Download
1 / 28
280 likes | 313 Views
This review delves into the processes of DNA replication and repair, highlighting the importance of accurate base pairing, proofreading, and DNA mismatch repair in maintaining genetic stability. It also discusses the impact of mutations and their role in diseases like sickle cell anemia and cancer.

E N D
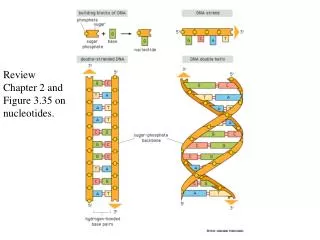
DNA double helix Anti-parallel complementary
Sequence of nucleotides in human beta-globin gene The DNA sequences highlighted in color show the three regions of the gene that specify the amino acid sequence. Not all of the DNA in genes is used to encode the proteins that they specify; much of the rest is concerned with determining when, and in what amounts, the protein encoded is made – regulatory regions of genes The complete set of information in an organisms’ DNA is its genome
Complementary base pairing allows each strand to act as a template, or mold for the synthesis of a new complementary strand.
DNA Replication Anti-parallel Copying must be carried out with speed and accuracy (8 hours in a dividing animal cell). Is carried out by a cluster of proteins that together form a “replication machine”
DNA replication is “semiconservative” because each daughter DNA double helix is composed of one conserved (old) strand and one newly synthesized strand
DNA double helix is very stable. Many hydrogen bonds, weak on their own, are very strong together. The process of replication is begun by initiator proteins that bind to the DNA and pry the two strands apart Replication origins are marked by a particular sequence of nucleotides that 1. bind to initiator proteins and 2. have stretches that are A-T rich. Why?
Bidirectional and move very fast – 1000 nucleotide pairs /sec
Pyrophosphate is then hydrolyzed – making polymerization irreversible Why? DNA polymerase adds nucleotides that are complementary to the template to the 3’ end by forming phosphodiester bonds between this end and the 5’-phosphate group of the incoming nucleotide.
DNA polymerase stays associated with the DNA, with the help of other molecules that are part of the complex,.and moves along it stepwise. DNA polymerase can only add nucleotides in one direction, at the 3’ end. Replication forks of all cells, procaryotic and eucaryotic have leading and lagging strands
DNA polymerase is self-correcting. It makes only about one error in ever 107 nucleotide pairs replicated, but this is too many for survival of an organism. Error-correcting activity is called proofreading. Before adding the next nucleotide, DNA polymerase checks the one it just added. If there is a mispaired nucleotide, it is removed using the nuclease activity. DNA polymerase has both 5’ – 3’ polymerization activity and 3’ – 5’ nuclease activity DNA polymerase can not start a new strand of DNA, it only elongates an existing strand.
If DNA polymerase could polymerize 3’ to 5’ it would lose its ability to proofread. Why?
DNA polymerase can not polymerize 3’ to 5’. It can not add nucleotides to the 5’ end and there is no DNA polymerase that can. DNA polymerase can not start a new strand of DNA. It can only elongate an existing strand. Therefore primers are required These are RNA not DNA since they are only temporary. This is done by a primase. Primerase can not proofread and leaves many mistakes. Primers are removed by nucleases that recognize RNA/DNA helices. This leaves a gap filled in by a DNA repair polymerase. And DNA ligase joins the nucleotides at the nick.. One primer is required for the leading strand. Multiple primers are needed for the lagging strand. Okazaki fragments
DNA helicase uses energy from ATP to speed along DNA, breaking the many hydrogen bonds and opening the double helix as it goes. • Single-stranded binding proteins keep the helix open and protect the single strand of DNA. • Sliding clamp keeps DNA polymerase firmly attached to DNA template by forming a ring around the DNA helix and binding DNA polymerase.
Theoretical multienzyme complex moves as a unit along the DNA. However, there is much we do not understand.
Sickle-cell anemia DNA Repair Rare beneficial DNA mutations (mistakes or damage) allow for evolution of organisms in the face of ever changing environments. However, in the short term, DNA mutations are almost always detrimental to an organism. Genetic stability is the result of the accuracy of DNA polymerase and the many mechanisms for proof-reading and DNA repair. When these processes fail, a permanent change in the DNA sequence occurs - mutation. Glutomic acid to valine at 6th position of 146 aa
Mutations in germ cells (reproductive cells) lead to genetic diseases like sickle-cell anemia. Somatic cells must also be protected from damage to the DNA. Gradual accumulation of mutations in the DNA of somatic cells can eventually lead to a lack of replication control and cancer - one cell grows uncontrollably. These mutations accumulate and cancer is more likely as we age.
DNA Mismatach Repair removes replication errors that escape from the replication machine. Corrects 99% of the replication errors. Accuracy is one in 107 base pairs. Mismatch repair proteins must excise (remove) the mismatched nucleotide from the new strand. How does the enzyme complex know which is which? The new strand may remain nicked for a short time, also old strands may have chemical modifications, such as methylation.
DNA mismatch repair proteins are thought to recognize (bind to) the distortion in the geometry of the DNA double helix resulting from an incorrect base pairing. They may recognize the correct (old) strand by occasional nicks (which would only be present for a short time after replication is complete.
Even though DNA is one of the most stable molecules, thermal collisions do sometimes cause changes - including depurination and deamination.
Ultraviolet radiation in sunlight damages DNA and promotes covalent linkage between two adjacent pyrimidine bases - forming thymine dimers. Many different repair enzymes exist to correct and repair the damage. When someone inherits a mutation in the gene responsible for producing one of the mismatch repair proteins, they may be predisposed to certain cancers.
1. There are a variety of enzymes that recognize and exise different types of DNA damage Step 2 and 3 are nearly the same for most types of DNA repair. Since the damaged strand usually has a distinct structure, different from normal DNA structure, it can be “recognized” by the DNA repair enzyme. And, because each strand is complementary to each other, there is a template to copy.
Single-celled organisms like yeast have more than 50 different proteins that function in DNA repair. Probably much more complex in humans. • Xeroderma pigmentosum is a genetic disease in which the gene for one of these DNA repair enzymes is mutated. Severe skin lesions, including cancer, are the result of an accumulation of thymine dimers in cells exposed to sunlight.
DNA is extremely stable. Changes accumulate slowly in the course of evolution, as evidenced by the degree of homology between many genes even in unrelated organisms like fruit flies and humans.