ANOVA
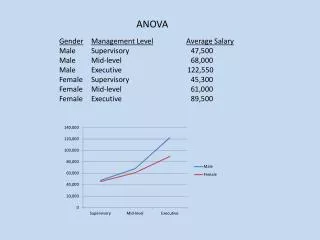
ANOVA. [ 예제 1] 임금차별. Class 변수 작성. SAS 명령어. proc anova data=employee1; class genminor; model salary = genminor; run;. 출력결과. 분산분석. 분산분석 (analysis of variance : ANOVA). 조사 대상을 다수의 집단으로 구분하여 집단의 평균을 비교하는 기법. 독립변수 (independent variable). 다수의 집단으로 분류하는 기준 변수. 종속변수 (dependent variable).


ANOVA
E N D
Presentation Transcript
SAS명령어 proc anova data=employee1; class genminor; model salary = genminor; run;
분산분석 분산분석(analysis of variance : ANOVA) 조사 대상을 다수의 집단으로 구분하여 집단의 평균을 비교하는 기법 독립변수(independent variable) 다수의 집단으로 분류하는 기준 변수 종속변수(dependent variable) 비교대상이 되는 변수 일원배치분산분석(oneway ANOVA) 이원배치분산분석(twoway ANOVA) 독립변수가 하나인 경우 독립변수가 둘인 경우 [질문] 제조회사에 따라 가정용 보일러의 열효율에 차이가 있는가를 조사하기 위하여 A, B, C 세 회사의 보일러를 무작위로 추출하여 열효율을 조사한 경우 독립변수 = ? 종속변수 = ? oneway ANOVA ? or twoway ANOVA ?
일원배치분산분석의 가정 및 가설 unknown world known world … … … … … … … … … … … … … … 독립표본(independent sample) ,
을 로 나타낼 수 있다 라고 하면
요인과 요인수준 요인(factor) 조사대상을 다수의 집단으로 구분하는 독립변수 요인수준(factor level) 구분된 집단 [질문] 제조회사에 따라 가정용 보일러의 열효율에 차이가 있는가를 조사하기 위하여 A, B, C 세 회사의 보일러를 무작위로 추출하여 열효율을 조사한 경우 요인 = ? 요인수준 = ?
처리 처리(treatment) 각 요인의 요인수준들의 조합 [질문] 제조회사에 따라 가정용 보일러의 열효율에 차이가 있는가를 조사하기 위하여 A, B, C 세 회사의 보일러를 무작위로 추출하여 열효율을 조사한 경우 처리 = ?
실험요인/관측요인 실험요인(experimental factor) 조사자의 통제하에 요인수준을 실험대상에 무작위로 할당할 수 있는 요인 관측요인(observational factor) 요인수준별로 결정된 조사대상 중 일부를 무작위로 추출하여 측정하는 경우 [질문] X, Y, Z 세 진통제의 효과를 비교하기 위하여 체질이 비슷한 여러 사람들에게 무작위로 한 진통제를 나누어주고 진통시간을 측정한 경우 제조회사에 따라 가정용 보일러의 열효율에 차이가 있는가를 조사하기 위하여 A, B, C 세 회사의 보일러를 무작위로 추출하여 열효율을 조사한 경우 요인 = ? / 관측요인 ? or 실험요인 ?
Oneway ANOVA의 자료구조 요인수준 평균 요인수준 의 평균 전체평균
[예] 우리나라 가정용 기름보일러 시장의 대부분을 점유하고 있는 A, B, C 세 회사의 제품을 9개씩 무작위로 추출하여 열효율을 조사한 결과는 다음과 같다. 보일러 회사 A B C 210 180 250 230 200 240 220 190 240 180 160 250 240 170 210 200 210 220 190 150 200 230 180 220 220 200 210 요인수준의 평균과 전체평균을 구하시오.
변동 변동(variation) 평균으로부터 떨어져 있는 거리(편차)의 제곱합 총변동(total variation) 처리변동(treatment variation) 오차변동(error variation) 총변동(total variation) = 총제곱합(sum of squares, total: SST)
처리변동(treatment variation) = 처리제곱합(sum of squares, treatment: SSTR) 오차변동(error variation) = 오차제곱합(sum of squares, error : SSE)
[예] 우리나라 가정용 기름보일러 시장의 대부분을 점유하고 있는 A, B, C 세 회사의 제품을 9개씩 무작위로 추출하여 열효율을 조사한 결과는 다음과 같다. 보일러 회사 A B C 210 180 250 230 200 240 220 190 240 180 160 250 240 170 210 200 210 220 190 150 200 230 180 220 220 200 210 SST, SSTR, SSE를 구하시오.
변동간의 관계 총변동 = 처리변동 + 오차변동
변동의 자유도 총변동 자유도 여기서 처리변동 자유도
오차변동 자유도 총변동의 자유도 = 처리변동의 자유도 + 오차변동의 자유도
평균변동 평균변동 변동을 자유도로 나눈 값 처리평균변동(Mean Square, Treatment: MSTR) 오차평균변동(Mean Square, Error: MSE)
평균변동의 기대값 MSTR의 기대값 MSE의 기대값
검정통계량 검정통계량 분자의 자유도가 이고 분모의 자유도가 인 F분포를 따름 처리효과가 있으면 즉 이면 의 값은 1보다 큰 값이 될 것임 따라서 우측검정 !
일원배치 분산분석표 변동의 원천 변동(제곱합) 자유도 평균변동(분산) 관측값F 처리 오차 총변동
[예제] 보일러 열효율 우리나라 가정용 기름보일러 시장의 대부분을 점유하고 있는 A, B, C 세 회사의 제품을 9개씩 무작위로 추출하여 열효율을 조사한 결과는 다음과 같다. 보일러 회사 A B C 210 180 250 230 200 240 220 190 240 180 160 250 240 170 210 200 210 220 190 150 200 230 180 220 220 200 210 세 회사 제품의 열효율에 차이가 있다고 할 수 있는가?
[기초통계 Review] 신뢰구간 신뢰구간(confidence interval) s를 알고 있는 상황에서 m를 추정하는 문제 1) ① ② s를 알지 못하는 상황에서 m를 추정하는 문제 p를 추정하는 문제 ③ s1, s2를 알고 있는 상황에서 m1-m2를 추정하는 문제 ⑤ s1, s2를 알지 못하는 상황에서 m1-m2를 추정하는 문제 ⑥ p1-p2를 추정하는 문제 ⑦ 등의 신뢰구간은 다음과 같은 형태로 구함 추정값에 일정한 값을 가감하여 구한 구간 하한 : 추정값 – (신뢰계수)(추정량 표본분포의 표준편차) 상한 : 추정값 + (신뢰계수)(추정량 표본분포의 표준편차) 오차한계(error margin) (신뢰계수)(추정량 표본분포의 표준편차) 신뢰구간의 폭(confidence level width) 신뢰구간의 상한 –하한 = 오차한계 * 2
처리평균에 관한 구간추정 를 알지 못하는 상황에서 에 대한 신뢰구간 추정량 추정량표본분포의 표준편차 신뢰계수 자유도 의 분포 [질문] 자유도 24의 t분포에서 유의수준 0.05의 신뢰계수를 구하시오.
두 처리평균 차이에 관한 추정 를 알지 못하는 상황에서 에 대한 신뢰구간 추정량 추정량표본분포의 표준편차 신뢰계수 자유도 의 분포 여기서의 오차한계(error margin)를 최소유의차(least significant difference: LSD)라고 함 두 처리평균 차이의 절대값이 LSD보다 크면 두 처리평균간의 차이가 있다고 할 수 있음.
[기초통계 Review] t분포 1) 모수 : 자유도(degree of freedom) 2) 확률변수값의 범위 3) 확률밀도함수 4) 기대값/분산 생략 5) 확률계산
[기초통계 Review] t분포표 <Excel함수> tdist(변수값,자유도,1 or 2) tdist(1.812,10,1) 0.05 tinv(확률,자유도) tinv(0.1,10) 0.812
[기초통계 Review] 추정량이 t분포를 가질 때의 신뢰계수 유의수준 a의 신뢰계수 t분포 왼쪽 신뢰계수 오른쪽 신뢰계수 [질문] 추정량의 분포가 t분포이고 표본크기가 16이라고 하자. 인 경우의 신뢰계수를 구하시오.
[기초통계 Review] F분포 1) 모수 : 분자의 자유도 : 분모의 자유도 2) 확률변수가 취할 수 있는 범위 3) 확률밀도함수 4) 기대값/분산 생략 5) 확률계산
[기초통계 Review] F분포표 <Excel함수> fdist(3.48,5,9) 0.05 finv(0.05,5,9) 3.48
이원배치분산분석 분산분석(analysis of variance : ANOVA) 조사 대상을 다수의 집단으로 구분하여 집단의 평균을 비교하는 기법 독립변수(independent variable) 다수의 집단으로 분류하는 기준 변수 종속변수(dependent variable) 비교대상이 되는 변수 일원배치분산분석(oneway ANOVA) 이원배치분산분석(twoway ANOVA) 독립변수가 하나인 경우 독립변수가 둘인 경우 [질문] H음료에서는 새로운 제품의 음료수를 개발하고 음료수의 색상과 포장용기가 판매량에 미치는 영향을 파악하기 위하여 네 지역을 시험시장으로 선정하여 판매량을 조사하였다. 독립변수 = ? 종속변수 = ? oneway ANOVA ? or twoway ANOVA ?
분산분석 용어 요인(factor) 조사대상을 다수의 집단으로 구분하는 독립변수 요인수준(factor level) 구분된 집단 처리(treatment) 각 요인의 요인수준들의 조합 [질문] H음료에서는 새로운 제품의 음료수를 개발하고 음료수의 색상(무색, 노랑, 파랑)과 포장용기(병, 캔)가 판매량에 미치는 영향을 파악하기 위하여 네 지역을 시험시장으로 선정하여 판매량을 조사하였다. 요인 = ? 요인수준 = ? 처리 = ?
Twoway ANOVA의 이점 (1) • 경제성 : 일원배치분산을 두 번 시행하는 것보다 필요한 표본의 수가 • 적어 경제적 이점이 있다. A와 B 두 독립변수가 각각 세 개의 요인수준 a1, a2, a3와 b1, b2, b3로 구성되어 있고, 각 요인수준에 따라 30개의 표본을 관찰하는 일원배치분산분석을 독립적으로 시행한다면, 아래의 설계에서 보는 바와 같이 180개의 표본이 필요하게 되지만 이원배치분산분석을 실시하면 90개의 표본만으로 같은 분석결과를 얻을 수 있다.
Twoway ANOVA의 이점 (2) (2) 일반화의 용이성 : 이원배치분산분석에서는 일원배치분산분석에서 통제가 어려운 표본의 개별적인 특성에 따른 차이를 통제할 수 있어 오차를 줄일 수 있는 장점을 가지고 있다. 예를 들어 일원배치분산분석에서 A의 요인수준별로 30개의 표본을 관찰한다면 각 A 요인수준에 있는 30개의 표본이 갖는 B요인의 특성은 일정하게 유지되어야 한다. 그러나 이원배치분산분석에서는 A의 각 요인수준에 B의 요인수준 b1, b2, b3에 따라 10개씩 균등하게 표본추출하여 A요인의 효과가 B요인수준에 따라 달리 작용하는지의 여부, 즉 상호작용효과(interaction effect)를 파악할 수 있어 그 결과를 일반화(generalize)하기가 용이하다.
Two-way ANOVA의 가정 Unknown world 독립추출 … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … … …
Tow-way ANOVA의 가설 독립변수 A의 번째 요인수준의 주효과(main effect) 독립변수 B의 번째 요인수준의 주효과(main effect) 독립변수 A의 번째 요인수준과 독립변수 B의 번째 요인수준의 상호작용효과(interaction effect)
<A요인 주효과 검정> 가 아니다(적어도 하나의 는 0이 아니다) <B요인 주효과 검정> 가 아니다(적어도 하나의 는 0이 아니다) <A와 B요인의 상호작용효과 검정> 가 아니다(적어도 하나의 는 0이 아니다)
[예제] 음료수 판매량 H음료에서는 새로운 제품의 음료수를 개발하고 음료수의 색상과 포장용기가 판매량에 미치는 영향을 파악하기 위하여 네 지역을 시험시장으로 선정하여 판매량을 조사하였다. 그 결과는 다음과 같다.
총변동 총변동(total variation) = 총제곱합(sum of squares, total: SST)
처리변동 처리변동(treatment variation) = 처리제곱합(sum of squares, treatment: SSTR)
오차변동 오차변동(error variation) = 오차제곱합(sum of squares, error : SSE)
A요인 주효과 검정통계량 <A요인 주효과 검정> 가 아니다(적어도 하나의 는 0이 아니다) F분포