
Multiplication
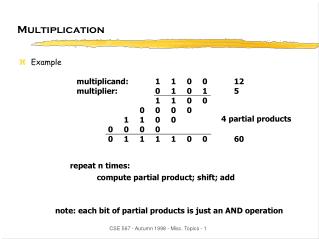
Multiplication. Example. multiplicand: 1 1 0 0 12 multiplier: 0 1 0 1 5 1 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 1 1 1 0 0 60. 4 partial products. repeat n times:. compute partial product; shift; add. note: each bit of partial products is just an AND operation. z = 0;

Multiplication
E N D
Presentation Transcript
Multiplication • Example multiplicand: 1 1 0 0 12multiplier: 0 1 0 1 5 1 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 1 1 1 1 0 0 60 4 partial products repeat n times: compute partial product; shift; add note: each bit of partial products is just an AND operation CSE 567 - Autumn 1998 - Misc. Topics - 1
z = 0; • repeat n • if (x[0]) z = z + y; • x = x >> 1; y = y << 1; Sequential Multiplier one bit of multiplier applied each cycle multiplicand y 0 x multiplier 2n bit adder adder z result CSE 567 - Autumn 1998 - Misc. Topics - 2
z = 0; • repeat n • if (x[0]) z = z + y * 2n; • x = x >> 1; z = z >> 1; Sequential Multiplier (cont’d) one bit of multiplier applied each cycle multiplicand y x multiplier adder n-bit adder z result CSE 567 - Autumn 1998 - Misc. Topics - 3
Parallelism in hardware • Fine-grained - bit level • e.g., carry-select, carry-lookahead adder • Pipelining • same number of functional units • different latency, but increased throughput • less work per clock cycle • Coarse-grained - data-path level • e.g., multiple arithmetic units • multi-port register files (read/write from different sources/destinations) • Processor level • difficult to take advantage of many levels of parallelismin fixed general-purpose processors • much easier when the processors are special-purpose,e.g., systolic computations CSE 567 - Autumn 1998 - Misc. Topics - 4
Bit level parallelism • Exploit ability to do necessary bit-level computations directly • exploit redundant logic • goal - keep all circuits busy, reduce critical path • Examples • carry-lookahead adder • carry-select adder • multipliers CSE 567 - Autumn 1998 - Misc. Topics - 5
multiplicand LSB 1 0 1 LSB 1 1 1 0 multplier 1 1 1 0 0 0 0 0 1 0 0 1 0 Combinational Multipliers • Use AND gates to generate all partial products in parallel CSE 567 - Autumn 1998 - Misc. Topics - 6
LSB 1 1 0 LSB 1 1 1 0 1 0 1 1 0 0 1 0 0 0 0 1 0 Combinational Multipliers (cont'd) • Skew array to send partial products along diagonal and make it square CSE 567 - Autumn 1998 - Misc. Topics - 7
B A LSB Full Adder Cout Cin LSB 0 0 0 0 S 0 0 Combinational Multipliers (cont'd) • Ripple-carry adder in each row (carries ripple right to left) • Sums ripple down (shifted one to right) worst-case delay is 3n CSE 567 - Autumn 1998 - Misc. Topics - 8
Using Carry-Save • Forward carries to next row of adders • CLA at the end to add last partial product and forwarded carries LSB 0 0 0 LSB 0 0 0 A B Cin Full Adder 0 Cout S 0 no need to optimize carry more than sum using CLA for final stage makes this fasterthan previous multiplier (worst-case is 2n) CLA CSE 567 - Autumn 1998 - Misc. Topics - 9
Combinational Multipliers (cont'd) • Carry-save adder is a 3-2 adder: partial products x2 x2 x2 x2 x2 x1 x1 x1 x1 x1 CSE 567 - Autumn 1998 - Misc. Topics - 10
PP1 PP2 PP3 PP4 PP5 PP6 PP7 PP8 PP0 + + + + + + + CLA Result Wallace Tree Multiplier • Use tree structure to reduce number of additions in critical path to O(logn) rather than O(n) • Difficult structure to layoutand integrate with partial product crossbar • Wiring constraints make it unattractive in many technologies CSE 567 - Autumn 1998 - Misc. Topics - 11
Binary Tree Multipliers • Problem with Wallace tree is 3:2 column reduction • need 2:1 reduction for binary tree • One solution: signed-digit binary trees • represent digits as 0, 1, -1 • similar to Booth's encoding 1 + 0 1 -1 0 1 x y if x>=0 and y>=0 otherwise 1 + 1 1 0 1 + -1 0 0 -1 + -1 -1 0 0 + 0 0 0 -1 + 0 0 -1 -1 1 x y if x>=0 and y>=0 otherwise CSE 567 - Autumn 1998 - Misc. Topics - 12
Booth's Algorithm • Take care of (retire) more than one bit per shift operation • Example: shift two bits at a time 0 0 1 1 0 1 13 1 1 1 0 1 0 –6 0 0 –1 1 –1 0 0 –1 –21 1 1 1 1 1 1 0 0 1 1 01 1 1 1 1 1 0 0 1 10 0 0 0 0 0 0 01 1 1 1 1 0 1 1 0 0 1 0 –78 Boothrecodingsteps i+1 i i-1 add 0 0 0 0*M0 0 1 1*M0 1 0 1*M0 1 1 2*M1 0 0 –2*M1 0 1 –1*M1 1 0 –1*M1 1 1 0*M must be able to add multiplier times 0, –1, –2, 1, and 2 Boothrecodingtable CSE 567 - Autumn 1998 - Misc. Topics - 13
Register Transfer • Registers have input and output • output can be fanned out to many destinations • input can come from many sources • multiplexer needed on input to select which inputs from other registers controlsignalsto choose inputsource input input output output outputs to other registers CSE 567 - Autumn 1998 - Misc. Topics - 14
Connecting Registers • Multiplexers: lots of control signals but full parallelism of transfers • Busses CSE 567 - Autumn 1998 - Misc. Topics - 15
Pipelining • Adding registers along a path • split combinational logic into multiple cycles • each cycle smaller than previously • Told Cold > Tnew Cnew • increase throughput CSE 567 - Autumn 1998 - Misc. Topics - 16
Pipelining • Delay, d, of slowest combinational stage determines performance • Throughput = 1/d – rate at which outputs are produced • Latency = n•d – number of stages * clock period • Pipelining increases circuit utilization • Registers slow down data, synchronize data paths • Wave-pipelining • no pipeline registers - waves of data flow through circuit • relies on equal-delay circuit paths - no short paths CSE 567 - Autumn 1998 - Misc. Topics - 17
When and How to Pipeline? • Where is the best place to add registers? • splitting combinational logic • overhead of registers (propagation delay and setup time requirements) • What about cycles in data path? • Example: 16-bit adder, add 8-bits in each of two cycles CSE 567 - Autumn 1998 - Misc. Topics - 18
Retiming • Process of optimally distributing registers throughout a circuit • minimize the clock period • minimize the number of registers CSE 567 - Autumn 1998 - Misc. Topics - 19
Retiming (cont’d) • Fast optimal algorithm (Leiserson & Saxe 1983) • Retiming rules: • remove one register from each input and add one to each output • remove one register from each output and add one to each input CSE 567 - Autumn 1998 - Misc. Topics - 20
10 13 7 8 6 5 10 13 7 8 6 5 Optimal Pipelining • Add registers - use retiming to find optimal location CSE 567 - Autumn 1998 - Misc. Topics - 21
Example - Digital Correlator • yt = d(xt, a0) + d(xt-1, a1) + d(xt-2, a2) + d(xt-3, a3) • d(xt, a0) = 0 if x a, 1 otherwise (and passes x along to the right) yt + + + host d d d d a0 a1 a2 a3 xt CSE 567 - Autumn 1998 - Misc. Topics - 22
+ + + host d d d d + + + host d d d d Example - Digital Correlator (cont’d) • Delays: adder, 7; comparator, 3; host, 0 cycle time = 24 cycle time = 13 CSE 567 - Autumn 1998 - Misc. Topics - 23
Pipelined Multipliers • Pipelining can be applied to any of the combinational multipliers + + + + + + + CLA CLA FF at every intersection of pipe state and wire CSE 567 - Autumn 1998 - Misc. Topics - 24
A H B L Example - Sorting Comparator Parallel Sorter CSE 567 - Autumn 1998 - Misc. Topics - 25
Example - Sorting (cont’d) • Pipelined CSE 567 - Autumn 1998 - Misc. Topics - 26
Pipelined Sorter (cont’d) CSE 567 - Autumn 1998 - Misc. Topics - 27
Better Sorter CSE 567 - Autumn 1998 - Misc. Topics - 28
Sequential Sorter CSE 567 - Autumn 1998 - Misc. Topics - 29
Systolic Arrays • Set of identical processing elements • specialized or programmable • Efficient nearest-neighbor interconnections (in 1-D, 2-D, other) • SIMD-like • Multiple data flows, converging to engage in computation Analogy: data flowing through the system in a rhythmic fashion – from main memory through a series of processing elements and back to main memory CSE 567 - Autumn 1998 - Misc. Topics - 30
Example - Convolution • yj = xjw1 + xj+1w2 + . . . + xj+n-1wn - x3 - x2 - x1 w4 w3 w1 w2 - - - y1 - y2 - y3 - y1 = x1w1 + x2w2 + x3w3 + x4w4 y2 = x2w1 + x3w2 + x4w3 + x5w4 y3 = x3w1 + x4w2 + x5w3 + x6w4 . . . . CSE 567 - Autumn 1998 - Misc. Topics - 31
Example - Convolution (cont’d) w4 w3 w2 w1 x6 – x5 – x4 – x3 – x2 – x1 – – – y1 – y2 – y3 x6 – x5 – x4 – x3 – x2 – x1 – – – y1 – y2 – y3 x6 – x5 – x4 – x3 – x2 – x1 – – – y1 – y2 – y3 x6 – x5 – x4 – x3 – x2 – x1 – – – y1 – y2 – y3 x6 – x5 – x4 – x3 – x2 – – – y1 – y2 – y3 x6 – x5 – x4 – x3 – x2 – y1 – y2 – y3 x6 – x5 – x4 – x3 – y1 – y2 – y3 x6 – x5 – x4 – x3 – y2 – y3 CSE 567 - Autumn 1998 - Misc. Topics - 32
c11 c12 c13 c14 c21 c22 c23 c24 c31 c32 c33 c34 c41 c42 c43 c44 Example: Matrix Multiplication • C = A B cij = k=1n aikbkj CSE 567 - Autumn 1998 - Misc. Topics - 33
Example: Matrix Multiplication |||b44 ||b43 b34 |b42 b33 b24 b41 b32 b23 b14 b31 b22 b13 | b21 b12 || b11 ||| c11 c12 c13 c14 c21 c22 c23 c24 c31 c32 c33 c34 c41 c42 c43 c44 – – – a14 a13 a12 a11 – – a24 a23 a22 a21 – – a34 a33 a32 a31 –– a44 a43 a42 a41 –––
Systolic Computers • Warp (CMU) - 1987 • linear array of 10 or more processing cells • optimized inter-cell communication for low-latency • pipelined cells and communication • conditional execution • compiler partitions problem into cells and generates microcode • i-Warp (Intel) - 1990 • successor to Warp • two-dimensional array • time-multiplexing of physical busses between cells • 32x32 array has 20Gflops peak performance CSE 567 - Autumn 1998 - Misc. Topics - 35





















