Rendering battlefield 4 with mantle
530 likes | 696 Views
Rendering battlefield 4 with mantle. Johan Andersson – Electronic Arts. DX11. Mantle. Avg: 78 fps Min: 42 fps. Avg: 120 fps Min: 94 fps. +58%!. Core i7-3970x, AMD Radeon R9 290x, 1080p ULTRA. Bf4 mantle goals. Goals: Significantly improve CPU performance

Rendering battlefield 4 with mantle
E N D
Presentation Transcript
Rendering battlefield 4 with mantle Johan Andersson – Electronic Arts
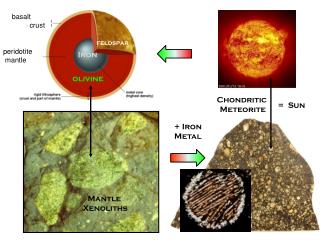
DX11 Mantle Avg: 78 fps Min: 42 fps Avg: 120 fps Min: 94 fps +58%! Core i7-3970x, AMD Radeon R9 290x, 1080p ULTRA
Bf4 mantle goals Goals: • Significantly improve CPU performance • More consistent & stable performance • Improve GPU performance where possible • Add support for a new Mantle rendering backend in a live game • Minimize changes to engine interfaces • Compatible with built PC content • Work on wide set of hardware • APU to quad-GPU • But x64 only (32-bit Windows needs to die) Non-goals: • Design new renderer from scratch for Mantle • Take advantage of asymmetric MGPU (APU+discrete) • Optimize video memory consumption
Bf4 mantle strategic goals • Prove that low-level graphics APIs work outside of consoles • Push the industry towards low-level graphics APIs everywhere • Build a foundation for the future that we can build great games on
shaders • Shader resource bind points replaced with a resource table object - descriptor set • This is how the hardware accesses the shader resources • Flat list of images, buffers and samplers used by any of the shader stages • Vertex shader streams converted to vertex shader buffer loads • Engine assign each shader resource to specific slot in the descriptor set(s) • Can share slots between shader stages = smaller descriptor sets • The mapping takes a while to wrap one’s head around
Shader conversion • DX11 bytecode shaders gets converted to AMDIL & mapping applied using ILC tool • Done at load time • Don’t have to change our shaders! • Have full source & control over the process • Could write AMDIL directly or use other frontends if wanted
Descriptor sets • Very simple usage in BF4: for each draw call write flat list of resources • Essentially direct replacement of SetTexture/SetConstantBuffer/SetInputStream • Single dynamic descriptor set object per frame • Sub-allocate for each draw call and write list of resources • ~15000 resource slots written per frame in BF4, still very fast
Descriptor sets – future OPTIMIZATIONS • Use static descriptor sets when possible • Reduce resource duplication by reusing & sharing more across shader stages • Nested descriptor sets
Compute pipelines • 1:1 mapping between pipeline & shader • No state built into pipeline • Can execute in parallel with rendering • ~100 compute pipelines in BF4
Graphics pipelines • All graphics shader stages combined to a single pipeline object together with important graphics state • ~10000 graphics pipelines in BF4 on a single level, ~25 MB of video memory • Could use smaller working pool of active state objects to keep reasonable amount in memory • Have not been required for us
Pre-building pipelines • Graphics pipeline creation is expensive operation, do at load time instead of runtime! • Creating one of our graphics pipelines take ~10-60 ms each • Pre-build using N parallel low-priority jobs • Avoid 99.9% of runtime stalls caused by pipeline creation! • Requires knowing the graphics pipeline state that will be used with the shaders • Primitive type • Render target formats • Render target write masks • Blend modes • Not fully trivial to know all state, may require engine changes / pre-defining use cases • Important to design for!
Pipeline cache • Cache built pipelines both in memory cache and disk cache • Improved loading times • Max 300 MB • Simple LRU policy • LZ4 compressed (free) • Database signature: • Driver version • Vendor ID • Device ID
Memory management • Mantle devices exposes multiple memory heaps with characteristics • Can be different between devices, drivers and OS:es • User explicitly places resources in wanted heaps • Driver suggests preferred heaps when creating objects, not a requirement
Frostbite memory heaps • System Shared Mapped • CPU memory that is GPU visible. • Write combined & persistently mapped = easy & fast to write to in parallel at any time • System Shared Pinned • CPU cached for readback. • Not used much • Video Shared • GPU memory accessible by CPU. Used for descriptor sets and dynamic buffers • Max 256 MB (legacy constraint) • Avoid keeping persistently mapped as WDMM doesn’t like this and can decide to move it back to CPU memory • Video Private • GPU private memory. • Used for render targets, textures and other resources CPU does not need to access
Memory REFERENCES • WDDM needs to know which memory allocations are referenced for each command buffer • In order to make sure they are resident and not paged out • Max ~1700 memory references are supported • Overhead with having lots of references • Engine needs to keep track of what memory is referenced while building the command buffers • Easy & fast to do • Each reference is either read-only or read/write • We use a simple global list of references shared for all command buffers.
Memory pooling • Pooling memory allocations were required for us • Sub allocate within larger 1 – 32 MB chunks • All resources stored memory handle + offset • Not as elegant as just void* on consoles • Fragmentation can be a concern, not too much issues for us in practice • GPU virtual memory mapping is fully supported, can simplify & optimize management
Overcommitting video memory • Avoid overcommitting video memory! • Will lead to severe stalls as VidMM moves blocks and moves memory back and forth • VidMM is a black box • One of the biggest issues we ran into during development • Recommendations • Balance memory pools • Make sure to use read-only memory references • Use memory priorities
Memory priorities • Setting priorities on the memory allocations helps VidMM choose what to page out when it has to • 5 priority levels • Very high = Render targets with MSAA • High = Render targets and UAVs • Normal = Textures • Low = Shader & constant buffers • Very low = vertex & index buffers
Memory residency future • For best results manage which resources are in video memory yourself & keep only ~80% used • Avoid all stalls • Can async DMA in and out • We are thinking of redesigning to fully avoid possibility of overcommitting • Hoping WDDM’s memory residency management can be simplified & improved in the future
Resource lifetimes • App manages lifetime of all resources • Have to make sure GPU is not using an object or memory while we are freeing it on the CPU • How we’ve always worked with GPUs on the consoles • Multi-GPU adds some additional complexity that consoles do not have • We keep track of lifetimes on a per frame granularity • Queues for object destruction & free memory operations • Add to queue at any time on the CPU • Process queues when GPU command buffers for the frame are done executing • Tracked with command buffer fences
Linear frame allocator • We use multiple linear allocators with Mantle for both transient buffers & images • Used for huge amount of small constant data and other GPU frame data that CPU writes • Easy to use and very low overhead • Don’t have to care about lifetimes or state • Fixed memory buffers for each frame • Super cheap sub-allocation from from any thread • If full, use heap allocation (also fast due to pooling) • Alternative: ring buffers • Requires being able to stall & drain pipeline at any allocation if full, additional complexity for us
tiling • Textures should be tiled for performance • Explicitly handled in Mantle, user selects linear or tiled • Some formats (BC) can’t be accessed as linear by the GPU • On consoles we handle tiling offline as part of our data processing pipeline • We know the exact tiling formats and have separate resources per platform • For Mantle • Tiling formats are opaque, can be different between GPU architectures and image types • Tile textures with DMA image upload from SystemShared to VideoPrivate • Linear source, tiled destination • Free
Command buffers • Command buffers are the atomic unit of work dispatched to the GPU • Separate creation from execution • No “immediate context” a la DX11 that can execute work at any call • Makes resource synchronization and setup significantly easier & faster • Typical BF4 scenes have around ~50 command buffers per frame • Reasonable tradeoff for us with submission overhead vs CPU load-balancing
Command buffer sources • Frostbite has 2 separate sources of command buffers • World rendering • Rendering the world with tons of objects, lots of draw calls. Have all frame data up front • All resources except for render targets are read-only • Generated in parallel up front each frame • Immediate rendering (“the rest”) • Setting up rendering and doing lighting, post-fx, virtual texturing, compute, etc • Managing resource state, memory and running on different queues (graphics, compute, DMA) • Sequentially generated in a single job, simulate an immediate context by splitting the command buffer • Both are very important and have different requirements
Resource transitions • Key design in Mantle to significantly lower driver overhead & complexity • Explicit hazard tracking by the app/engine • Drives architecture-specific caches & compression • AMD: FMASK, CMASK, HTILE • Enables explicit memory management • Examples: • Optimal render target writes → Graphics shader read-only • Compute shaderwrite-only → DrawIndirect arguments • Mantle has a strong validation layer that tracks transitions which is a major help
Managing resource transitions • Engines need a clear design on how to handle state transitions • Multiple approaches possible: • Sequential in-order command buffers • Generate one command buffer at the time in order • Transition resources on-demand when doing operation on them, very simple • Recommendation: start with this • Out-of-order multiple command buffers • Track state per command buffer, fix up transitions when order of command buffers is known • Hybrid approaches & more
Managing resource transitions in frostbite • Current approach in Frostbite is quite basic: • We keep track of a single state for each resource (not subresource) • The “immediate rendering” transition resources as needed depending on operation • The out of order “world rendering” command buffers don’t need to transition states • Already have write access to MRTs and read-access to all resources setup outside them • Avoids the problem of them not knowing the state during generation • Works now but as we do more general parallel rendering it will have to change • Track resource state for each command buffer & fixup between command buffers
Dynamic State objects • Graphics state is only set with the pipeline object and 5 dynamic state objects • State objects: color blend, raster, viewport, depth-stencil, MSAA • No other parameters such as in DX11 with stencil ref or SetViewportfunctions • Frostbite use case: • Pre-create when possible • Otherwise on-demand creation (hash map) • Only ~100 state objects! • Still possible to end up with lots of state objects • Esp. with state object float & integer values (depth bounds, depth bias, viewport) • But no need to store all permutations in memory, objects are fast to create & app manages lifetimes
queues • Universal queue can do both graphics, compute and presents • We use also use additional queues to parallelize GPU operations: • DMA queue – Improve perf with faster transfers & avoiding idling graphics will transfering • Compute queue - Improve perf by utilizing idle ALU and update resources simultaneously with gfx • More GPUs = more queues!
Queues synchronization • Order of execution within a queue is sequential • Synchronize multiple queues with GPU semaphores (signal & wait) • Also works across multiple GPUs Wait S Compute S W Graphics
Queues synchronization cont • Started out with explicit semaphores • Error prone to handle when having lots of different semaphores & queues • Difficult to visualize & debug • Switched to more representation more similar to a job graph • Just a model on top of the semaphores
Gpu job graph • Each GPU job has list of dependencies (other command buffers) • Dependencies has to finish first before job can run on its queue • The dependencies can be from any queue • Was easier to work with, debug and visualize • Really extendable going forward DMA Compute Graphics 1 Graphics 2 Graphics 2
Asyncdma • AMD GPUs have dedicated hardware DMA engines, let’s use them! • Uploading through DMA is faster than on universal queue, even if blocking • DMA have alignment restrictions, have to support falling back to copies on universal queue • Use case: Frame buffer & texture uploads • Used by resource initial data uploads and our UpdateSubresource • Guaranteed to be finished before the GPU universal queue starts rendering the frame • Use case: Multi-GPU frame buffer copy • Peer-to-peer copy of the frame buffer to the GPU that will present it
Async compute • Frostbite has lots of compute shader passes that could run in parallel with graphics work • HBAO, blurring, classification, tile-based lighting, etc • Running as async compute can improve GPU performance by utilizing ”free” ALU • For example while doing shadowmap rendering (ROP bound)
Async compute – tile-based lighting • 3 sequential compute shaders • Input: zbuffer & gbuffer • Output: HDR texture/UAV • Runs in parallel with graphics pipeline that renders to other targets Wait Cull lights Lighting S TileZ Gbuffer S Shadowmaps Reflection Distort W Transp Compute Graphics
Async compute – tile-based lighting • We manually prepare the resources for the async compute • Important to not access the resources on other queues at the same time (unless read-only state) • Have to transition resources on the queue that last used it • Up to 80% faster in our initial tests, but not fully reliable • But is a pretty small part of the frame time • Not in BF4 yet Wait Cull lights Lighting S TileZ Gbuffer S Shadowmaps Reflection Distort W Transp Compute Graphics
Multi-gpu • Multi-GPU alternatives: • AFR – Alternate Frame Rendering (1-4 GPUs of the same power) • Heterogeneous AFR – 1 small + 1 big GPU (APU + Discrete) • SFR – Split Frame Rendering • Multi-GPU Job Graph – Primary strong GPU + slave GPUs helping • Frostbite supports AFR natively • No synchronization points within the frame • For resources that are not rendered every frame: re-render resources for each GPU • Example: sky envmap update on weather change • With Mantle multi-GPU is explicit and we have to build support for it ourselves
Multi-gpuafr with mantle • All resources explicitly duplicated on each GPU with async DMA • Hidden internally in our rendering abstraction • Every frame alternate which GPU we build command buffers for and are using resources from • Our UpdateSubresource has to make sure it updates resources on all GPU • Presenting the screen has to in some modes copy the frame buffer to the GPU that owns the display • Bonus: • Can simulate multi-GPU mode even with single GPU! • Multi-GPU works in windowed mode!
Multi-gpu issues • GPUs are independently rendering & presenting to the screen – can cause micro-stuttering • Frames are not presented in a regular intervals • Frame rate can be high but presentation & gameplay is not smooth • FCAT is a good tool to analyse this Irregular presentation interval GPU0 GPU0 Frame 0 P GPU1 GPU1 Frame 1 Frame 2 Frame 3 P P P
Multi-gpu issues • GPUs are independently rendering & presenting to the screen – can cause micro-stuttering • Frames are not presented in a regular intervals • Frame rate can be high but presentation & gameplay is not smooth • FCAT is a good tool to analyse this • We need to introduce dependency & dampening between the GPUs to alleviate this – frame pacing Ideal presentation interval GPU0 Frame 0 Frame 1 Frame 2 Frame 3 P P P P GPU1
Frame pacing • Measure average frame rate on each GPU • Short history (10-30 frames) • Filter out spikes • Insert delay on the GPU before each present • Force the frame times to become more regular and GPUs to align • Delay value is based on the calculate avg frame rate Delay Frame 2 P P Frame 0 GPU0 GPU0 Frame 1 D P Frame 3 P GPU1 GPU1