Understanding Eukaryotic Open Reading Frames and Gene Structure
This document explores the complexities of open reading frames (ORFs) in eukaryotic DNA. It compares eukaryotic and prokaryotic gene structures, emphasizing the significance of exons and introns, the challenges of identifying true ORFs due to splicing, and the implications for protein translation. The paper also presents practical coding assignments aimed at locating ORFs within specific eukaryotic sequences while discussing the impact of intron sizes and positions on ORF designation. Proper understanding of these concepts is critical for accurate gene prediction and bioinformatics analysis.


Understanding Eukaryotic Open Reading Frames and Gene Structure
E N D
Presentation Transcript
Introduction • The open reading frame: (OFR) in prokaryotics DNA (test your application) • The structure of the Eukaryotic gene. • Findings gene in Eukaryotes • ORF and problems with ORF • First exon and first intron • Distinguish introns/exons (splice sites) • Proximity of promoters (mentioned) • Bases pair patterns • Homology with existing sequences.
ORF prokaryotics(Pal Gene E.Coli) Adapted Understanding bioinformatics 9.3
Using your assignment code • Open the file: ORF pal gene.fasta • Find all open reading frames. (This time you must modify your code to translate each codon, copy form convertor_hashtable.txt • Compare to file: pal protein sequence.fasta. • Visual inspect the files. • What conclusion can you draw. • On which read frame is the true ORF.
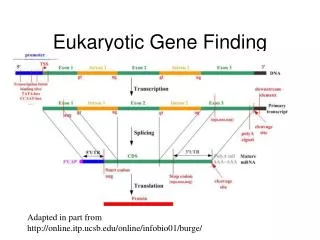
Structure of eukaryotic “gene The “basic” transcription/translation of Eukaryotic gene An ORF in Eukaryotic is a region of the DNA which “could be” a coding sequence (CDS) of a gene. It has a start codon (ATG) and an end codon [ one of three] (TAA, TAG, TGA) The diagram shows the DNA sequence of an eukaryotic gene including promoter, UTR…. Eukaryotic expression showing exons/ introns…, adapted from Zhang 2002
Structure of Eukaryotic CDS ALDH10 gene exon 1 shows a 5’UTR in exon
ORF in Eukaryotes • In comparison to prokaryotes Eukaryotic DNA is : • Gene density is much lower; genes are further apart and can vary significantly between chromosomes (~ 1.5% of human DNA is CDS). • The mRNA is monocistronic (one promoter per gene; N.B prokaryotes generally are organised in operons) moreover; A DNA sequence is transcribed into one mRNA sequences [this may not be true of viral DNA] • The “ORF” in the DNA sequence contains exons (translated sequences (CDS) or exon and introns (Non CDS). • The Introns are spliced to leave only exons Global Sequence
ORF in Eukaryotes • Some Impact of differences: • You can no longer reliably translate an ORF into AA sequence to give you the “true” protein (amino acid) sequence. • The DNA sequence of Introns is like any non coding region of the DNA in that the bases are just bases and should not be read as elements of a “codon” so in an intron sequence: • ATG does not represent a start codons • TAA/TAG/TGA do not represent stop codons. • Increase the complexity of determining true ORF in DNA sequences because of “false positive” start and stop codons in introns; thus many attempts to find genes/orf is now down via mRNA (not pre-mRNA) • The size of introns and exons need not be multiple of three. The impact of this on the DNA ORF analysis is “shift” the DNA reading frames.
Figure 9.2a the CDK10 gene Note in this ATG is shown in a red box (note it is 12 nucleotides into the first exon) {this will not impact on ORF but will mean an incorrect gene annotation: why) Only the first exon and intron is shown full; the rest shows partial sequences of introns are shown. The fully sequences can be found in the PISSRLE DNA sequence.
Frame shits using ORF technique • When a pre-mRNA is splice into mRNA all the exons will have to be in one reading frame. • However: • the splice sites need not occur at the beginning or start of exons. • introns need not be multiples of three in size; • What is the net effect of this in terms of trying to “predict” translation of proteins using DNA sequences.: • In can affect the Translation of anexon; • It can affect the starting residue of the following exon…. • It can mean the “translation” of an exon(s) are being carried out in the incorrect reading frame. • The effect of manual translation It is dependent on the starting position of the exon (correct reading frame) , the length of the exon and the length of the intron. • Refer to chapter 9 understanding bioinformatics
Predictive translation effect Exons/intron length • Consider the following: • We have the mRNA CDS of 60 bp in length (start…stop) • Let us assume that the intron1 is: • at the end of codon three (position 9) • the length of the intron is 30bp. • Intron 2 occurs at: • the end of codon 10 (position 30) • and is 45 bp in length • What is the effect of the translations: on Exon A and Exon B? Exon A Exon B TAA ATG DNA Strand
Predictive translation effect Exons/intron length • Consider the following: • We have the mRNA CDS of 60 bp in length (start…stop) • Let us assume that the intron1 is: • at the end of codon three (position 9) • the length of the intron is 30bp. • Intron 2 occurs at: • at position 29 (at the 3rdbp of codon 10) • and is 45 bp in length • What is the effect of the translations: on Exon A and Exon B? Exon A Exon B TAA ATG DNA Strand
Predictive translation effect Exons/intron length • Consider the following: • We have the mRNA CDS of 60 bp in length (start…stop) • Let us assume that the intron1 is: • at the end of codon three (position 9) • the length of the intron is 30bp. • Intron 2 occurs at: • at position 30(the end of codon 10) • and is 43 bp in length • What is the effect of the translations: on Exon A and Exon B? Exon A Exon B TAA ATG DNA Strand
Effect of Translation • Example 1 no effect all multiples of 3 • Example 2 the last residue of exon 2 is incorrect. The residue for Exon 3 is correct. (but starts at bp 2 of first codon) • Example 3 last expn is in different reading frame. • Refer to Incorrect_translation_examples.rar
Predicting exons ADH10 gene The diagram shows the exons 1 and exons 2 for ALDH10 gene. The correct coding sequence is shown in upper case. : the second ATG is the actual start codon The sequences can be found in the sample sequence files. What is the length of each exon (CDS). Consider what may happened if you applied a translation to each of the reading frames? Exon 1 is position 1352-1762; exon 2 is 2169-2400 . The position of the actual ATG is 1610 Figure 9.7 : understanding Bioinformatics
Finding Exons Coding regions • In order to ensure you can negate the previous issue(s) it is imperative to identify splice sites: • Identify start and stop signals (refer to Zhang 2002Chasin 2007) • Initial exon (start and 5’ splice site) • Internal exon (3’ and 5’ site) • Terminal site (3’ and and stop codon) • Identify splice junctions: • the 5’ splice junction is in general GT) • The 3’ splice junction is in general AG. • Refer to Exon 1 and Exon 2 in the ADH10 gene in previous slide: • Exon 1 is position 1352-1762; exon 2 is 2169-2400 . • The position of the actual ATG is 1610 • (1352-1610: is the 5’ UTR of exon 1; Translation initiation site) Global Sequence
Splice site prediction • While GT and AG are the general 5’ and 3’ splice; it is obvious that such pairings are not uncommon: in fact there is a high degree of false positives (understanding bioinformatics p. 392). Figure 9.10 understanding bioinformatics: spliceview… are prediction programs.
Proximity of promoters • Basically a true CDS (ORF) will have a promoter region near by : • Promoters in prokaryotes have well defined b.p. sequences (motifs) upstream of the CDS (true ORF): • The Pribnow box: TATAAT at about position -10 • ATTGACA at position -35 • An AT rich region before this box. • Eukaryotic promoters are more complex: there is more than one… • TATA box • CAAT box • GC rich regions • Conversely the presence of a ORF indicates that there should be a promoter close by. (Bioinformatics 1 will cover promoter prediction in greater detail in the next lecture)
BP sequences in Exons/Introns • The DNA sequence of a gene’s CDS contains different ratio of bases as opposed to the non “CDS of a gene” or non geneicDNA. (The student is expected to research this) • So the ratio of BP to each other and specific BP sequences is different between Exons/Introns and other non coding DNA. (remember the non CDS there are no codons) • If student requires greater, supplementary material, detail it can be found in Zhang et al 2002 and other references at the end of chapter 9 and 10 in understanding bioinformatics
Homology in coding regions • The CDS sequence of genes are generally highly: Hypothesis why this is the case? • Like prokaryotic DNA the CDS sequence is highly conserved so database searches can facilitate determining exons and thus ORF. • By extracting a possible exon region. It can be submitted to a search for similar sequences (BLAST search) to see what it may reveal. • If there are highly probable similarity existing exons then it is likely to be a true exon • An exon can also be translated and homologs of the translated sequence can also be submitted to search (The SWISS-Prot blast search engine should be used as it contains experimentally determined AA sequences.)
Alternative splicing • The diagram shows the main four types of alternative splicing. • It clearly indicates that the pre-mRNA is not the same as the mRNA (so direct translation via the DNA is fraught with danger) • Homological analysis and the use of expressed sequence tags (mRNA produced by genes over different times and different tissue types) can help determine the different splices • Can you think of any issues that may arise, using ORF, if there is alternative splicing?
Reference • Baxevanis, A.D. 2005 Bioinformatics: a practical guide to the analysis of genes and proteins. Wiley; Chapter 5. [book is in the library] • Klug, W.A. et al 2010; Concepts of Genetics; Pearson Education p. 596-p.597 • Zhang, M.Q. 2002 Computational prediction of eukaryotic coding genes. Nat Rev. Genet. 3 698-709. • Chasin, L.A. 2007 Searching for splicing motifs. AdvExp Med Biol. 623:85-106 • Zvelebil M. “understanding bioinformatics” chapter 9 {book is in the library] Global Sequence