Download

1 / 12
120 likes | 288 Views
Finding prokaryotic genes and non intronic eukaryotic genes. Lecture 8. Introduction . Review structure of prokaryotic genes What is ORF Finding open reading frames Eliminating false ORF Algorithm for finding ORF. Prokaryotic coding sequence structure.

E N D
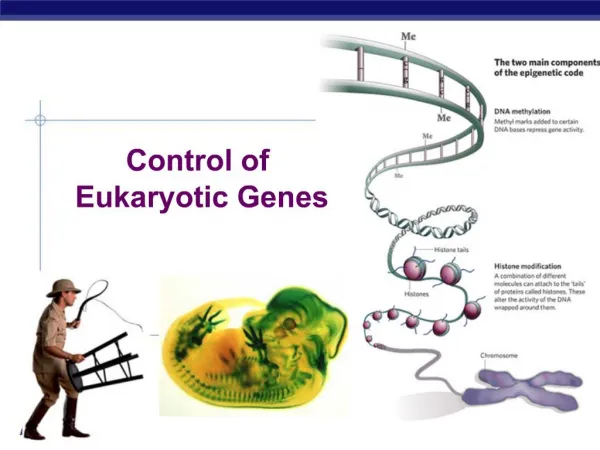
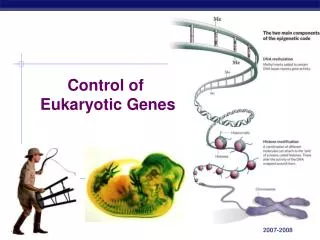
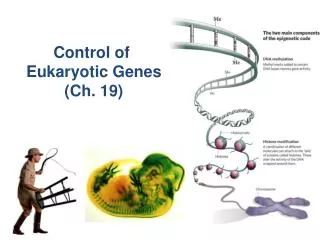
Finding prokaryotic genes and non intronic eukaryotic genes Lecture 8 Global Sequence
Introduction • Review structure of prokaryotic genes • What is ORF • Finding open reading frames • Eliminating false ORF • Algorithm for finding ORF.
Prokaryotic coding sequence structure • The gene coding sequence in the primary strand begins an ATG and ends at a stop codon: TAA, TGA TAG. • The diagram shows the template strand (TAC compliment of ATG) and three other Amino acids does not show a stop codon. • The codons are contiguous in ,prokaryotic and non-intronic, protein coding sequences.
Finding potential OFR • Translate each reading frame beginning at: • Base 1: 5’ 3’ frame 1 • Base 2: 5’ 3’ frame 2 • Base 3: 5’3’ frame 2 • Get the “reverse compliment of the given strand” and repeat the process”; 3’ 5’ frame 1…. • The diagram gives a partial sequence of the first exon in this gene. Global Sequence
Finding ORF • Look for start and stop codons (amino acids). • An ORF is the sequence which begins with the start codon (ATG in a DNA strand) and ends with a stop codon (TAA/TAG/TGA) • Which of the translated reading frames in the diagram opposite could contain ORF if you know that it is a partial sequence of the exon. ?
True ORF gene • Not all ORF are “true” genes so one needs to consider: • “False” start codons An ATG can also exist as part of the gene sequence where it does not represent a start codon. • What does it represent? • length of the ORFshould contain at minimum number of amino acids{consider the smallest protein is about 20 aa in length.] • Does an ORF represents a gene or a coding sequence (CDS) of a gene then: • An ORF in Prokaryotes can be translated directly into the amino acid sequence. • However in eukaryotes the ORF is a mixture of exons and introns. So the exons sequences must be found in order to determine the true amino acid sequence (covered in next lecture).
ORF’s in prokaryotic genes • In order to make it easier to find true genes or ORF in prokaryotic cells one needs to consider the structure of prokaryotic operons such as the “lac operon” below: • E. G. Within the lac operon there are 3 genes (CDS) all in close proximity: so the ATG lac Y is close to TAG of LacZ…. Global Sequence
Eliminating false positives • Gene density is about 1 per kilobase, ORF every 1000 bases. In some cases the genes density can cause the stop codon of one gene to overlap with the promoter of another [ Zvelebil chapter 9] or even the start codon to overlap with a stop codon • The DNA sequence of genes contains different ratio of bases as opposed to the non “CDS of a gene” or non geneicDNA: (The student is expected to research this) • An ORF should have a promoter region a small distance upstream of the start codon. Promoter sequences can be identified by sequences such as a TATA box…. (a lecture on the basic of finding promoters will discuss this in more details). • The CDS sequence of genes are generally highly conserved so “searching on line databases, for similar cds sequences can increase the chance of finding true ORF.
Algorithm to find ORF in prokaryotic Fasta files • Open files and convert file sequences (60 per line) into one string of sequences. • Translate the first reading frame of the downloaded strand. • Shift one position to the right and translate this sequence; repeat for reading frame three. (note in Fasta Files there will be no need to reverse the compliment as it can be assumed that the CDS is in the sequences given in the files) • Mark the start and the stop amino acids • Look for sequences with a start followed by a stop if there is none then there is no ORF in that reading frame. • Determine length of ORF and if less than 20 eliminate as it is a “false positive”
Exercise • The sequence for TUBAC3 gene can be found at: TUBAC3 gene complete sequence Note: the diagram only shows a part of the exon. And the partial sequence shown in the figure above begins at position 57 to position 357 • Download the file and analyse it in more detail to reveal problems that can with polycistronic and Eukaryotic sequences with muliple contiguous exons.
Exam question. • Open reading frames (ORFs) are an essential part of finding genes in genomes: • What is an ORF (2 Marks). • Using a suitable example describe how you would predict an ORF (8 Marks). • Write a basic algorithm to find ORF in a fasta file; e.g. (BTEB gene) (6 marks) • Describe, by illustrating you answer with a suitable example, two ways you can eliminate false ORF. (6 marks)
Reference • Baxevanis, A.D. 2005 Bioinformatics: a practical guide to the analysis of genes and proteins. Wiley; Chapter 5. [book is in the library] • Klug, W.A. et al 2010; Concepts of Genetics; Pearson Education p. 596-p.597 • Zhang, M.Q. 2002 Computational prediction of eukaryotic coding genes. Nat Rev. Genet. 3 698-709. • ZvelebilM. “understanding bioinformatics” chapter 9 {book is in the library] Global Sequence