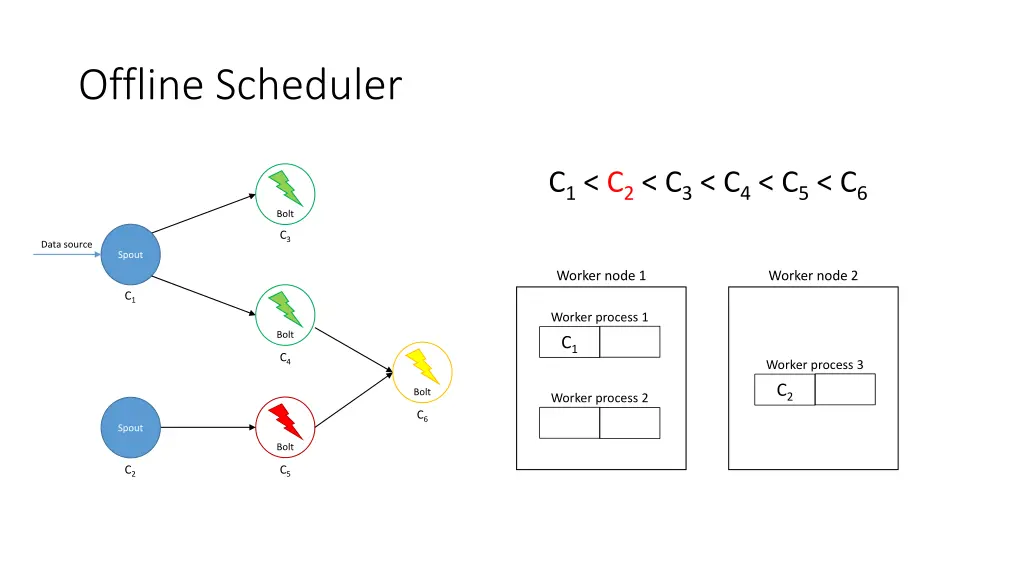
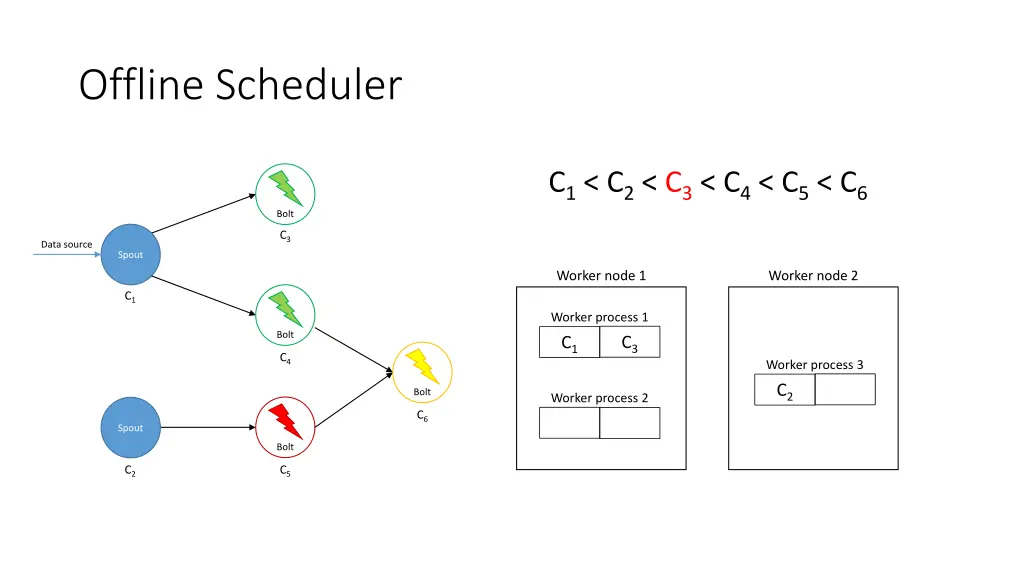
Offline Scheduler 1. Create a partial ordering of components • If component ci emits tuples that are consumed by another component cj then ci < cj • If ci < cjand cj< ck, then ci < ck(transitivity) • There can be components ci and cjsuch that neither ci< cjnor cj< ci are true 2. Use the partial order to create a linearization φ • If ci < cithen ci appears before cjin φ • The first element of φ is a spout 3. Iterate over φ and for each component ci, place its executors in the slots that already contain executors of the components that directly emit tuples towards ci 4. Assign the slots to worker nodes in round-robin fashion

Offline Scheduler • Problem: If a worker does not have an executor it gets ignored • Solution: Use a tuning parameter β [0, 1] to force scheduler to use its empty slots • Use a higher β if traffic is expected to be heavier among upstream components

Offline Scheduler C1< C3 C3< C4< C6 C2< C5< C6 C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C4 Worker process 3 Bolt Worker process 2 C6 Spout Bolt C2 C5
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C1 C4 Worker process 3 Bolt Worker process 2 C6 Spout Bolt C2 C5
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C1 C4 Worker process 3 C2 Bolt Worker process 2 C6 Spout Bolt C2 C5
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C2 Bolt Worker process 2 C6 Spout Bolt C2 C5
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C2 Bolt Worker process 2 C6 C4 Spout Bolt C2 C5
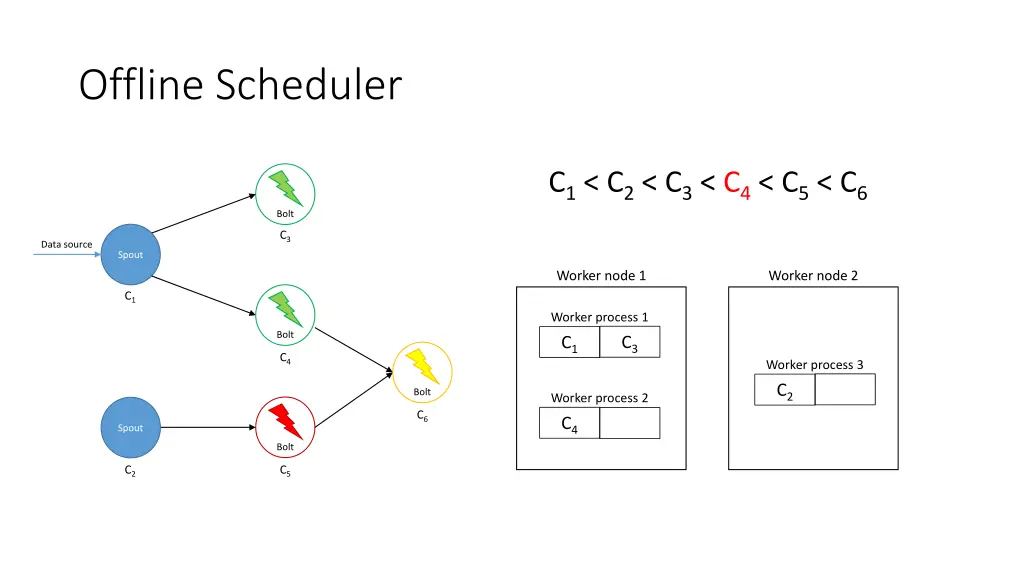
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C5 C2 Bolt Worker process 2 C6 C4 Spout Bolt C2 C5
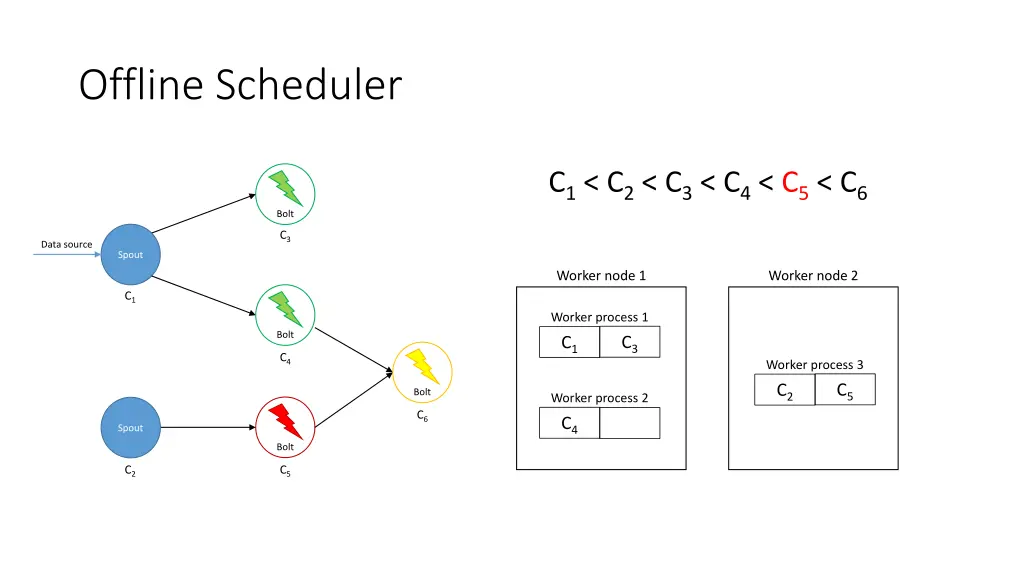
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C5 C2 Bolt Worker process 2 C6 C4 C6 Spout Bolt C2 C5
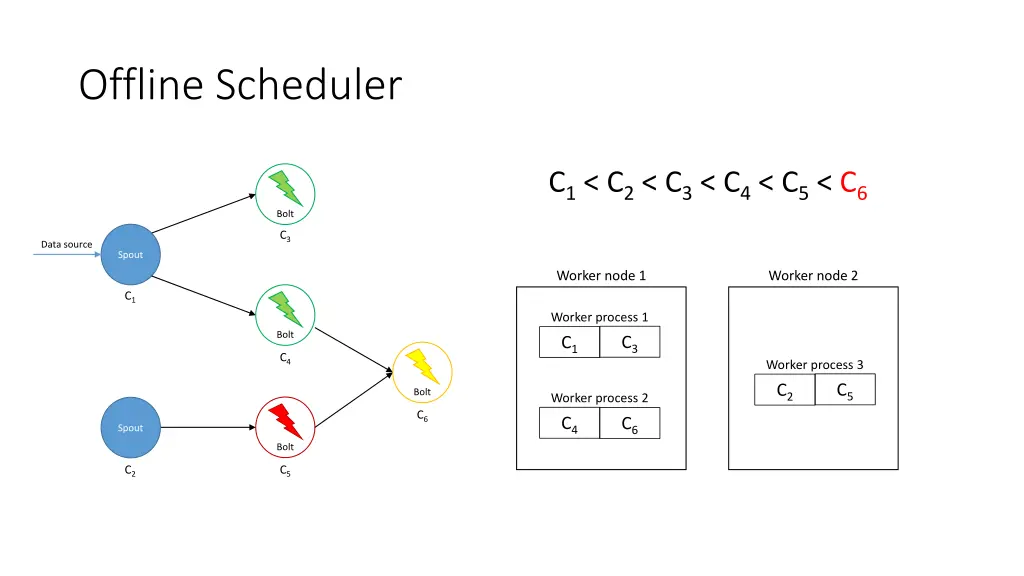
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C5 C2 Bolt Worker process 2 C6 C4 C6 Spout Bolt C2 C5
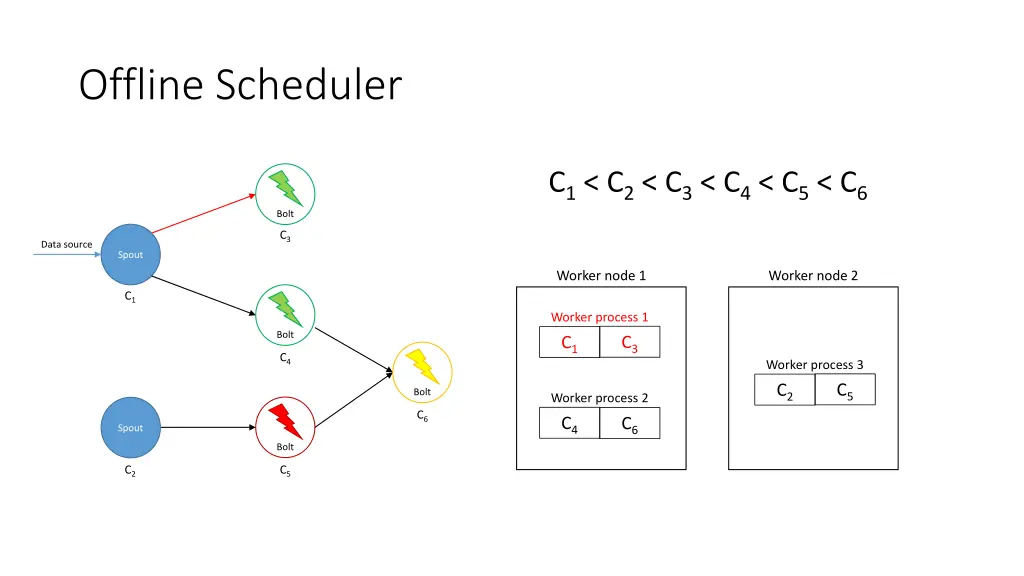
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C5 C2 Bolt Worker process 2 C6 C4 C6 Spout Bolt C2 C5
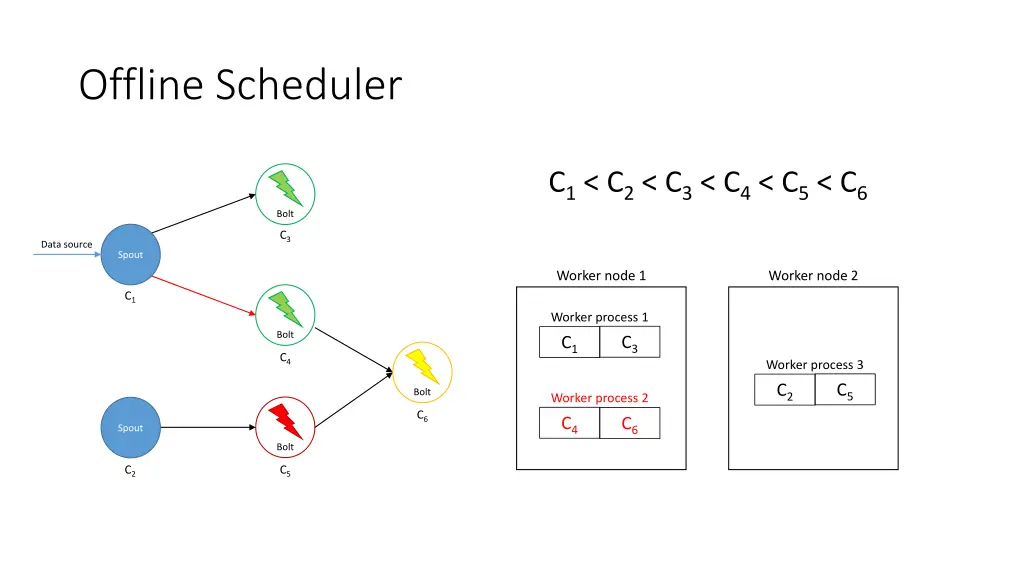
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C5 C2 Bolt Worker process 2 C6 C4 C6 Spout Bolt C2 C5
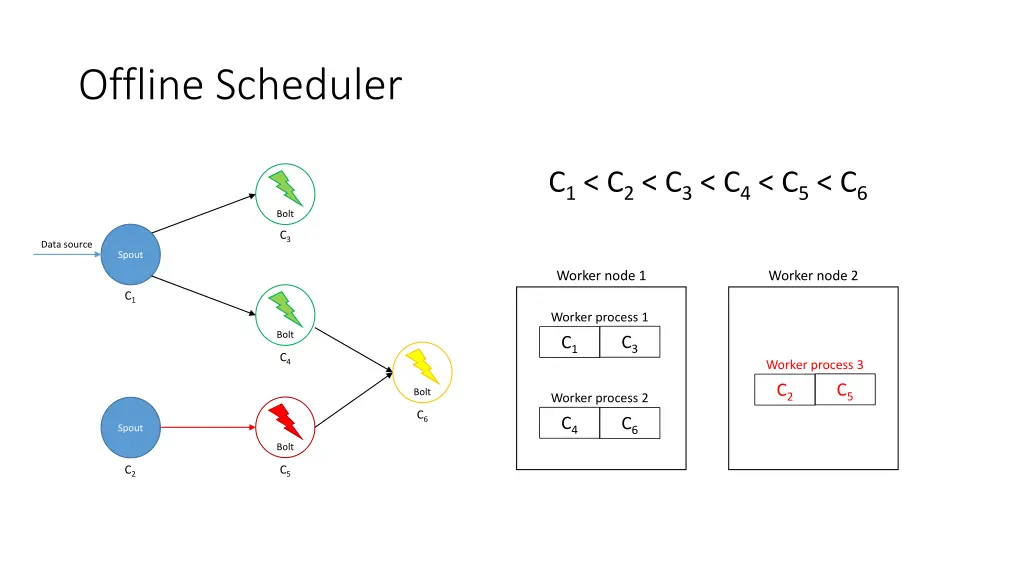
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C5 C2 Bolt Worker process 2 C6 C4 C6 Spout Bolt C2 C5
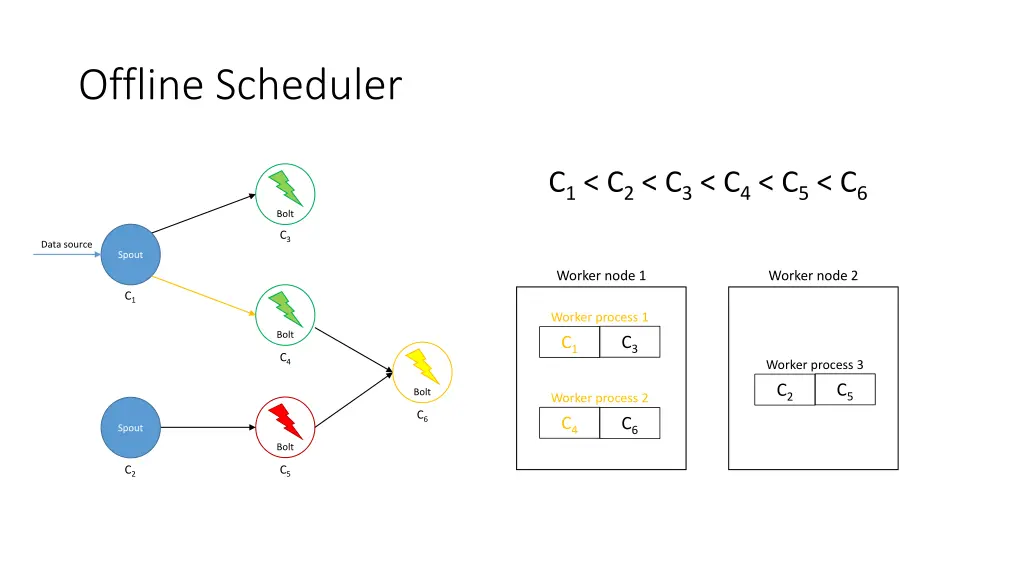
Offline Scheduler C1< C2< C3< C4< C5< C6 Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 1 Bolt C3 C1 C4 Worker process 3 C5 C2 Bolt Worker process 2 C6 C4 C6 Spout Bolt C2 C5
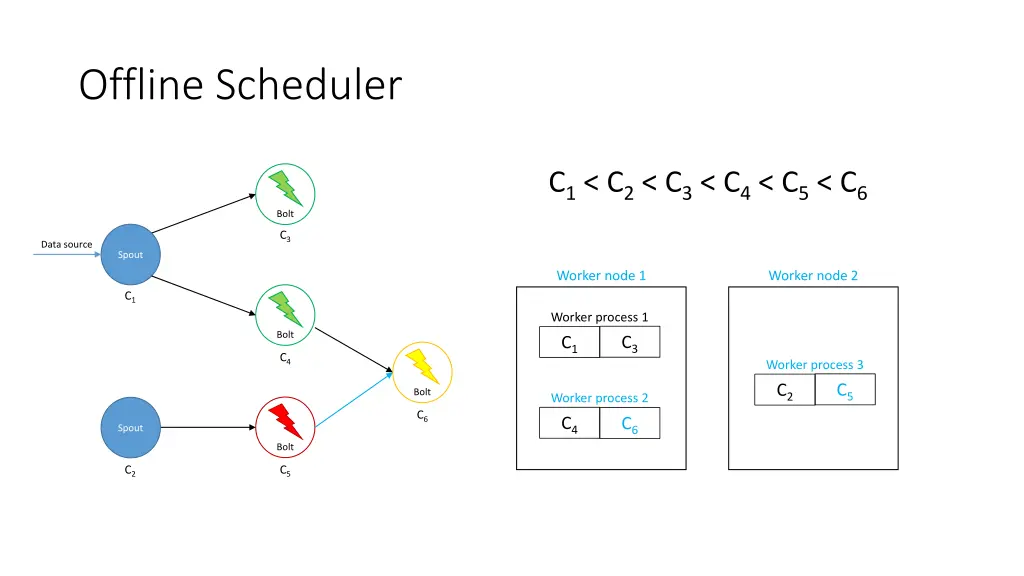
-

Online Scheduler • Goal: dynamically adapt scheduler as load on nodes changes • Need to satisfy constraints on: 1. Number of workers for each topology 2. Number of slots available on each worker node 3. Computational power on each node

Storm Architecture with Online Scheduler Worker Process Executor Supervisor Topology G(V, T), w Scheduler Plugin Plugin Scheduler Performance Log S Slots Deployment Plan Worker nodes Nimbus
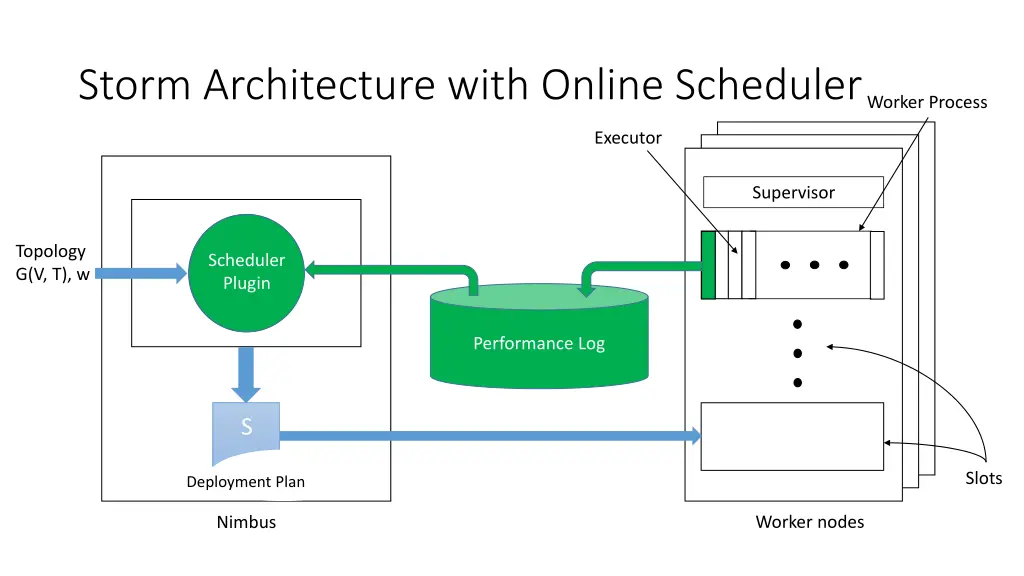
Online Scheduler I. Partition the executors among the workers 1. Iterate over all pairs of communicating executors (most traffic first) 2. If neither executor has been assigned, assign both to least loaded worker 3. Otherwise determine the best assignment using executors’ current workers and least loaded worker II. Allocate workers to available slots 1. Iterate over all pairs of communicating workers (most traffic first) 2. If neither worker has been assigned, assign both to least loaded node 3. Otherwise determine the best assignment using workers’ current nodes and least loaded nodes

Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] Bolt C3 Data source Spout C1 Worker process 1 Worker process 3 Bolt C3 C5 C1 C2 C4 Bolt Worker process 4 Worker process 2 C6 C4 C6 Spout Bolt C2 C5 Phase I
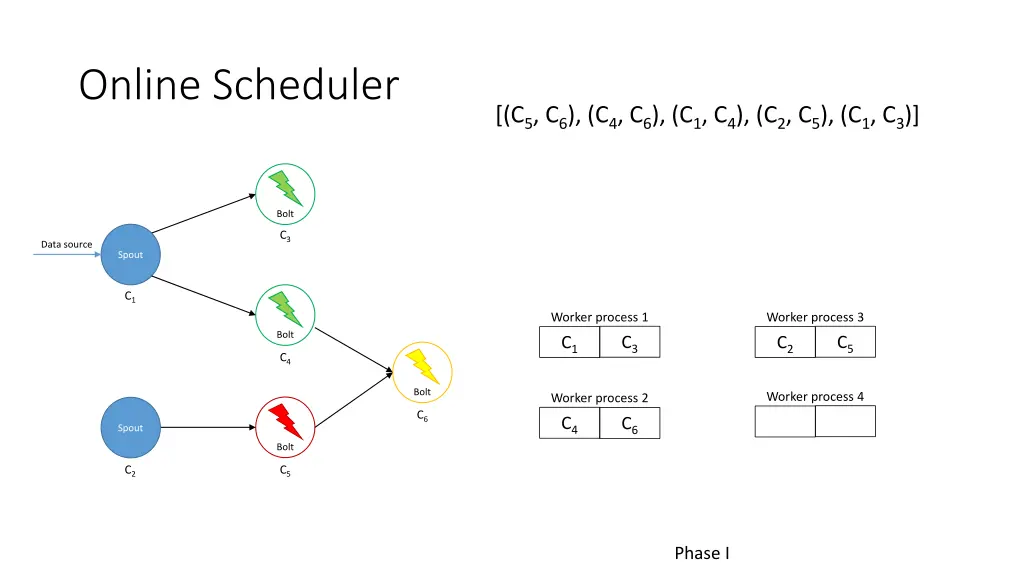
Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] (Least loaded worker) Worker process 2 Worker process 3 Worker process 4 C5 C4 C2 C6 Bolt C3 Data source Spout C1 Worker process 1 Worker process 3 Bolt C3 C5 C1 C2 C4 Bolt Worker process 4 Worker process 2 C6 C4 C6 Spout Bolt C2 C5 Phase I
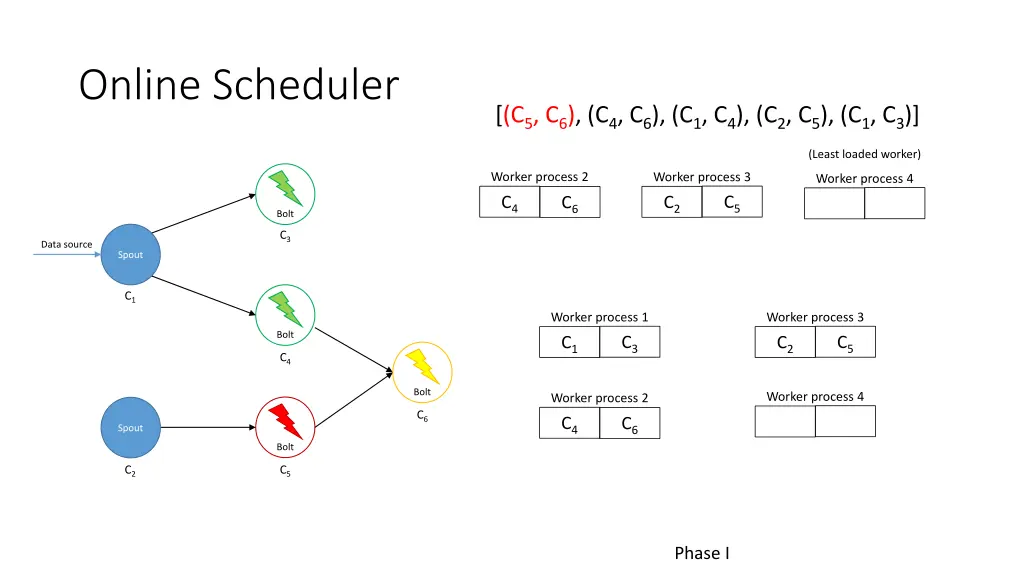
Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] (Least loaded worker) Worker process 2 Worker process 3 Worker process 4 C4 C2 C6 C5 Bolt C3 Data source Spout C1 Worker process 1 Worker process 3 Bolt C3 C1 C2 C4 Bolt Worker process 4 Worker process 2 C6 C6 C5 C4 Spout Bolt C2 C5 Phase I
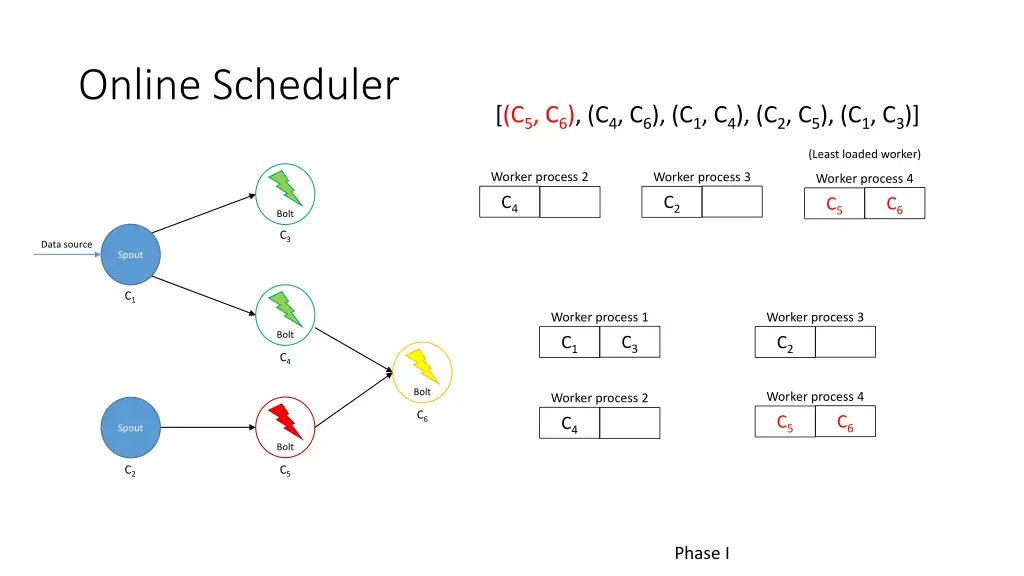
Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] (Least loaded worker) Worker process 2 Worker process 4 Worker process 3 C6 C4 C5 C2 Bolt C3 Data source Spout C1 Worker process 1 Worker process 3 Bolt C3 C1 C2 C4 Bolt Worker process 4 Worker process 2 C6 C6 C5 C4 Spout Bolt C2 C5 Phase I
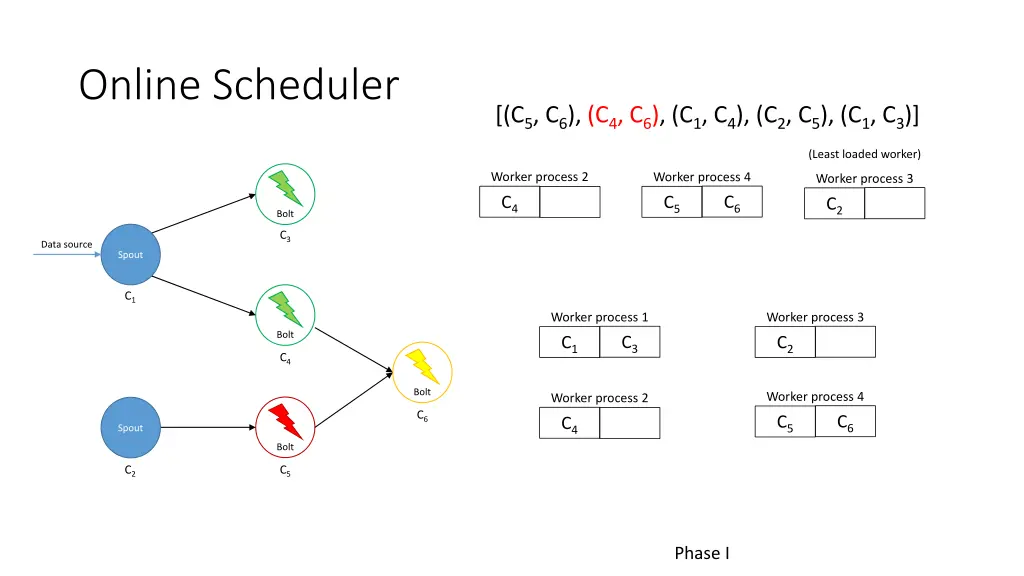
Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] (Least loaded worker) Worker process 1 Worker process 2 Worker process 3 C1 C4 C3 C2 Bolt C3 Data source Spout C1 Worker process 1 Worker process 3 Bolt C3 C1 C2 C4 Bolt Worker process 4 Worker process 2 C6 C6 C5 C4 Spout Bolt C2 C5 Phase I
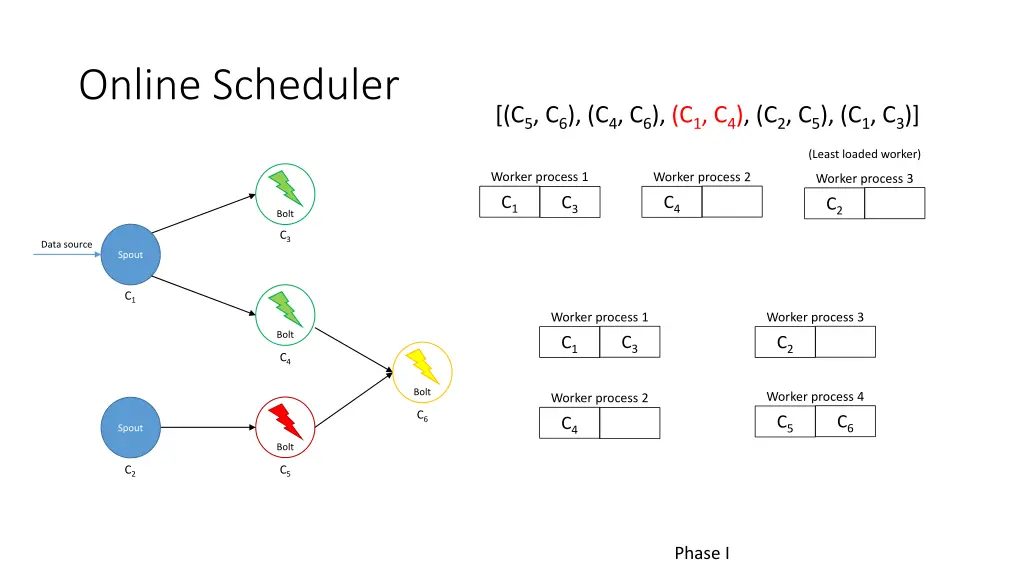
Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] (Least loaded worker) Worker process 1 Worker process 2 Worker process 3 C1 C4 C3 C2 Bolt C3 Data source Spout C1 Worker process 1 Worker process 3 Bolt C3 C2 C4 Bolt Worker process 4 Worker process 2 C6 C6 C5 C4 C1 Spout Bolt C2 C5 Phase I
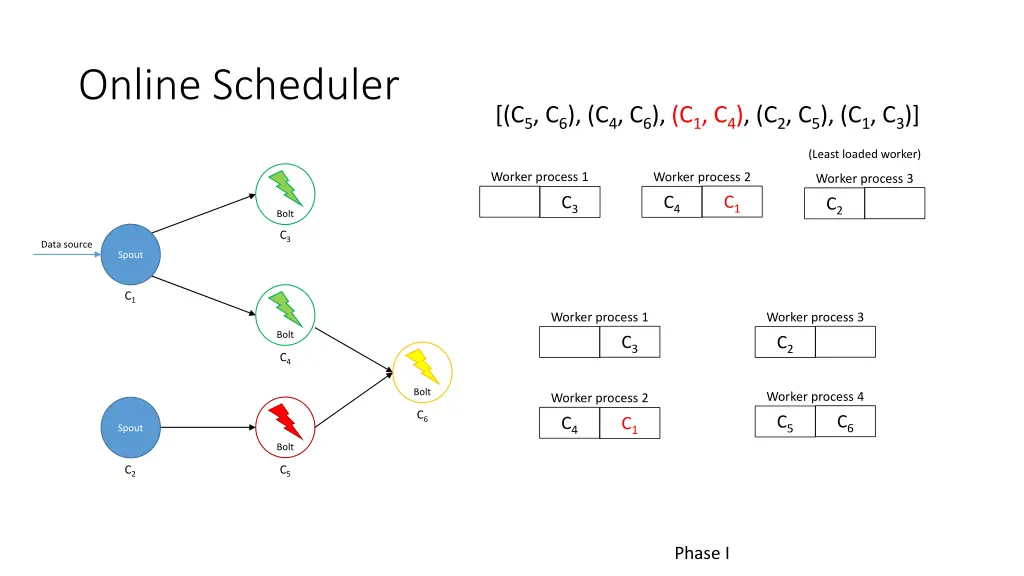
Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] (Least loaded worker) Worker process 4 Worker process 3 C6 C2 C5 Bolt C3 Data source Spout C1 Worker process 1 Worker process 3 Bolt C3 C2 C4 Bolt Worker process 4 Worker process 2 C6 C6 C5 C4 C1 Spout Bolt C2 C5 Phase I
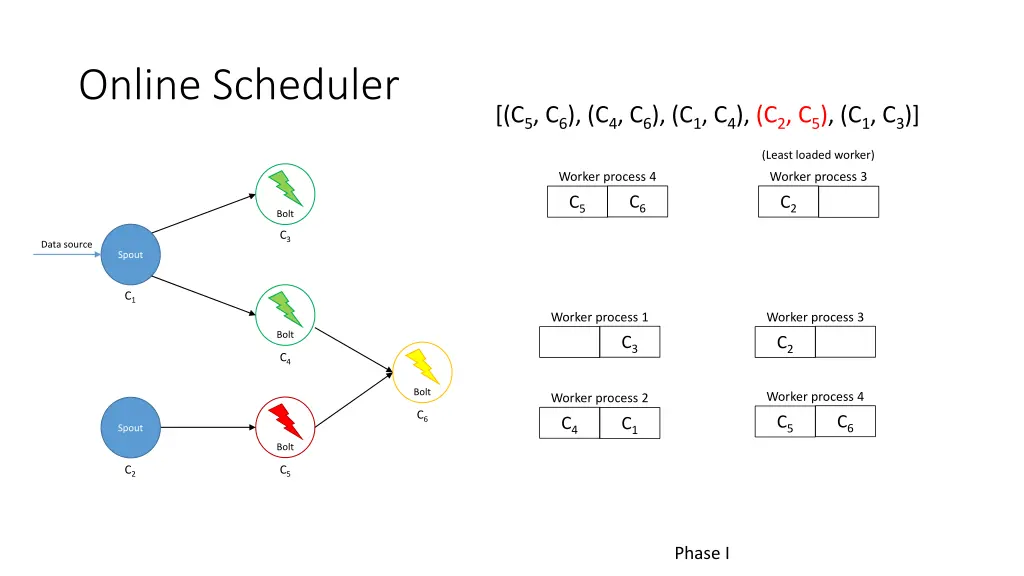
Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] (Least loaded worker) Worker process 2 Worker process 1 C1 C3 C4 Bolt C3 Data source Spout C1 Worker process 1 Worker process 3 Bolt C3 C2 C4 Bolt Worker process 4 Worker process 2 C6 C6 C5 C4 C1 Spout Bolt C2 C5 Phase I
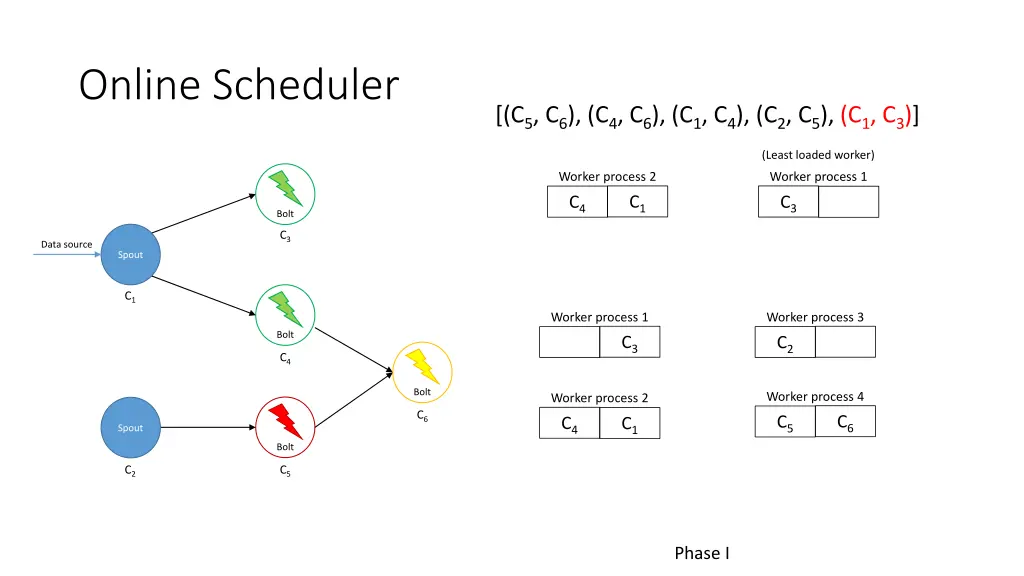
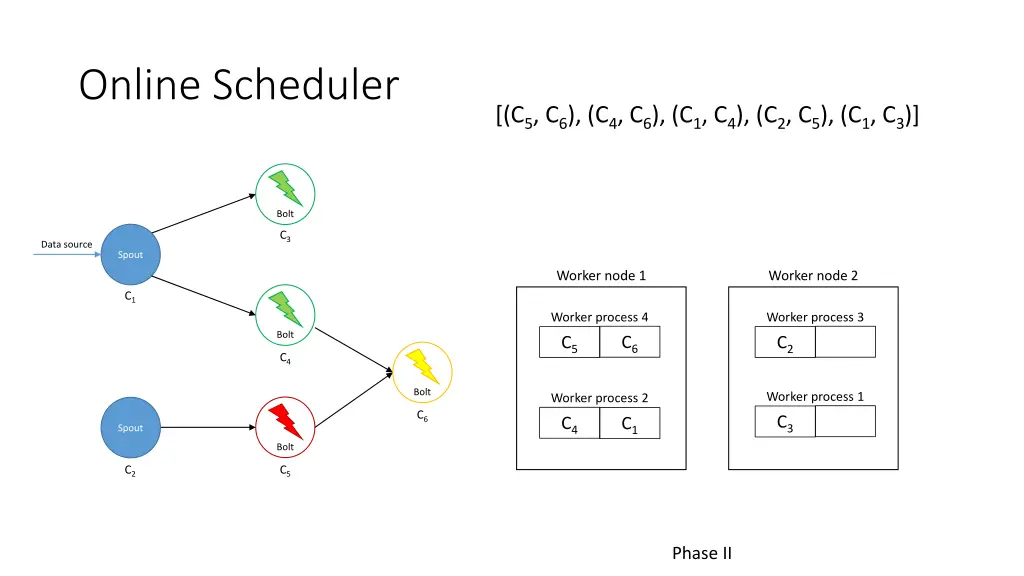
Online Scheduler [(C5, C6), (C4, C6), (C1, C4), (C2, C5), (C1, C3)] Bolt C3 Data source Spout Worker node 1 Worker node 2 C1 Worker process 4 Worker process 3 Bolt C6 C5 C2 C4 Bolt Worker process 1 Worker process 2 C6 C3 C4 C1 Spout Bolt C2 C5 Phase II
-

Evaluation • Topologies • General-case reference topology • DEBS 2013* Grand Challenge dataset • Key metrics • Average latency for event to traverse the entire topology • Average inter-node traffic at runtime • Cluster specifications • 8 worker nodes, each with: • 5 worker slots • Ubuntu 12.04 • 2x2.8 GHz CPUs • 3 GB RAM • 15 GB disk storage *The 7th ACM International Conference on Distributed Event-Based Systems

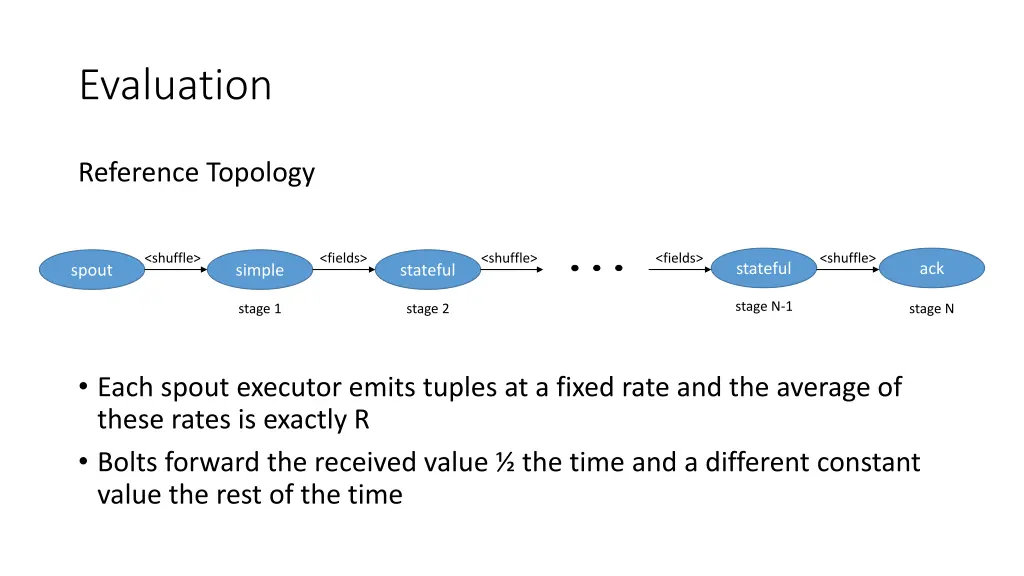
Evaluation Reference Topology <shuffle> <fields> <shuffle> <fields> <shuffle> stateful ack spout simple stateful stage N-1 stage 1 stage 2 stage N • Each spout executor emits tuples at a fixed rate and the average of these rates is exactly R • Bolts forward the received value ½ the time and a different constant value the rest of the time
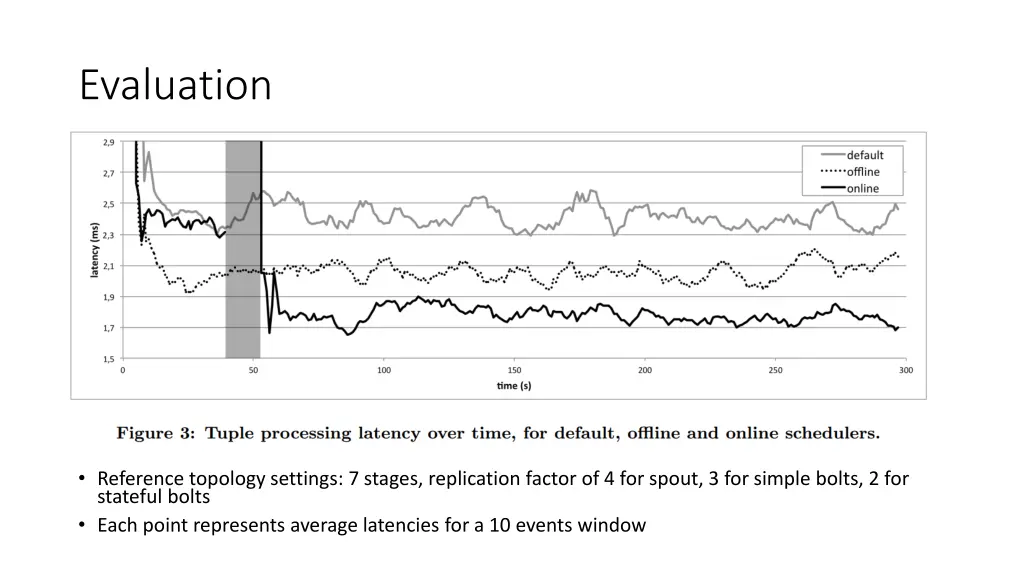
Evaluation • Reference topology settings: 7 stages, replication factor of 4 for spout, 3 for simple bolts, 2 for stateful bolts • Each point represents average latencies for a 10 events window
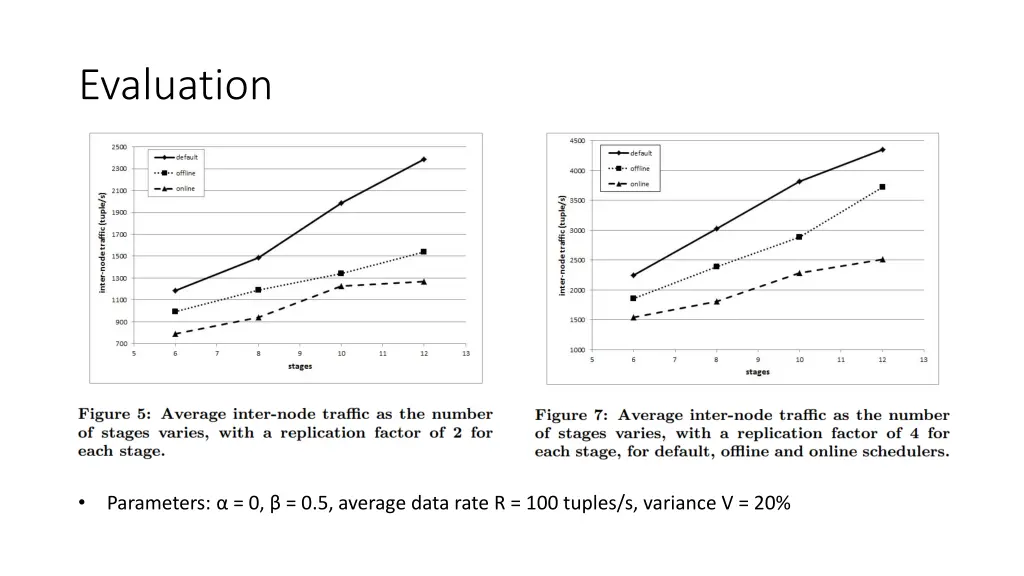
Evaluation • Parameters: α = 0, β = 0.5, average data rate R = 100 tuples/s, variance V = 20%
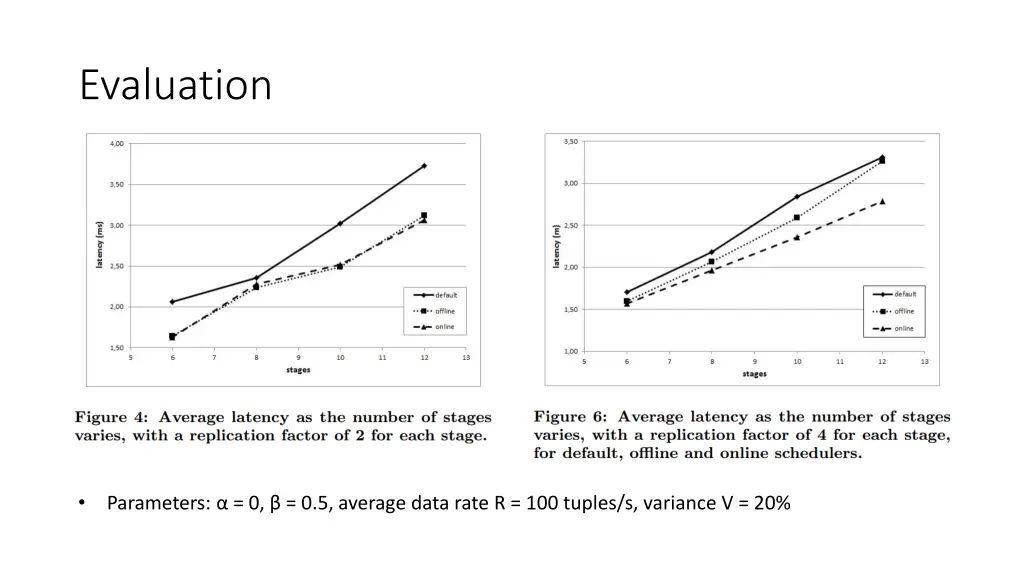
Evaluation • Parameters: α = 0, β = 0.5, average data rate R = 100 tuples/s, variance V = 20%
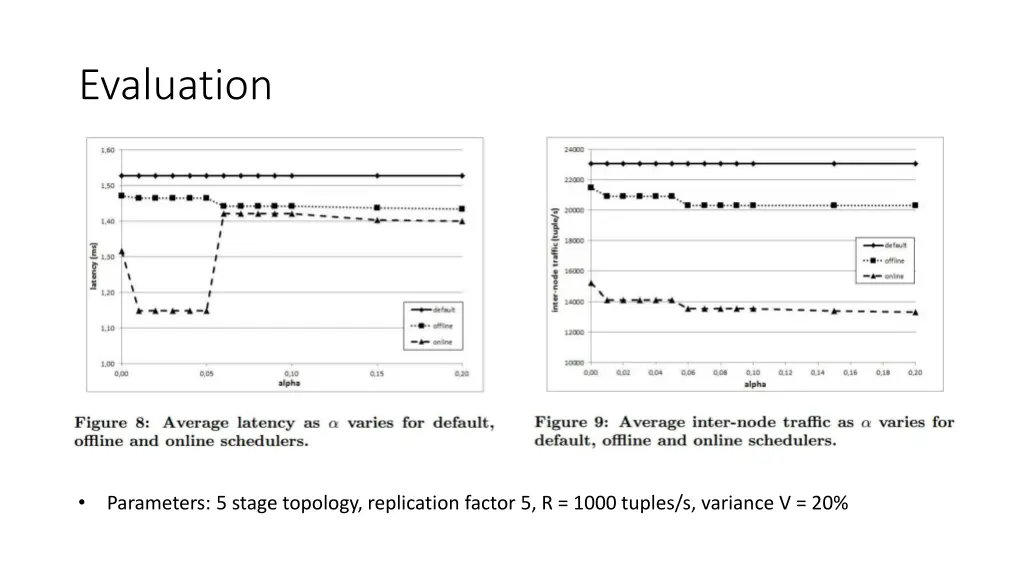
Evaluation • Parameters: 5 stage topology, replication factor 5, R = 1000 tuples/s, variance V = 20%
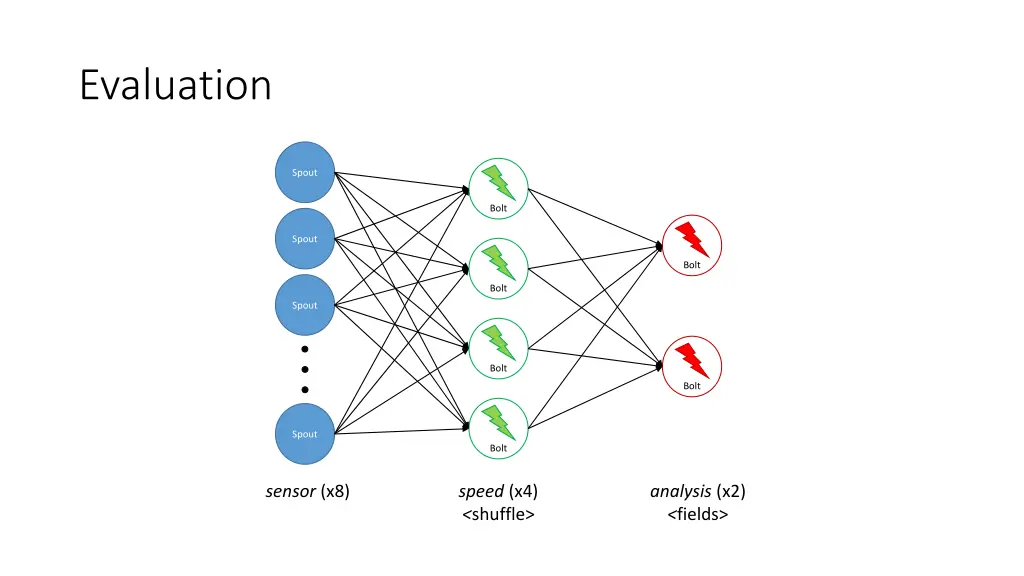
Evaluation • 2013 DEBS Grand Challenge • sensors in soccer players’ shoes emit position and speed data at 200 Hz frequency • goal is to maintain up-to-date statistics such as average speed, walked distance, etc. • Grand Challenge Topology • spout for the sensors (sensor) • bolt that computes instantaneous speed and receives tuples by shuffle grouping (speed) • bolt that maintains and updates statistics as tuples are received from the speed bolt (analysis)

Evaluation Spout Bolt Spout Bolt Bolt Spout Bolt Bolt Spout Bolt sensor (x8) speed (x4) <shuffle> analysis (x2) <fields>
-
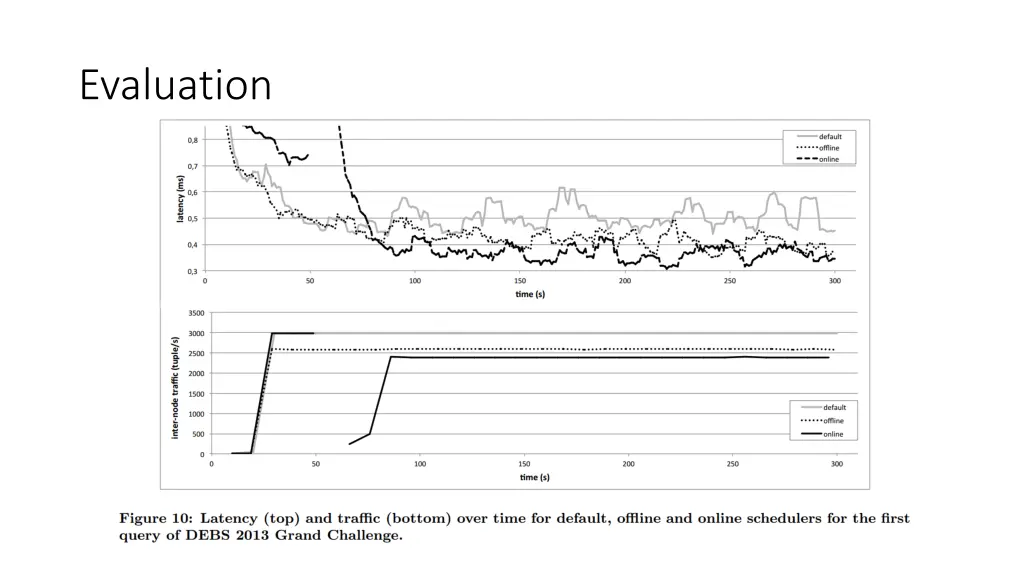
-