Download
1 / 12
120 likes | 201 Views
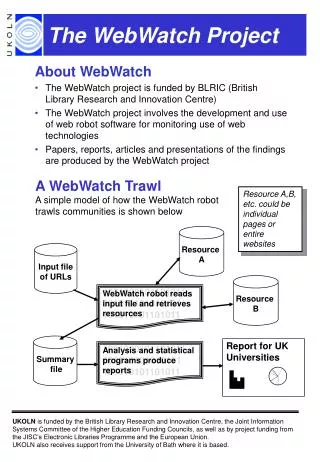
1001000101101011 001010101010101 101010101101011. Analysis and statistical programs produce reports. Report for UK Universities. The WebWatch Project. About WebWatch The WebWatch project is funded by BLRIC (British Library Research and Innovation Centre)

E N D
1001000101101011001010101010101101010101101011 Analysis and statistical programs produce reports Report for UK Universities The WebWatch Project • About WebWatch • The WebWatch project is funded by BLRIC (British Library Research and Innovation Centre) • The WebWatch project involves the development and use of web robot software for monitoring use of web technologies • Papers, reports, articles and presentations of the findings are produced by the WebWatch project A WebWatch Trawl A simple model of how the WebWatch robot trawls communities is shown below Resource A,B, etc. could beindividual pages or entire websites Resource A Input fileof URLs Resource B 1001000101101011001010101010101101010101101011 WebWatch robot reads input file and retrieves resources Summary file UKOLN is funded by the British Library Research and Innovation Centre, the Joint Information Systems Committee of the Higher Education Funding Councils, as well as by project funding from the JISC’s Electronic Libraries Programme and the European Union. UKOLN also receives support from the University of Bath where it is based.
WebWatch Trawl of UK University Entry Pages Background The WebWatch project carried out a trawl of UK University entry points on 24 October 1997. The trawl was repeated in 31 July 1998. Web Servers The most popular web server was Apache. This has grown in popularity, with a decline in the CERN, NCSA and other smaller servers. Microsoft's IIS server has also grown in popularity, perhaps indicating growth in use of Windows NT. Size of Entry Points The file size of HTML resource(s) (including frame sets) and images (but excluding background images) were analysed. Four pages were less than 5 Kb. The largest page was 193Kb. The largest pages contained animated GIF images.
WebWatch Trawl of UK University Entry Pages Web Technologies An analysis of some of the technologies used in UK University entry points is given below. Liverpool University is probably the only university entry page using Java Java and JavaScript None of the institutions trawled made use of Java. Subsequently it was found that one institution used Java. This institution used the Robot Exclusion Protocol to stop robots from trawling the site. Java provides this scrolling news facility JavaScript In October 1997 22 institutions used client-side scripting, such as JavaScript. By July 1998 38 institutions were using JavaScript. The University of Northumbria at Newcastle is one of about 38 institutions which use JavaScript. JavaScript is used to display picture fragments when the cursor moves over a menu option.
WebWatch Trawl of UK University Entry Pages Metadata In October 1997 54 institutions used "Alta Vista" type metadata on their main entry point. By July 1998 the metadata was used on 74 entry points. In contrast Dublin Core metadata was used on only 2 pages on both occasions. <META NAME="description" CONTENT="Mailbase is a national mailing list centre for UK HE"> <META NAME="keywords" CONTENT="mail", "listserve"> <META NAME="DC.Title" CONTENT="The Mailbase Home Page"> <META NAME="DC.Creator" CONTENT="John Smith"> Possible Use of Alta Vista and Dublin Core Metadata Cachability Interest in cache-friendly web resources has grown since the introduction of network charging on 1 August 1998. Over 50% of institutional HTML resources were found to be cachable, with only 1% not cachable. Further analyses is needed for the other resources. % telnet www.ukoln.ac.uk:80 GET / HTTP/1.0 HTTP/1.1 200 OK Date: Fri, 28 Aug 1998 16:22:51 GMT Server: Apache/1.2b8 Content-Type: text/html Telnet can be used to analyse HTTP headers, including caching information http://www.ukoln.ac.uk/ URL: • This resource uses HTTP/1.1. • The resource is cachable. • The resource was last updated on … A WebWatch service is being developed to provide a web-interface to the telnet command, to give more helpful information. Possible Interface
WebWatch Trawl of UK University Entry Pages • Frames • In July 1998 the following 19 sites used frames, compared with 12 in October 1997: • Essex • Bretton Coll. • UCE • Royal College of Music • Keele • King Alfred's Coll. • Middlesex • Nottingham Trent • Portsmouth • Ravensbourne Coll. • Teeside • Birkbeck Coll. • UMIST • Uni. Coll. Of St Martin • Thames Valley • Queen Margaret Coll. • Westhill • Scottish Agricultural Coll. • Kent Institute of Art and Design UMIST is an example of a framed website Liverpool University also uses frames but this was not detected by the robot due to their use of the Robot Exclusion Protocol. "Splash Screens" In July 1998 5 sites used client-side requests to provide redirects or "splash screens". "Splash screens" are created by <META HTTP-EQUIV="refresh" CONTENT="n; URL=xxx.html"> De Montfort University displays a screen with a yellow background. After 8 seconds a new screen is displayed.
WebWatch Trawl of UK University Entry Pages Hyperlinking Issues The WebWatch trawls revealed some interesting hyperlinking issues, which are described below. Numbers of Hyperlinks The histogram of the numbers of hyperlinks from institutional entry points shows an approximately normal distribution. Six sites were found to have fewer than 5 links. One site contained over 75 links. • Limitations of Survey • The analyses do not give a completely accurate view for a variety of reasons: • The address of one of the sites with a small number of links was incorrectly given in the input file list (obtained from HESA). • The analysis did not exclude duplicate links. • Sites containing "splash screens" were reported as having small number of links, although arguably the links on the second screen should also be included. • Discussion • Many Links: • Provide useful "short cuts" for experienced users • Can minimise numbers of levels to navigate • Few Links: • Can be confusing for new user • Can cause accessibility problems (e.g. for the visually impaired) • What is your view?
Trends in UK University Entry Points Trawls of UK University Entry Points The WebWatch project has surveyed UK University web site entry points on three occasions: 24 October 1997, 31 July 1998 and 25 November 1998. A summary of significant trends is given below. Server Usage The Apache and Microsoft web servers are both growing in popularity, at the expense of the CERN and Netscape servers, and a number of more specialist servers. "Splash Screens" The number of entry points using "splash" screen has increased from 5 (Oct 97), to 7 (Jul 98) to 10 (Nov 98). Metadata Usage Use of Dublin Core (DC) metadata grew during the summer 1998 from 2 sites to 11. DC metadata is still dwarfed by "Alta Vista" style metadata. Growth (Kb) Size Of Entry Points Trends in the sizes (HTML plus embedded images) have been analysed. The majority of entry points have not changed in size significantly, although one or two have grown (~ 100Kb) or decreased in size (~50Kb) substantially.
WebWatch Services WebWatch provides access to various tools and utilities which have been developed to support its work. These services can be accessed using a Web browser at the address <URL: http://www.ukoln.ac.uk/web-focus/webwatch/services/ >. HTTP-info Service A web form is available which can be used to obtain the HTTP headers sent when the resource is accessed. This service can be useful for getting information, such as the name of the server software, HTTP version information, etc. Doc-info Service A web form is available which can be used to obtain information on web resources. The Doc-info service is integrated with the HTTP-info service, enabled the HTTP headers are all objects contained in a resource to be analysed.
WebWatch Technologies • Technologies • The WebWatch project has made use of the following technologies: • The Harvest indexing and analysis suite • Perl for developing the WebWatch robot • Locally-developed indexing and analysis software • A series of Unix Perl utilities for analysis and filtering the data • Excel, Minitab and SPSS for statistical analysis Trawling Software The Harvest software was used originally. Harvest is widely used within the research community for indexing resources. For example the ACDC project uses Harvest to provide a distributed index of UK.AC web resources. Unfortunately as Harvest was designed for indexing, it is limited in its ability to audit and monitor web technologies. The current version of the WebWatch robot uses Perl. ACDC uses Harvest. See <URL: http://acdc.hensa.ac.uk/>
Restricting Access • Why Restrict Access? • Administrators may wish to restrict access by automated robot software to web resources for a variety of reasons: • To prevent resources from being indexed • To minimise load on the web server • To minimise network load • Robot Exclusion Protocol • The Robot Exclusion Protocolis a set of rules which robot software should obey. • A robots.txt file located in the root of the web server can contain information on: • Areas which robots should not access • Particular robots which are not allowed access User-agent: * Disallow: /images/ Disallow: /cgi-bin/ Typical robots.txt File • Issues • Some issues to be aware of: • Prohibiting robots will mean that web resources will not be found on search engines such as Alta Vista • Restricting access to the main search engine robots may mean that valuable new services cannot access the resources • The existence of a small robots.txt file can have performance benefits • It may be desirable to restrict access to certain areas, such as cgi-bin and images directories. WebWatch Hosts A robots.txt Checker Service
WebWatch Recommendations Recommendations The final WebWatch report makes a number of recommendations, based on its trawls, including advice for Information Providers, Web Administrators and Robot Software Developers • Information Providers • Directory Structure • Directory structures can provide a form of metadata about a resource. It is recommended the information providers make consistent use of directories. • Metadata • The use of "Alta Vista" type metadata is recommended for use on key entry points. • Frames • Frames can prevent indexing robots from accessing resources. If frames are used, there should be an alternative route to resources for robots. • System Administrators • The robots.txt File • Web system administrators should ensure that web servers contain a robots.txt file. This may be used to restrict access to robots. • HTTP/1.1 • Web system administrators should ensure that their server software supports HTTP/1.1. • Analysis of Robot Usage • Web system administrators should periodically check log files for access by robot software. • Software Developers • Memory Leaks • Memory leaks can cause problems, especially when accessing large nos. of resources. Robot software should include checkpoints, to facilitate restarts. • User-Agent Negotiation • Robot developers should be aware of server use of "User-Agent Negotiation" which may provide different information to robots and browsers. Further Information Further recommendations are included in the final WebWatch report. The report is available at <URL: http://www.ukoln.ac.uk/web-focus/webwatch/reports/final/ >.
Finding Out More About WebWatch • Ariadne • Occasional WebWatch reports are published in the online version of the Ariadne magazine. • See: • <URL: http://www.ariadne.ac.uk/issue12/web-focus/ > • <URL: http://www.ariadne.ac.uk/issue15/robots/ > • Publications • The following WebWatch articles have been published: • "Robot Seeks Public Library Web Sites" in LA Record, Dec 1997 Vol 99 (12) • "Academic and Public Library Web Sites" inLibrary Technology, Aug 1998 • "WebWatching Academic Library Web Sites" inLibrary Technology, Jun 1998 • "WebWatching Public Library Web Site Entry Points" inLibrary Technology, Apr 1998 • "Public Library Domain Names" inLibrary Technology, Feb 1998 • "How is My Web Community Doing? Monitoring Trends In Web Service Provision" in Journal Of Documentation, Vol. 55 No. 1 Jan 1999 WebWatch Staff The WebWatch Officer is Ian Peacock (email I.Peacock@ukoln.ac.uk). Ian's responsibilities include software development, running the robot trawls, analysing the data and producing reports. The WebWatch project is managed by Brian Kelly (email B.Kelly@ukoln.ac.uk). The final WebWatch report can be obtained from <URL:http://www.ukoln.ac.uk/web-focus/webwatch/reports/final/>