Objective Analysis and Data Assimilation
Objective Analysis and Data Assimilation. Fred Carr COMAP NWP Symposium Monday, 13 December 1999. Exploring the Components of an NWP System. Objective Analysis Definition.


Objective Analysis and Data Assimilation
E N D
Presentation Transcript
Objective Analysis and Data Assimilation Fred CarrCOMAP NWP Symposium Monday, 13 December 1999
Objective Analysis Definition The graphic to the right depicts the basic problem of objective analysis, namely that we have irregularly spaced observations that must provide values for points on a regularly spaced grid. (Red dots represent observations and blue dots are grid points.) Objective analysis in NWP is the process of interpolating observed values onto the grid points used by the model in order to define the initial conditions of the atmosphere. Why isn’t this just a simple exercise in mathematical interpolation? There are several answers to this question.
Objective Analysis Definition 1.We can use our knowledge of atmospheric behavior to infer additional information from the data available in the area. For example, we can use balance relationships such as geostrophy or mass continuity to introduce dynamical consistency into the analysis. If we use one type of data to improve the analysis of another, then the analysis is said to be multivariate (e.g., height data can be used to help the analysis of winds).
Objective Analysis Definition 2. We can adjust the analysis procedure to filter out scales of motion that can’t be forecast by the model being used. For example, small mesoscale circulations represented in the observations may need to be smoothed out in an analysis for a global model.
Objective Analysis Definition 3. We can make use of a first guess field or background field provided by an earlier forecast from the same model. The blending of the background fields and the observations in the objective analysis process is especially important in data sparse areas. It allows us to avoid extrapolation of observation values into regions distant from the observation sites. The background field can also provide detail (such as frontal locations that exist between observations). Using a background field also helps to introduce dynamical consistency between the analysis and the model. In other words, that part of the analysis that comes from the background field is already consistent with the physical (dynamic) relationships implied by the equations used in the model.
Objective Analysis Definition 4. We can also make use of our knowledge of the probable errors associated with each observation. We can weight the reliability of each type of observation based on past records of accuracy.
In this section, we will examine a fundamental objective analysis equation in worded form in order to illustrate the basic principles that contribute to a numerical meteorological analysis. In simplest terms, the objective analysis equation attempts to determine the value of a particular meteorological variable at a particular grid point (at a particular valid time). In words, the analysis equation can be expressed as shown below. Analysis Equation
The Importance of the Background Field In the simplest kind of objective analysis scheme, the background values would not be used and the analysis would be based solely on new observations. In this case the equation would become: The observations themselves would be interpolated to the grid point by calculating a weighted average of the data. (One type of weight, for example, is proportional to the distance of the data from the grid point. The farther an observation is from the grid point, the less weight it gets.) If a grid point has no nearby observations, the simple scheme described here is in trouble!
Suppose we had a surface low along a coastline and the only observations (in red) were over the land. In order to obtain an analysis value at grid point “A”, a simple objective analysis scheme would have to extrapolate from the available data. Since there are no nearby data to the west of point “A”, an extrapolated value would reflect the decrease in pressure towards the coastline in the available data. Therefore the analyzed pressure at point “A” would be in the neighborhood of 974 hPa (whereas the correct value would be closer to 986 hPa)! So how can we solve this problem of data void areas? Analysis Equation
Analysis Equation One solution is to start our analysis using a short-range forecast of the same field from an earlier run of some NWP model (usually the same one that will use the analysis). If the forecast period is fairly short, say 3-6 hours, then very little error will have accumulated. This forecast (the background field, or first guess) will provide a much better estimate of the atmosphere over data sparse regions than would an extrapolation of distant observations. In the previous example, a 6-hr forecast of the surface low might produce an estimate at point “A” that would be in error by 2-4 hPa rather than 12 hPa.
Analysis Equation The first place the background field is used is in calculating the “correction”values for each observation site. This correction value, known as the observation increment, is the difference between the observed value and an interpolated background value for that observation point. In other words, the “new information” that will be analyzed to the grid point are the changes that the observations make to the background field, rather than the observations themselves.
Analysis Equation The background field is also used in the final step of the analysis in that the final analysis value is defined as the background value plus the weighted sum of observation increments (corrections). The use of the background field ensures that the analysis will blend smoothly from regions with good data to regions with no or sparse data (where the background field is allowed to dominate in determining the analysis value). Because this provides a better analysis of data sparse regions than an extrapolation of the observations, all objective analysis schemes used by NWP use background fields.
Analysis Equation For this reason, a very high priority in improving objective analysis is to improve the background field. Two ways to do this include: • We can set up a data assimilation procedure that allows us to make a sequence of short-range forecasts to provide background fields rather than one longer-range forecast. • We can improve the forecast model! There is a very interdependent relationship between an analysis and the model that uses it: The better the analysis, the better the forecast. The better the forecast model, the better the background field , therefore, the better the analysis.
Analysis Equation - Weight Factor Each observation increment is weighted based on its perceived accuracy and validity. The biggest difference among objective analysis schemes is how the weighting of observation increments is done.
Analysis Equation - Weight Factor Ideally the weight factor should take into account: • The distance of the observation from the grid point Data should be weighted inversely proportional to their distance from the grid point. The closest observations will receive the most weight since they should be most representative of the value at the grid point. Some objective analysis methods (such as the Cressman and Barnes schemes, which are no longer used in NWP) use only this factor in weighting. They are known as distance-dependent schemes.
Analysis Equation - Weight Factor • An estimate of the error in each type of observation (e.g., rawinsondes, satellites, profilers, etc.). If some observations were from a less reliable observing system, the weights should reflect this. More accurate observations should receive more weight. If two or more observations of the same type are located very close to each other (e.g., surface observations, ACARS data), most operational centers will average these observations to form one value known as a “super-ob.” Since an average value is probably more reliable and representative than a single value, the error assigned to the super-ob will be less, which allows it to have more weight in the analysis.
Analysis Equation - Weight Factor • An estimate of the expected error in the background field (e.g., the accumulated error inherent in a 6-hr forecast). Forecast errors should be taken into account, just as observations are. The error in the background field will be larger in regions which were not updated with new observations during the last analysis step.
Analysis Equation - Weight Factor • The effects of clustered data (i.e., data redundancy). If there are a lot of observations in one area, we do not want them to have an exaggerated effect on the analysis value. Redundant data have less independent information to provide to the analysis than an observation that represents a large area by itself (assuming it is reliable).
Analysis Equation - Weight Factor One objective analysis procedure that incorporates all four of the above factors into its weighting is the Optimum Interpolation or OI scheme. OI is based on a statistical estimation approach which seeks to minimize the analysis errors. Because of the assumptions made in applying OI in operational NWP, the scheme is not totally “optimal,” but its ability to include factors (b), (c), and (d) make it the most common objective analysis procedure used in NWP.
Analysis Equation Consider this example of how an OI scheme handles the uneven distribution of observations. Initially, all three values are at an equal distance from each other (we are also assuming no observational error). In this case, all analysis schemes that incorporate distance dependence compute the same weight for each value.
Analysis Equation However, if we move observations 2 and 3 toward each other, the OI weights change. In a scheme in which only distance from the grid point is a factor, the weights would always be equal. The OI scheme recognizes that as observations 2 and 3 approach each other, they become more correlated. Thus they represent less independent information to the analysis, and, consequently, will be given less weight.
Analysis Equation Note also that even though observation 1 does not move, its weight in the OI scheme increases. As an observation becomes more “lonely” (is less correlated with the other observations), it becomes more important to the analysis.
After points 2 and 3 become coincident at point “A,” the weight for point 1 takes on twice the weight of 2 and 3. In other words, 2 and 3 are treated as if they were one observation. In a distance-dependent only scheme, however, they would continue to have the same weight as point 1 since they would still be equally distant from the grid point. This would bias the analysis value at the grid point toward the values to the left of the region. Analysis Equation
Analysis Process:Evaluating an Analysis An important question you might be asking yourself is, “How can a forecaster tell if an analysis is any good?” It is a useful step for a forecaster to estimate how accurate the analysis is over a particular region. This will help in determining the reliability of the subsequent forecast. Although this is a difficult thing to do, it becomes easier with experience.
Analysis Process:Evaluating an Analysis Here are three guidelines that may prove useful. • Look at the observations. Compare, for example, the gradients in the data with the gradients of the analysis field. Are important small-scale features too smooth? Do any localized phenomena bias the analysis? • Compare the analyzed heights and vorticity, for example, with satellite data. With experience in interpreting satellite imagery, and especially when looping the images, you can detect phase and amplitude errors in the analyzed weather systems, especially over oceans.
Analysis Process:Evaluating an Analysis • Compare two or more analyses made for the same time for different models or by different NWP centers. The degree of agreement or disagreement over a particular area may indicate the reliability of the analysis for that area.
Analysis Process Final Comments on the Analysis Process • The analysis grid is not necessarily the same resolution as the grid used by the model. It must be chosen specifically for the analysis. This choice should be made based on the density of the observations, not on the resolution of the model’s grid. Sampling theory tells us that the smallest feature that can be resolved by observations has a scale twice the distance between the observing sites. Thus if the mean data spacing in a region is 100 km, no new information is gained by choosing an analysis grid resolution of 50 km, even if that is the resolution of the model’s grid.
Analysis Process • Since all observations have error, we do not want an objective analysis scheme to fit the data exactly. If it did it would be “overfitting.” An analysis that fits the data too closely would be a poor one for NWP because it would cause a lot of small-scale noise to exist during the early stages of the forecast.
We described the analysis procedure as one in which observed values of meteorological variables and short-range forecasts from an earlier model run are combined to produce grid point estimates of the initial conditions used to begin a new forecast. The observations may be clustered or they may be sparse. They may be from different observing systems, such as radiosondes, profilers, or aircraft, each having a different characteristic error. Optimal Interpolation is an analysis procedure that attempts to account for these factors when performing an analysis. Because the previous forecast (or background field) is so important to the analysis, this forecast should be accurate as possible. Data Assimilation systems attempt to ensure this in two ways. Data Assimilation Definition
They make use of all available data, even data received between analysis times. Many observing systems, such as satellites, radar, profilers, and aircraft, provide data nearly continuously, so it is important to find a way to incorporate these data into the forecast. They make shorter-range forecasts to be used as background fields. Shorter-range forecasts should be more accurate since they are not extrapolating as far into the future. Therefore, the changes to the background fields made by new observations (the “corrections”) should be smaller. Data Assimilation Definition
Data Assimilation Definition • In Data Assimilation, or Four-Dimensional Data Assimilation (4DDA) as it is often called, a numerical model is used to make a series of short-range forecasts, with new observations contributing data as they become available. The goal is to produce a sequence of initial conditions for the model that agree closely with observations, and are also in dynamical balance with the model. The process of maintaining dynamical balance is often called initialization. This is required so that the early stages of a forecast are relatively “noise-free.” Radical changes to the model values by the analysis may cause inbalances in the model equations.
New observations can be introduced in several ways: by periodic re-analysis (intermittent 4DDA) by gradual insertion (dynamic relaxation or “nudging”) by more advanced mathematical blending techniques (e.g., variational 4DDA) Data Assimilation Definition
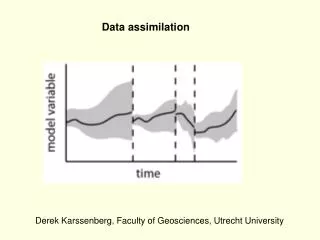
4-D Data Assimilation • This diagram illustrates an intermittent 4DDA process. As you can see, the error for the background field produced for 12Z (from the 9Z analysis and 3-hr model run) is only “error 3,” which should be less than that from a 12-hr forecast. • The new observations used for each 3-hr analysis should make smaller corrections to the background forecasts, allowing a smoother transition from one forecast to another (less generation of noise caused by large changes to the model values by the analysis). • In fact, 4DDA can be thought of as introducing time continuity into the analysis process.
4-D Data Assimilation • When NWP began, most data were “synoptic,” or taken every 6 to 12 hours. Today we have access to many types of “asynoptic” data (e.g., satellite, radar, aircraft) that come in nearly continuously, or at least hourly. 4DDA would have made little difference until these data were available. • The 4DDA procedure in the example provides a much more accurate background field for the 12Z analysis. These improved background fields, along with the use of optimum interpolation, actually create a continual challenge to those who design and build observing systems. If the observations from an instrument are not more accurate than, e.g., a 3-hr forecast, then these observations will not add much value to an analysis using a 3-hr forecast as a background field.
4-D Data Assimilation • Of course, 3-hr forecasts over the oceans may be worse than over land, so that satellite data, for example, may help the analysis over the ocean while having little impact over the land.
Future Data Assimilation • The procedure illustrated in the “4D Data Assimilation” section is called intermittent data assimilation and is currently used at some operational NWP centers. There are, however, several new data assimilation techniques that have been developed. • The future will likely see an increased utilization of continuous assimilation methods (or dynamic assimilation). These methods attempt to utilize data at the same time they are observed. Instead of having a major analysis step, the data are introduced continuously into the model. That is, data are essentially introduced into the model at every model time step. Since the direct replacement of grid point values by new observations will generate excessive noise in the forecast, techniques have been developed to “nudge” model values towards the current observation during the data assimilation period. In the future, new techniques under the category of variational data assimilation may be used to accomplish this “nudging.”
Future Data Assimilation • Consider the problem of a 3-hr forecast (represented by the red line) that will be used as a first guess field, as illustrated above. The match between the observations and the forecast at T=0 will be imperfect for two reasons: • model errors • observational errors • These are difficult to tell apart.
In variational data assimilation, we try to create the best possible fit between the model and the observational data such that the adjusted initial conditions are optimal for use in subsequent model forecasts. In the diagram, the first analysis produced is A. Although it fits the data well at T-3, it leads to a forecast that doesn’t fit the observations well by T=0. The band of green dots are the observations. Note that even data collected at the same time do not necessarily agree with each other. Future Data Assimilation
The adjoint method (illustrated to the right) is one type of variational 4DDA. In this method an iterative approach is used to adjust the initial analysis so that it is optimal for prediction. In other words, the adjusted analysis, Aadj., leads to a “model trajectory” (blue line) that produces a better 3-hr forecast for T=0, even though it may not be the best fit at T-3 hr. Future Data Assimilation
Current Eta Model Analysis Scheme Fred Carr NWP COMAP Symposium
Introduction In spring 1998, NCEP replaced the Regional Optimum Interpolation system (DiMego, 1988) with a variational objective analysis scheme known as 3D-Var. This scheme is similar to that implemented in the global model in June 1991 which was initially known as the Spectral Statistical Interpolation (SSI) analysis system (Derber et, 1991; Parrish and Derber, 1992).
Introduction, 3D-Var The 3D-Var is the analysis component of an intermittent data assimilation procedure known as EDAS (Eta Data Assimilation System) during which an analysis is produced every 3 hours. The 3D-Var has most of the beneficial properties of optimum interpolation discussed earlier but has several advantages over OI.
Fundamental Concepts Like OI, 3D-Var seeks to produce an analysis by minimizing the difference between the analysis and a judicious combination of a previous forecast (the background or first guess field) and the observations. That is, we want to minimize a “distance function” J which consists of J = JB +JO +JC
Fundamental Concepts: Distance Function J = JB +JO +JC • JB is a weighted fit of the analysis to the background field • JO is a weighted fit of the analysis to the observations • JC is a term which can be used to minimize the noise produced by the analysis (e.g., by introducing a balance). Currently, a weak geostrophy constraint is used.
Distance Function, cont. A common form for the JB term is where is the analysis variable (e.g. - temp.), is the background is the background field and error covariance matrix, or, in other words, the weight given to the first guess field (good forecasts get high weight: poor forecasts get low weight).
A common form for the JO term is • where represents all the observations, is the observational error covariance matrix and is a “transformation operator” which brings the grid point values to the observation location. If temperature is the observed variable, the is just an interpolation of grid point temperatures to the observed temperature.
Fundamental Concepts However, if represents radiance data from satellites, then is a set of radiative transfer equations which computes radiances from model temperature and moisture data. Thus the relatively-accurate observed radiances are used directly to correct model-estimated radiances and these corrections are fed back into the analyzed temperature and moisture variables through the solution process.
Fundamental Concepts The solution is obtained by minimizing J through “standard techniques” which we won’t get into. It is important to note that all the points are analyzed at once, using all of the available data.
Advantages • The 3 principal advantages of the 3D-Var procedure over the previous scheme are: 1. Many more “non-traditional” observational types can be included and can be included “more properly”. In other words, the analysis variables do not have to be the model variables.