Download

1 / 32
330 likes | 537 Views
Chapter 2: A Simple One Pass Compiler. Prof. Steven A. Demurjian Computer Science & Engineering Department The University of Connecticut 371 Fairfield Way, Unit 2155 Storrs, CT 06269-3155. steve@engr.uconn.edu http://www.engr.uconn.edu/~steve (860) 486 - 4818.

E N D
Chapter 2: A Simple One Pass Compiler Prof. Steven A. Demurjian Computer Science & Engineering Department The University of Connecticut 371 Fairfield Way, Unit 2155 Storrs, CT 06269-3155 steve@engr.uconn.edu http://www.engr.uconn.edu/~steve (860) 486 - 4818 Material for course thanks to: Laurent Michel Aggelos Kiayias Robert LeBarre
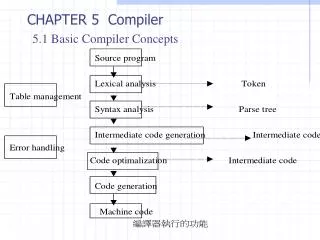
The Entire Compilation Process • Grammars for Syntax Definition • Syntax-Directed Translation • Parsing - Top Down & Predictive • Pulling Together the Pieces • The Lexical Analysis Process • Symbol Table Considerations • A Brief Look at Code Generation • Concluding Remarks/Looking Ahead
Grammars for Syntax Definition • A Context-free Grammar (CFG) Is Utilized to Describe the Syntactic Structure of a Language • A CFG Is Characterized By: • 1. A Set of Tokens or Terminal Symbols • 2. A Set of Non-terminals • 3. A Set of Production RulesEach Rule Has the FormNT {T, NT}* • 4. A Non-terminal Designated As the Start Symbol
Grammars for Syntax DefinitionExample CFG listlist + digit listlist - digit listdigit digit 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 (the “|” means OR) (So we could have written list list + digit | list - digit | digit )
Grammars are Used to Derive Strings: Using the CFG defined on the previous slide, we can derive the string: 9 - 5 + 2 as follows: listlist +digit list - digit + digit digit - digit + digit 9 - digit + digit 9 - 5 + digit 9 - 5 + 2 P1 : list list + digit P2 : listlist - digit P3 : listdigit P4 : digit 9 P4 : digit 5 P4 : digit 2
Grammars are Used to Derive Strings: list list digit + 2 - list digit 5 digit 9 This derivation could also be represented via a Parse Tree (parents on left, children on right) listlist +digit list - digit + digit digit - digit + digit 9 - digit + digit 9 - 5 + digit 9 - 5 + 2
A More Complex Grammar blockbeginopt_stmtsend opt_stmtsstmt_list | stmt_liststmt_list ; stmt | stmt What is this grammar for ? What does “” represent ? What kind of production rule is this ?
Defining a Parse Tree • More Formally, a Parse Tree for a CFG Has the Following Properties: • Root Is Labeled With the Start Symbol • Leaf Node Is a Token or • Interior Node (Now Leaf) Is a Non-Terminal • If A x1x2…xn, Then A Is an Interior; x1x2…xn Are Children of A and May Be Non-Terminals or Tokens
Other Important ConceptsAmbiguity string + string string string - - string string 2 string string 9 5 + 9 string string 5 2 Two derivations (Parse Trees) for the same token string. Grammar: stringstring + string | string – string | 0 | 1 | …| 9 Why is this a Problem ?
Other Important ConceptsAssociativity of Operators right list list right letter digit + + 2 a - - list right digit letter 5 b letter digit 9 c Left vs. Right rightletter = right | letter letter a | b | c | …| z
Other Important ConceptsOperator Precedence What does 9 + 5 * 2 mean? ( ) * / + - is precedence order Typically This can be incorporated into a grammar via rules: expr expr + term | expr – term | term termterm * factor | term / factor | factor factor digit | ( expr ) digit 0 | 1 | 2 | 3 | … | 9 Precedemce Achieved by: expr & term for each precedence level Rules for each are left recursiveorassociate to the left
Syntax-Directed Translation • Associate Attributes With Grammar Rules & Constructs and Translate As Parsing Occurs • Our Example Uses Infix to Postfix Notation Translation for Expressions • Translation May Be Defined Inductively As: Postfix(e), E is an Expression 1. If E is a variable | constant Postfix(E) = E 2. If E is E1 op E2 Postfix(E) = Postfix(E1 op E2) = Postfix(E1) Postfix(E2) op 3. If E is (E1) Postfix(E) = Postfix(E1) Examples: ( 9 – 5 ) + 2 9 5 – 2 + 9 – ( 5 + 2 ) 9 5 2 + -
Syntax-Directed Definition: (2 parts) expr expr – term | expr + term | term term 0 | 1 | 2 | 3 | … | 9 • Each Production Has a Set of Semantic Rules • Each Grammar Symbol Has a Set of Attributes • For the Following Example, String Attribute “t” is Associated With Each Grammar Symbol, i.e., • What is a Derivation for 9 + 5 - 2?
Syntax-Directed Definition: (2 parts) Production Semantic Rule expr expr + term expr.t := expr.t || term.t || ‘+’ expr expr – term expr.t := expr.t || term.t || ’-’ expr term expr.t := term.t term 0 term.t := ‘0’ term 1 term.t := ‘1’ …. …. term 9 term.t := ‘9’ • Each Production Rule of the CFG Has a Semantic Rule • Note: Semantic Rules for expr Use Synthesized Attributes Which Obtain Their Values From Other Rules.
Semantic Rules are Embedded in Parse Tree expr.t =95-2+ expr.t =95- term.t =2 expr.t =9 term.t =5 term.t =9 2 9 - 5 + • How Do Semantic Rules Work ? • What Type of Tree Traversal is Being Performed? • How Can We More Closely Associate Semantic Rules With Production Rules ?
Examples expr expr + term {print(‘+’)} expr - term {print(‘-’)} term term 0 {print(‘0’)} term 1{print(‘1’)} … term 9{print(‘9’)} expr {print(‘+’)} + expr term {print(‘-’)} 2 {print(‘2’)} - expr term 5 {print(‘5’)} term 9 {print(‘9’)} rest + term rest rest + term {print(‘+’)}rest (Print ‘+’ After term for postfix translation)
Top-Down Parsing Parse tree / derivation of a token string occurs in a top down fashion. For Example, Consider: Parsing – Top-Down & Predictive type simple | id | array [ simple ] oftype simple integer | char | num dotdot num Suppose input is : array [ num dotdot num ] of integer The parse would begin with type array [ simple ] of type
Top-Down Parse (type = start symbol) type array [ simple ] of type type array [ simple ] of type num dotdot num Input : array [ num dotdot num ] of integer Tokens
Top-Down Parse (type = start symbol) type array [ simple ] of type num dotdot num simple type array [ simple ] of type num dotdot num simple integer Input : array [ num dotdot num ] of integer
Top-Down ProcessRecursive Descent or Predictive Parsing • Parser Operates by Attempting to Match Tokens in the Input Stream • Utilize both Grammar and Input Below to Motivate Code for Algorithm array [ num dotdot num ] of integer type simple | id | array [ simple ] oftype simple integer | char | num dotdot num procedurematch ( t : token ) ; begin if lookahead = tthen lookahead : = nexttoken else error end ;
Top-Down Algorithm (Continued) procedure type ; begin if lookahead is in { integer, char, num } then simple else if lookahead = ‘’ then begin match (‘’ ) ; match( id ) end else if lookahead = array then begin match( array ); match(‘[‘); simple; match(‘]’); match(of); type end else error end ; procedure simple ; begin if lookahead = integer then match ( integer ); else if lookahead = char then match ( char ); else if lookahead = num then begin match (num); match (dotdot); match (num) end else error end ;
Problem with Top Down Parsing • Left Recursion in CFG May Cause Parser to Loop Forever • Solution: Algorithm to Remove Left Recursion expr expr + term | expr - term | term term 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 expr term rest rest + term rest | - term rest | term 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 * New Semantic Actions ! rest + term {print(‘+’)} rest | - term {print(‘-’)} rest |
Comparing Grammarswith Left Recursion expr {print(‘+’)} + expr term {print(‘-’)} {print(‘2’)} 2 expr term - {print(‘5’)} term 5 9 {print(‘9’)} • Notice Location of Semantic Actions in Tree • What is Order of Processing?
Comparing Grammarswithout Left Recursion expr term rest - term {print(‘-’)} rest 9 {print(‘9’)} + term {print(‘+’)} 5 {print(‘5’)} 2 {print(‘2’)} • Now, Notice Location of Semantic Actions in Tree for Revised Grammar • What is Order of Processing in this Case? rest
The Lexical Analysis ProcessA Graphical Depiction returns token to caller uses getchar ( ) to read character lexan ( ) lexical analyzer pushes back c using ungetc (c , stdin) tokenval Sets global variable to attribute value
The Lexical Analysis ProcessFunctional Responsibilities • Input Token String Is Broken Down • White Space and Comments Are Filtered Out • Individual Tokens With Associated Values Are Identified • Symbol Table Is Initialized and Entries Are Constructed for Each “Appropriate” Token • Under What Conditions will a Character be Pushed Back? • Can You Cite Some Examples in Programming Language Statements?
Algorithm for Lexical Analyzer function lexan: integer ; var lexbuf : array[ 0 .. 100 ] of char ; c : char ; begin loop begin read a character into c ; if c is a blank or a tab then do nothing else if c is a newline then lineno : = lineno + 1 else if c is a digit then begin set tokenval to the value of this and following digits ; return NUM end
Algorithm for Lexical Analyzer else if c is a letter then begin place c and successive letters and digits into lexbuf ; p : = lookup ( lexbuf ) ; if p = 0 then p : = iinsert ( lexbf, ID) ; tokenval : = p return the token field of table entry p end else / * token is a single character * / set tokenval to NONE ; / * there is no attribute * / return integer encoding of character c end end Note: Insert / Lookup operations occur against the Symbol Table !
Symbol Table Considerations o EOS i EOS t n c u d o m EOS v i d EOS OPERATIONS: Insert (string, token_ID) Lookup (string) NOTICE: Reserved words are placed into symbol table for easy lookup Attributes may be associated with each entry, i.e., Semantic Actions Typing Info: id integer etc. ARRAY symtable lexptr token attributes div mod id id 0 1 2 3 4 ARRAY lexemes
A Brief Look at Code Generation • Back-end of Compilation Process - Which Will Not Be Our Emphasis • We’ll Focus on Front-end • Important Concepts to Re-emphasize •• Abstract Syntax Machine for Intermediate Code Generation •• L-value Vs. R-value I : = 5 ; L - Location I : = I + 1 ; R - Contents May Be Attributes in Symbol Table
A Brief Look at Code Generation • Employ Statement Templates for Code Generation. • Each Template Characterizes the Translation • Different Templates for Each Major Programming Language Construct, if, while, procedure, etc. WHILE IF label test code for expr code for expr gofalse out gofalse out code for stmt code for stmt label out goto test label out
Concluding Remarks / Looking Ahead • We’ve Reviewed / Highlighted Entire Compilation Process • Introduced Context-free Grammars (CFG) and Indicated /Illustrated Relationship to Compiler Theory • Reviewed Many Different Versions of Parse Trees That Assist in Both Recognition and Translation • We’ll Return to Beginning - Lexical Analysis • We’ll Explore Close Relationship of Lexical Analysis to Regular Expressions, Grammars, and Finite Automatons