Download

1 / 72
720 likes | 920 Views
An Out-of-Core Sparse Symmetric Indefinite Factorization Method. Omer Meshar and Sivan Toledo Tel-Aviv University. Introduction. We present a new method for factoring a large sparse symmetric indefinite matrix. The method stores the factor on disk.

E N D
An Out-of-Core Sparse Symmetric Indefinite Factorization Method Omer Meshar and Sivan Toledo Tel-Aviv University
Introduction • We present a new method for factoring a large sparse symmetric indefinite matrix. • The method stores the factor on disk. • A dynamic I/O aware partitioning of the matrix, ensures little disk I/O and good performance.
Lecture Contents • Introduction – The problem • In-Core Factorizations • The Out-of-Core Factorization Algorithm • Tests and Results • Discussion and Conclusion
Lecture Contents • Introduction – The problem • In-Core Factorizations • The Out-of-Core Factorization Algorithm • Tests and Results • Discussion and Conclusion
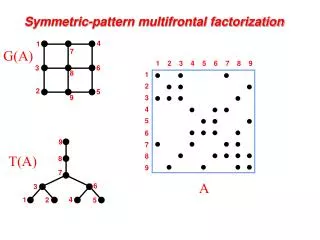
Introduction – The problem The problem: • Solve linear systems Ax=b and AX=Befficiently and accurately, where A is a sparse symmetric indefinite coefficient matrix. ? ? ? ? = ? ? ? ? ?
Introduction – The problem • A can be solved directly, by decomposing it into a product of permutation, triangular, diagonal and orthogonal factors. • It can also be solved iteratively. • Our method is direct and decomposes A into PLDLTPT where: P - permutationL- triangular D - block-diagonal with 1-by-1 and 2-by-2 blocks.
Introduction - continued • The factor Lcan be much denser, thus larger, than A. • It may not fit in memory. • In this case we can: • Use an out-of-core method. • Switch to an iterative method. • Get a machine with a larger memory.
Introduction - continued • The main difference between in-core and out-of-core algorithms, is in scheduling the operations. • An out-of-core algorithm must satisfy both the data-flow constraints and minimize the I/O. • Good utilization of in-memory data is the main challenge in design of out-of-core methods.
Lecture Contents • Introduction – The problem • In-Core Factorizations • The Out-of-Core Factorization Algorithm • Tests and Results • Discussion and Conclusion
In-Core Factorizations • Before going into the out-of-core algorithm, we wrote two in-core methods, based on two different approaches: • The multifrontal approach • The left-looking approach
In-Core Factorizations - continued • All our factorization methods use supernodal decomposition and a supernodal elimination tree. • They all use the same pivot strategy, explained later. • The pivot strategy either selects a 1-by-1 block pivot, or a 2-by-2 block pivot, or fails to find a pivot for the current column – and rejects it to the parent supernode.
In-Core Factorizations - continued • The most common sparse symmetric indefinite factorizations are multifrontal. • Previous research on sparse out-of-core factorizations, suggests that left-looking methods are more efficient. • The left-looking indefinite approach was never documented.
In-Core Factorizations - continued • The difference between the approaches is in the way updates are represented and computed. • This also affects the way the method treats rejected columns. Skip
In-Core Factorizations - continued • The rejected columns are treated in the following way: A supernode (J) with 3-by-3 diagonal block and 4-by-3 sub-diagonal (update) block, after it was factored.
In-Core Factorizations - continued • The rejected columns are treated in the following way: J’s parent (K) with 5-by-5 diagonal block, before factorization.
In-Core Factorizations - continued • The rejected columns are treated in the following way: We assume that the last column in J was rejected.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach:
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: Update matrix (4-by-4) created after J’s factorization
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: The rejected columns move to the sub-diagonal block and to the update matrix.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: The rejected columns move to the sub-diagonal block and to the update matrix.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: The rejected columns move to the sub-diagonal block and to the update matrix.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: The rejected columns move to the sub-diagonal block and to the update matrix.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: When K is being factored, we find out we need updates from J, so we take J’s update matrix
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: and update K, using a method called Extend-Add.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: and update K, using a method called Extend-Add.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: Now K is ready and can be factored
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the multifrontal approach: Now K is ready and can be factored
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach:
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: Instead of moving the rejected columns to the update matrix, they stay in J until J’s first update (to its parent)
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: It’s K’s turn to be factored, and we find out we need updates from J (K is J’s parent)
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: It’s J’s first (direct) update, so it still may have some rejected columns – they are now moved to its parent.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: It’s J’s first update, so it still may have some rejected columns – they are now moved to its parent.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: It’s J’s first update, so it still may have some rejected columns – they are now moved to its parent.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: Next, K is being updated by J’s sub-diagonal block, as usual.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: Next K is being updated, as usual, by J’s sub-diagonal block.
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: Now K is ready and can be factored
In-Core Factorizations - continued • The rejected columns are treated in the following way: • In the left-looking approach: Now K is ready and can be factored
In-Core Factorizations – dense kernel • LAPACK’S dense indefinite factorization methods, like DSYTRF, cannot be used when factoring a supernode of a sparse matrix. • It uses Bunch-Kaufman’s pivot strategy, which does not differ between the diagonal and the sub-diagonal (update) blocks.
In-Core Factorizations – dense kernel • Therefore, we needed to write our own dense indefinite factorization kernel. • It is similar to DSYTRF: It is blocked and it uses the level 3 BLAS in the same way. • The main difference is in the pivot strategy.
is the growth parameter, set to 0.001 Entry with max value in 1st column of diagonal block Entry with max value in 1st column Max value in qth column Max value in 1st column (not including α11) In-Core Factorizations – pivot strategy • We used the following pivot strategy, taken from Ashcraft, Grimes and Lewis (1998): Skip
In-Core Factorizations – pivot strategy • We used the following pivot strategy, taken from Ashcraft, Grimes and Lewis (1998):
In-Core Factorizations – pivot strategy • We used the following pivot strategy, taken from Ashcraft, Grimes and Lewis (1998): if γ1=0 then the first column is already factored
In-Core Factorizations – pivot strategy • We used the following pivot strategy, taken from Ashcraft, Grimes and Lewis (1998): if γ1=0 then the first column is already factored else if |a11| ≥ γ1 then use a11 as a 1-by-1 pivot
In-Core Factorizations – pivot strategy • We used the following pivot strategy, taken from Ashcraft, Grimes and Lewis (1998): if γ1=0 then the first column is already factored else if |a11| ≥ γ1 then use a11 as a 1-by-1 pivot else if |aqq| ≥ γq then use aqq as a 1-by-1 pivot
In-Core Factorizations – pivot strategy • We used the following pivot strategy, taken from Ashcraft, Grimes and Lewis (1998): if γ1=0 then the first column is already factored else if |a11| ≥ γ1 then use a11 as a 1-by-1 pivot else if |aqq| ≥ γq then use aqq as a 1-by-1 pivot else if max{|aqq| γ1+|aq1| γq, |a11| γq+|aqq| γ1} ≤|a11aqq-a2q1|/ then use as a 2-by-2 pivot
In-Core Factorizations – pivot strategy • We used the following pivot strategy, taken from Ashcraft, Grimes and Lewis (1998): if γ1=0 then the first column is already factored else if |a11| ≥ γ1 then use a11 as a 1-by-1 pivot else if |aqq| ≥ γ1 then use aqq as a 1-by-1 pivot else if max{|aqq|γ1+|aq1| γq, |a11| γq+|aqq| γ1}≤ |a11aqq-a2q1|/ then use as a 2-by-2 pivot else no pivot found; repeat search using next column
Lecture Contents • Introduction – The problem • In-Core Factorizations • The Out-of-Core Factorization Algorithm • Tests and Results • Discussion and Conclusion
The Out-of-Core Factorization Algorithm • The method is based on a sparse left-looking formulation of the LDLTfactorization. • It partitions the matrix into blocks called panels to achieve I/O efficiency. • It is done dynamically, during the numerical factorization, to account for pivoting.
The Out-of-Core Factorization Algorithm - continued • The algorithm works in phases: • At the beginning of each phase, the main memory contains no supernodes. • All the factored supernodes are stored on disk. • We find a panel, a forest of connected leaf subtrees of the residual etree.
The Out-of-Core Factorization Algorithm - continued • For example: • The panel fits in main memory: • We update the structure. • Use 75% of the available memory. • We may need to write to disk a supernode more than once.