Normal distribution
Normal distribution. z.Shjajari. بهترين شاخص مركزي توصيف هر توزيع كمي : ميانگين بهترين شاخص مركزي براي ميانگين : انحراف معيار. توزیع نرمال ، یکی از مهمترین توزیعهای احتمالی پیوسته در نظریه احتمالات است . دلیل اصلی این پدیده، نقش توزیع نرمال در قضیهٔ حد مرکزی است.


Normal distribution
E N D
Presentation Transcript
Normal distribution z.Shjajari
بهترين شاخص مركزي توصيف هر توزيع كمي : ميانگين • بهترين شاخص مركزي براي ميانگين : انحراف معيار
توزیع نرمال ، یکی از مهمترینتوزیعهای احتمالیپیوستهدرنظریه احتمالاتاست. • دلیل اصلی این پدیده، نقش توزیع نرمال در قضیهٔ حد مرکزی است. • در قضیهٔ حد مرکزی نشان داده میشود که تحت شرایطی، مجموع مقادیر حاصل از متغیرهای مختلف که هرکدام میانگین و پراکندگی متناهی دارند، با افزایش تعداد متغیرها، دارای توزیعی بسیار نزدیک به توزیع نرمال است.
این قانون که تحت شرایط و مفروضات طبیعی نیز برقرار است، سبب شده که برایند نوسانهای مختلفِ تعداد زیادی از متغیرهای ناشناخته، در طبیعت به صورت توزیع نرمال آشکار شود. بعنوان مثال، با اینکه متغیرهای زیادی بر میزان خطای اندازهگیریِ یک کمیت اثر میگذارند، (مانند خطای دید، خطای وسیله اندازهگیری، شرایط محیط و ...) اما با اندازهگیری های متعدد، برایند این خطاها همواره دارای توزیع نرمال است که حول مقدار ثابتی پراکنده شده است. مثالهای دیگری از این نوسانهای طبیعی، طول قد، وزن یا بهرهٔ هوشی افراد است.
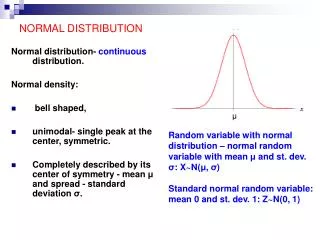
این توزیع گاهی به دلیل استفادهٔ کارل فردریک گاوس از آن در کارهای خود با نام توزیع یا تابع گوسی (گاوسی) نامیده میشود؛ همچنین به دلیل شکل این توزیع، با نام انحنای زنگولهای • Bell Shaped (زنگدیس) نیز معروف است. • تابع احتمال این توزیع دارای دو پارامتر است که یکی تعیین کنندهٔ مکان (μ) و دیگری تعیین کنندهٔ مقیاس (σ) توزیع هستند. • منحنی تابع احتمال حول میانگین توزیع متقارن است. در حالت خاص اگر μ = 0 و σ = 1 باشد توزیع، نرمال استانداردنامیده میشود
قسمت آبی تیره در فاصلهٔ یک برابر انحراف معیار از میانگین توزیع قرار دارد. • قسمت آبی روشن و آبی تیره به طور توام، در فاصلهٔ دو برابر انحراف معیار از میانگین توزیع قرار دارند. • در توزیع نرمال، اولی برابر با ۶۸٪ سطح زیر نمودار و دومی برابر با ۹۵٪ سطح زیر نمودار است
توزیع نرمال فراوانی میانگین فشار خون جامعه فراوانی فشار خون ها (اعداد طبیعی) فشار خون کمیتی پیوسته است 10 11 12 13 14 فشار خون
احتمال 1 توزیع نرمال می خواهیم فراوانی را به احتمال تبدیل کنیم: P(robability) = F(requency) / N(umber) 10 11 12 13 14 فشار خون جمع تمام این احتمالات چند است؟ (سطح زیر منحنی چقدر است؟( 1) این منحنی چه چیز را نشان می دهد؟ (چگونگی توزیع احتمال فشار خون های مختلف در جامعه) به این طور نمودارها، نمودارهای نرمال (توزیع نرمال) می گویند
احتمال 1 توزیع نرمال خصوصیات توزیع نرمال: زنگوله ای بودن Symmetric بودن 10 11 12 13 14 فشار خون
احتمال توزیع نرمال 1 آیا انتظار دارید متغییری مثل وزن هم توزیع نرمال داشته باشد؟ 55 65 75 85 95 وزن
احتمال 1 توزیع نرمال شاخص های نماینده توزیع نرمال: 135 138 141 144 147 غلظت سدیم خون افراد جامعه
توزیع نرمال احتمال 1 95% 66% شاخص های نماینده توزیع نرمال: میانگین (µ): نشان دهنده تراکم داده ها حول یک مقدار انحراف معیار (σ): نشان دهنده میزان پراکندگی داده ها از میانگین مثال کاربرد µ و σ: µ- 2SD µ- SD µ µ+ SD µ+ 2SD غلظت سدیم خون افراد جامعه
توزیع نرمال احتمال 1 95% 66% تمرین 1: اگر میانگین فشار خون در جامعه 12 و انحراف معیار آن 1 باشد: چند درصد مردم فشار خون بالای 14 دارند؟ چند درصد مردم فشار خون کمتر از 11 دارند؟ 2.5% 2.5% 10 11 12 13 14 فشار خون
توزیع نمونه برداری خصوصیات:نمونه هاي متعدد: میانگین همه توزیع نرمال ها برابر میانگین جامعه است. با افزایش اندازه نمونه انحراف معیار منحنی نرمال کاهش می یابد. معرفی SEM (SD x) SDx = σ/ n توزیع میانگین یک توزیع نرمال است!
احتمال 1 95% 66% Estimation 3 2 4 1 5 SDx = σ/ n = 0.1 µ- 0.2 µ- 0.1 µ µ+ 0.1 µ+ 0.2 فشار فرض: میانگین نمونه روی تقطه 1 µ=12.7 فرض: میانگین نمونه روی تقطه 2 ←µ=12.6 فرض: میانگین نمونه روی تقطه 3 ←µ=12.5 فرض: میانگین نمونه روی تقطه 4 ←µ=12.4 فرض: میانگین نمونه روی تقطه 5 ←µ=12.3
احتمال 1 95% 66% Estimation 3 2 4 1 5 SDx = σ/ n = 0.1 µ- 0.2 µ- 0.1 µ µ+ 0.1 µ+ 0.2 فشار • اگر میانگین نمونه در نقطه ای بین نقطه 1و 5 باشد، میانگین جامعه بین 3/12 و 7/12 است. • 95% میانگین ها بین تقطه 1و 5 هستند. • 1و2 ← به احتمال 95% میانگین جامعه بین 3/12 و 7/12 است.
احتمال 1 95% 66% Estimation 3 2 4 1 5 SDx = σ/ n = 0.1 µ- 0.2 µ- 0.1 µ µ+ 0.1 µ+ 0.2 فشار • بیان ریاضی: confidence interval (حدود اطمینان): CI • % 95 CI 12.3 to 12.7 • Confidence limits
احتمال 1 95% 66% Estimation 3 2 4 1 5 SDx = σ/ n = 0.1 µ- 0.2 µ- 0.1 µ µ+ 0.1 µ+ 0.2 فشار تمرین 2:66 % confidence interval را در این مطااعه محاسبه کنید.
Hypothesis مراسم ثبت نام و آزمایشگاه تکمیلی فشار خون! فرضیه: فشار خون بالا در پسرها بیشبر یافت می شود. (فشار با سن ارتباط دارد) H1 (فرضیه ای که محقق در صدد اثبات آن است): فشار با جنس دارد. H0: فشار باجنس ارتباط ندارد. خطاي الفا يا نوع 1:با توجه به اینکه ما یک نمونه از داده ها داریم ممکن تصمیم نادرستی درباره رد یا قبول فرضیه صفر بگیریم خطای نوع 1 زمانی که فرضیه صفرواقعا درست باشد و ما آنرا رد کنیم خطای نوع 1 را با آلفا α نشان می دهند.مقادیر α معمولا 0.05 است خطاي بتا يا نوع 2:خطای نوع2 :زمانی که فرضیه صفرواقعا نادرست باشد و ما آن را قبول کنیم در خطای نوع 2 درحالی که وقعا اثری وجود دارد نتیجه می گیریم که اثری وجود ندارد.خطای نوع 2 را با β نشان می دهند . توان آزمون را با( β1- ) نشان می دهند و به صورت در صد بیان می شود.توان، احتمال رد فرضیه صفر است وقتی که نادرست باشد نمونه گیری تصادفی: 100 نفر پسر و 100 نفر جوان
Hypothesis انجام آزمایش: میانگین دخترها11.5 میانگین پسرها: 12.5 تکرار 100 بار آزمایش برای رفع خطای نمونه گیری قبول کردن خطای 5%
Hypothesis • محاسبه خطا! 5% دخترها 5% پسرها
Hypothesis وقتي H0ثابت شد: فقط می توان گفت H1 ثابت نشده است. !نتیجه واقعی مطالعه ما: P value < 0.001←significant
Hypothesis تمرین : در یک randomized trial، داروی ضد فشار خون و placebo به دو گروه مریض داده شد. نتیجه نشان داد که پس از 6 ماه که در گروه دریافت کننده داروی ضد فشار خون کاهش معنی داری در فشار خون ایجاد شده است. (P value < 0.001) در حالی که در گروه placebo کاهش فشار خون معنی داری دیده نشد. (P value = 0.8) چه اشکالی به این مطالعه وارد است؟
Hypothesis تمرین : اگر P value < 0.001 باشد شدت اختلاف بیشتر است یا P value < 0.1؟ در حقیقت P value ی معنی دار یعنی می توان نتیجه موجود را به کل جامعه تعمیم داد اما اندازه اختلاف یا شدت اختلاف را نشان نمی دهد و اساسا هدف اصلی در هر مطالعه ای تعمیم نتیجه آن به کل حامعه است. برای محاسبه شدت اختلاف از آماره های دیگری استفاده می کنیم
شدت اختلاف • Risk یا Rate: درصد افرادی از یک گروه که دچار یک عارضه شده اند. • بررسی اثرپروژسترونبالاتر از حد نرمال بر سرطان پستان سرطان پستان سالم پروژسترون بالا پروژسترون پایین • risk بروز سرطان در گروه ما با پروژسترون بالا؟ 20% • تعریف EER (Experimental Event Rate): • ریسک بروز سرطان در گروه با پروژسترون پایین ؟ 2% • تعریف CER (Control Event Rate):
شدت اختلاف • راههای محاسبه شدت اختلاف؟ • تفاوت دو ریسک • نسبت دو ریسک
شدت اختلاف • نسبت دوریسک= EER/CER=relative risk(RR) سرطان پستان سالم پروژسترون بالا پروژسترون پایین RR در این مطالعه چقدر است؟ 10 رابطه مثبت
فرمول میزان بروز بیماری در گروه 1 میزان بروز بیماری در گروه2
در مطالعات کوهورت گروه 1 در معرض یک عامل خاصی قرار دارد و گروه 2 به عنوان گروه شاهد ودر معرض عامل مورد نظر قرار ندارند. • مقدار خطر نسبی بزرگ تر از یک نشان دهنده اثر زیان آور عامل در معرض می باشد و بر عکس آن، خطر نسبی کمتر از یک نشان دهنده اثرات مفید آن عامل در معرض می باشد. • مثلا اگر گروه معرض شامل افراد سیگاری باشد و گروه شاهد شامل افراد غیر سیگاری باشد، ما یک خطر نسبی به علت سیگار را خواهیم داشت. • در یک مطالعه تعداد 200 کارگر که با پنبه نسوز کار می کردند را در نظر گرفته (گروه مورد) و تعداد 200 نفر دیگر از کارگران که از نظر سنی مشابه با گروه مورد بوده ولی در مواجهه با پنبه نسوز نبوده اند (گروه شاهد) را در نظر گرفته و آنها را به مدت 5 سال پیگیری کرده و از نظر ابتلا به بیماری ریوی مورد بررسی قرار دادیم ، تعداد 15 نفر از کارگران گروه مورد و 5 نفر از کارگران گروه شاهد دچار بیماری ریوی شده بودند. با توجه به اینکه این مطالعه به صورت آینده نگر انجام شده است ، می توان خطر نسبی را محاسبه کرد و مقدار آن برابر است با: R.R=15/200= 3 5/20
شدت اختلاف • بررسی اثر آسپیرین بر زخم معده • EER= 10/50=20% • CER=8/50=16% • RR=20/16=1.25 رابطه مثبت زخم معده سالم مصرف آسپیرین عدم مصرف آسپیرین
شدت اختلاف • بررسی اثر دادن داروی ضد فشار خون بر ایجاد عارضه (stroke-MI-death) • EER= 2/100=2% • CER=28/100=28% • RR=2/28=0.07 رابطه منفی • اگر RR برابر 1 باشد رابطه چگونه است؟ بدون عارضه با عارضه مصرف دارو عدم مصرف دارو
شدت اختلاف • بررسی اثر سیگار بر سرطان ریه • RR در این مطالعه چقدر است؟ 30/40 20/60 • با دوبرابر کردن حجم گروه کنترل: • RR = سرطان ریه سالم سیگاری = 2.25 غیر سیگاری 30/50 = 2.25 20/100
شدت اختلاف • Odds: نسبت تعداد دفعاتی که یک واقعه رخ می دهد به تعداد دفعاتی که رخ نمی دهد • Odds در گروه سرطانی= 30/20=1.5 • Odds در گروه غیر سرطانی =10/40 = 0.25 Odds ratio : نسبت odds در گروه دارای عارضه به گروه بدون عارضه • Odds ratio = 1.5/0.25= 6 سرطان ریه سالم سیگاری غیر سیگاری
شدت اختلاف • تفاوت دو ریسک: • CER:ریسک پایه • EER-CER| :ریسک مربوط به خودexposure |EER-CER|=Absolute Risk Reduction)ARR( ARI= ریسک پایه
شدت اختلاف بدون عارضه با عارضه ARR= | 2-27 |=25% ARR= | 20-16 |=4% مصرف دارو عدم مصرف دارو زخم مZعده سالم مصرف آسپیرین عدم مصرف آسپیرین
سوال؟قدم به قدم جلو مي رويم.جلسه بعد : تعاريف آماري وسايل گزارش داده ها انواع مطالعات