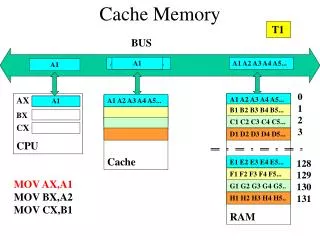
Efficient Data Upload and Partitioning for HDFS with Tablet Server Integration
This document outlines a structured approach to upload and partition data into HDFS (Hadoop Distributed File System) using the Tablet Server. It covers the entire process from closing the Tablet Server and initiating a batch upload to flushing client memory cache to local disk. The procedure details the creation of local map files, the importance of sorting data, and generating row keys based on partitioned records. The outcome is optimized tablet management, ensuring sorted data is effectively handled for enhanced performance within distributed systems.
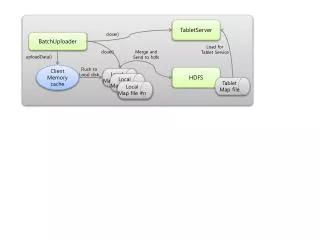

Efficient Data Upload and Partitioning for HDFS with Tablet Server Integration
E N D
Presentation Transcript
TabletServer close() BatchUploader Load for Tablet Service close() Merge and Send to hdfs uploadData() Local Map file #1 Local Map file #2 Client Memory cache Flush to Local disk HDFS Local Map file #n Tablet Map file
1단계: Partition 2단계: Upload not sorted(in hdfs) not sorted(in hdfs) … … … … … … Map Map Map Map Map Map Partitioner Partitioner Partitioner 테이블의 Partition 정보 이용 일부 레코드에 대해서만 Key parsring후 Key만 write Sorted keys Sorted data Sorted data Sorted data Sorted data Reduce Reduce Reduce Reduce Reduce 특정 tablet으로 업로드 정렬된 key 정보를 이용 rowKey의 목록을 만든 후 Table을 생성한다. N개의 tablet으로 분리된 테이블
not sorted(in hdfs) … … … 분리되지않은 Table Map Map Map Partitioner Partitioner Partitioner addTablet후 upload Sorted data Sorted data Sorted data Sorted data Reduce Reduce Reduce Reduce