The Knowledge Discovery Process
The Knowledge Discovery Process. DATA MINING. Data Mining adalah kegiatan untuk menemukan informasi atau pengetahuan yang berguna dari data yang jumlahnya besar. DM dan KDD. Tahapan KDD (Peter Cabena ). Penentuan Sasaran Bisnis (Business Objective Determination)


The Knowledge Discovery Process
E N D
Presentation Transcript
DATA MINING Data Mining adalahkegiatanuntukmenemukaninformasiataupengetahuan yang bergunadari data yang jumlahnyabesar.
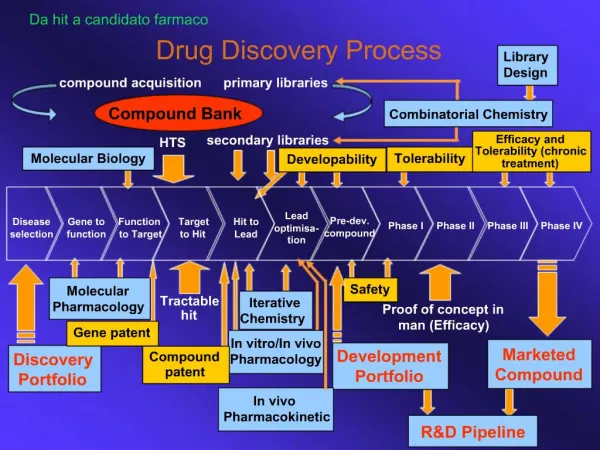
Tahapan KDD (Peter Cabena) PenentuanSasaranBisnis (Business Objective Determination) Persiapan Data (Data Preparation) – Data Selection – Data Preprocessing – Data Transformation Data Mining Analysis of Results Assimilation of Knowledge
Bussines Objective Determination #1 Mendefinisikanpermasalahanatautantanganbisnisdenganjelas. Hal inimerupakanaspek yang sangatesensialdalamsetiapproyek data mining. (Olehbeberapapeneliti KDD lainnya -- bahkan yang terkenal -- tahapaninicenderungdiabaikan! danjarangdisebut) Jikatanpasasaranbisnis yang jelas, orangberkata: "Here is the data, please mine it.". Tetapijika mining dilakukandanpengetahuandiperoleh, bagaimanadapatdiketahuibahwasolusitersebutbenar-benardibutuhkan?
Bussines Objective Determination #2 • Contohsasaranbisnis: Mengembangkansuatustrategi marketing untuk mempertahankanloyalitas customer Bali terhadap produk soft drink dengan brand danukurantertentu (200ml dalamkemasankaleng) selamabulanJuni, Juli, Agustusyang akan datang. Perusahaan akan menggunakankombinasidariberbagaistrategi marketing (mixed marketing), yang salahsatunya adalah direct mail campaign kepada customer yang tampaknya "mudahrusak" loyalitasnya.
Bussines Objective Determination #3 • Pertanyaankuncinya: Customer mana yang akandikirimibrosur supayausahainiberhasil? / Customer mana yang tergolongtidak loyal ?
Data Preparation #1 Mempersiapkan data yang diperlukanuntukproses data mining. Tujuannya: – agar data yang digunakanbenar-benarsesuaidenganpermasalahan yang akandipecahkan, dapatdijaminkebenarannya, dandalam format yang sesuai/tepat.
Data Preparation #2 Tahap yang paling banyakmengkonsumsi resources (manusia, biaya, waktu) yang tersedia. Biasanyamencapai 60% keseluruhanproyek KDD. MenurutCabena: Secaraberurutanuntuk 5 faseCabenamembutuhkan: 20% (fase 1) + 60% (fase 2)+ 10% (fase 3) + 10% (untuk kedua fase 4 dan 5).
Data Preparation #4 • Data Selection – Mengidentifikasisemuasumberinformasi internal daneksternaldanmemilihsebagiansaja dari data yang diperlukan untuk aplikasi data mining. • Contoh : • dipilih customers yang membeliproduk soft drink 200 ml dalam kemasan kaleng di Bali.
Data Preparation #5 Data Preprocessing – Meyakinkankualitasdari data yang telahdipilihpadatahapansebelumnya. – Dua issue yang paling seringdihadapkanpadatahapini: • Noisy Data • Missing Values
Data Preparation #6 • Data Transformation (#1) – Mengubah data kedalam model analitis. – Memodelkan data agar sesuaidengananalis yang diharapkandan format data yang diperlukan oleh algoritma data mining. • Contoh : customers yang membeliproduk soft drink 200 ml dalamkotakalumuniumdisortingdalam 10 kategori, yang masing-masingmembedakantingkatloyalitasnya: membeliproduktersebut 0-10%, 11-20%, ..... , 81-90%, 91-100% sepanjangwaktupembeliannya. Selanjutnya data inilah yang akandibawaketahap data mining.
Data Preparation #7 • Data Transformation (#2) Perludiperhatikanterlebihdahulu 2 tipeutama data yang digunakan: • Categorical: semuanilai yang mungkinada, bersifatterbatas • nominal: tanpa urutan, seperti status perkawinan (single,kawin, duda/janda, unknown) ataujeniskelamin (laki-laki,perempuan) • ordinal: denganurutan, seperti rating loyalitas customer (sangatbaik, baik, cukup, kurangatau vulnerable ataumudahdirusakloyalitasnya).
Data Preparation #8 • Data Transformation (#3) – Quantitative: semuanilai yang mungkindapatdiukurperbedaannya • continuous (nilai-nilaibilangan real): gajibulanan, rata-rata transaksi dalam satu periode waktu (bulan, kuartalatautahun). • discrete (nilai-nilaibilanganbulat): sepertijumlahpegawai, jumlahtransaksidalamsatuperiodewaktu.
Data Preparation #9 • Data Transformation (#4) • Contoh • Discretization: Pendapatan < Rp. 500.000, dikodekan1, Rp. 500.000 s.d. 1 juta dikodekan 2 dan seterusnya. • Normalization: Jikaproses data mining menggunakan ANN,karena sebagian besar ANN hanya menerima input dalam range 0 s.d. 1 (binary) atau -1 s.d. +1 (bipolar), maka parameter continuous yang diluar range tersebutharusdinormalisasi.
Data Mining #1 • Melakukanprosespencarianpengetahuanterhadap data yang ditransformasikan pada tahap sebelumnya. • ContohPengetahuanberbentukAssociation Rule untukkasus "Soft Drink“: IF soft drink sejenisdenganukuran yang lebihbesardibelidalamlebihdari 58% sejarahpembelian soft drink seorang consumer THEN consumer tersebutdiprediksi Loyal.
Data Mining #2 • ContohPengetahuanberbentukAssociation Rule untukkasus "Soft Drink“: • IF seorang consumer cenderunglebihbanyakmembeli soft drink merk "X" THEN consumer tersebutdiprediksiTidak Loyal • IF dihitungsecara rata-rata seorang consumer ternyatamembelilebihdari 345,67ml setiap kali belanja AND denganharga rata rata soft drink per 100ml >= Rp. 550, THEN consumer tersebutdiprediksi Loyal.
Analysis of Result Menginterpretasikandanmengevaluasioutput dari tahap mining: patterns. Pendekatananalisa yang digunakanakanbervariasi menurut operasi data mining yang digunakan, tetapibiasanyaakanmelibatkanteknikvisualisasi.
Assimilation of Knowledge Menggunakanhasil mining yang telahdievaluasi ke dalam perilaku organisasi dansisteminformasiperusahaan.
TahapanProses KDD (JiaWeihan) #1 Data cleaning Data integration Data selection Data transformation Data mining Pattern Evaluation Knowledge Presentation
TahapanProses KDD (JiaWeihan) #1 Data Cleaning: menghilangkan noise dandata yang inkonsisten. Data Integration: menggabungkanberbagaimacamsumber data. Data Selection: memilih data yang relevan(dari database) dengan "analysis task". "analysis task" = Business Objective Determination (Cabena).
TahapanProses KDD (JiaWeihan) #1 Data Transformation: transformasiataukonsolidasi data kedalambentuk yang lebihbaikuntuk mining, denganmewujudkanoperasi summary dan aggregation (misal: daily data ---> monthly ---> quarterly ---> annual). Data Mining: mengekstrak patterns dari data denganmenerapkan "intelligent methods".
TahapanProses KDD (JiaWeihan) #1 Pattern Evaluation: mengidentifikasisejumlahpolayang sungguh-sungguhmenarikdanbakalmenjadipengetahuanberdasarkansejumlahpengukuranketertarikan (interestingness measures) sepertirule support dan rule confidenceuntuk rule extraction. Knowledge Presentation: penggunaanteknik-teknikvisualisasidanrepresentasiuntukmenyajikan pengetahuan yang telah diperoleh kepada user
Mengapa Data DiprosesAwal? • Data dalam dunia nyata kotor • Tak-lengkap: nilai-nilaiatributkurang, atributtertentu yang dipentingkan tidak disertakan, atau hanyamemuat data agregasi. Misal, pekerjaan=“” • Noise:memuat error ataumemuat outliers (data yang secaranyataberbedadengan data-data yang lain). Misal, Salary=“-10” • Tak-konsisten: memuatperbedaandalamkodeataunama • Misal, Age=“42” Birthday=“03/07/1997” • Misal, rating sebelumnya “1,2,3”, sekarang rating “A, B, C”
Mengapa Data DiprosesAwal? • Data yang lebihbaikakanmenghasilkan data mining yang lebihbaik • Data preprocessing membantu didalam memperbaiki presisidankinerja data mining danmencegahkesalahandidalam data mining.
Mengapa Data Kotor ? • Ketaklengkapan data Noise data diakibatkanoleh • Nilai data tidaktersediasaatdikumpulkan • Masalahmanusia, hardware, dansoftware • Ketakkonsistenandata diakibatkanoleh • Sumber data yang berbeda
MengapaPemrosesanAwal Data Penting? • Kualitas data tidak ada, kualitas hasil mining tidak ada! • Kualitas keputusan harus didasarkan kepada kualitas data • Misal, duplikasi data atau data hilangbisamenyebabkanketidak-benaranataubahkanstatistik yang menyesatkan. • Ekstraksi data, pembersihan, dantransformasimerupakan kerja utama dari pembuatan suatu data warehouse. — Bill Inmon
TugasUtamaPemrosesanAwal Data • Pembersihan data (data yang kotor) – Mengisinilai-nilai yang hilang, menghaluskan noise data, mengenali atau menghilangkan outlier, danmemecahkanketak-konsistenan • Integrasi data (data heterogen) • Integrasibanyak database, banyakkubus data, ataubanyak file • Transformasi data (data detail) • Normalisasidanagregasi
TugasUtamaPemrosesanAwal Data • Reduksi data (jumlah data yang besar) • Mendapatkanrepresentasi yang direduksidalam volume tetapi menghasilkan hasil analitikal yang samaataumirip • Diskritisasi data (kesinambunganatribut) • Bagian dari reduksi data tetapi dengan kepentingankhusus, terutama data numerik