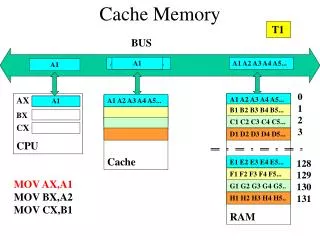
Cache Memory
Cache Memory. Outline. General concepts 3 ways to organize cache memory Issues with writes Write cache friendly codes Cache mountain Suggested Reading: 6.4, 6.5, 6.6. 6.4 Cache Memories. Cache Memory. History At very beginning, 3 levels Registers, main memory, disk storage


Cache Memory
E N D
Presentation Transcript
Outline • General concepts • 3 ways to organize cache memory • Issues with writes • Write cache friendly codes • Cache mountain • Suggested Reading: 6.4, 6.5, 6.6
Cache Memory • History • At very beginning, 3 levels • Registers, main memory, disk storage • 10 years later, 4 levels • Register, SRAM cache, main DRAM memory, disk storage • Modern processor, 4~5 levels • Registers, SRAM L1, L2(,L3) cache, main DRAM memory, disk storage • Cache memories • are small, fast SRAM-based memories • are managed by hardware automatically • can be on-chip, on-die, off-chip
Cache MemoryFigure 6.24 P488 CPU chip register file ALU L1 cache cache bus system bus memory bus main memory L2 cache bus interface I/O bridge
Cache Memory • L1 cache is on-chip • L2 cache is off-chip several years ago • L3 cache can be off-chip or on-chip • CPU looks first for data in L1, then in L2, then in main memory • Hold frequently accessed blocks of main memory are in caches
The tiny, very fast CPU register file has room for four 4-byte words. The transfer unit between the CPU register file and the cache is a 4-byte block. line 0 The small fast L1 cache has room for two 4-word blocks. line 1 The transfer unit between the cache and main memory is a 4-word block (16 bytes). block 10 a b c d ... The big slow main memory has room for many 4-word blocks. block 21 p q r s ... block 30 w x y z ... Inserting an L1 cache between the CPU and main memory
t tag bits per line 1 valid bit per line B = 2b bytes per cache block Cache is an array of sets. Each set contains one or more lines. Each line holds a block of data. valid tag 0 1 • • • B–1 E lines per set • • • set 0: valid tag 0 1 • • • B–1 valid tag 0 1 • • • B–1 • • • set 1: S = 2s sets valid tag 0 1 • • • B–1 • • • valid tag 0 1 • • • B–1 • • • set S-1: valid tag 0 1 • • • B–1 pp.488 6.4.1 Generic Cache Memory OrganizationFigure 6.25 P488
Address A: b bits t bits s bits m-1 0 v tag 0 1 • • • B–1 • • • set 0: <tag> <set index> <block offset> v tag 0 1 • • • B–1 v tag 0 1 • • • B–1 • • • set 1: v tag 0 1 • • • B–1 The word at address A is in the cache if the tag bits in one of the <valid> lines in set <set index> match <tag>. The word contents begin at offset <block offset> bytes from the beginning of the block. • • • v tag 0 1 • • • B–1 • • • set S-1: v tag 0 1 • • • B–1 Addressing cachesFigure 6.25 P488
valid tag cache block set 0: E=1 lines per set cache block valid tag set 1: • • • cache block valid tag set S-1: 6.4.2 Direct-mapped cacheFigure 6.27 P490 • Simplest kind of cache • Characterized by exactly one line per set.
valid tag set 0: cache block selected set cache block valid tag set 1: • • • t bits s bits b bits cache block valid tag set S-1: 0 0 0 0 1 tag set index block offset m-1 0 Accessing direct-mapped cachesFigure 6.28 P491 • Set selection • Use the set index bits to determine the set of interest
Accessing direct-mapped caches • Line matching and word extraction • find a valid line in the selected set with a matching tag (line matching) • then extract the word (word selection)
=1? (1) The valid bit must be set 0 1 2 3 4 5 6 7 1 0110 w0 w1 w2 w3 selected set (i): (2) The tag bits in the cache line must match the tag bits in the address = ? (3) If (1) and (2), then cache hit, and block offset selects starting byte. t bits s bits b bits 0110 i 100 tag set index block offset m-1 0 Accessing direct-mapped cachesFigure 6.29 P491
Line Replacement on Misses in Directed Caches • If cache misses • Retrieve the requested block from the next level in the memory hierarchy • Store the new block in one of the cache lines of the set indicated by the set index bits
Line Replacement on Misses in Directed Caches • If the set is full of valid cache lines • One of the existing lines must be evicted • For a direct-mapped caches • Each set contains only one line • Current line is replaced by the newly fetched line
Direct-mapped cache simulation P492 • M=16 byte addresses • B=2 bytes/block, S=4 sets, E=1 entry/set
M=16 byte addresses, B=2 bytes/block, S=4 sets, E=1 entry/set Address trace (reads): 0 [0000] 1 [0001] 13 [1101] 8 [1000] 0 [0000] t=1 s=2 b=1 x xx x 0 [0000] (miss) 13 [1101] (miss) v tag data v tag data 1 0 m[1] m[0] 1 0 m[1] m[0] (1) (2) 1 1 m[13] m[12] 0 [0000] (miss) 8 [1000] (miss) v tag data v tag data 1 0 m[1] m[0] 1 1 m[9] m[8] (4) (3) 1 1 m[13] m[12] 1 1 m[13] m[12] Direct-mapped cache simulation P493
High-Order Bit Indexing Middle-Order Bit Indexing 4-line Cache 00 0000 0000 01 0001 0001 10 0010 0010 11 0011 0011 0100 0100 0101 0101 0110 0110 0111 0111 1000 1000 1001 1001 1010 1010 1011 1011 1100 1100 1101 1101 1110 1110 1111 1111 Why use middle bits as index? • High-Order Bit Indexing • Adjacent memory lines would map to same cache entry • Poor use of spatial locality • Middle-Order Bit Indexing • Consecutive memory lines map to different cache lines • Can hold C-byte region of address space in cache at one time Figure 6.31 P497
valid tag cache block set 0: E=2 lines per set valid tag cache block valid tag cache block set 1: valid tag cache block • • • valid tag cache block set S-1: valid tag cache block 6.4.3 Set associative caches • Characterized by more than one line per set Figure 6.32 P498
valid tag cache block set 0: cache block valid tag valid tag cache block Selected set set 1: cache block valid tag • • • cache block valid tag set S-1: t bits s bits b bits cache block valid tag 0 0 0 0 1 m-1 0 tag set index block offset Accessing set associative caches • Set selection • identical to direct-mapped cache Figure 6.33 P498
(1) The valid bit must be set. =1? 0 1 2 3 4 5 6 7 1 1001 selected set (i): 1 0110 w0 w1 w2 w3 (3) If (1) and (2), then cache hit, and block offset selects starting byte. (2) The tag bits in one of the cache lines must match the tag bits in the address = ? t bits s bits b bits 0110 i 100 m-1 0 tag set index block offset Accessing set associative caches • Line matching and word selection • must compare the tag in each valid line in the selected set. Figure 6.34 P499
valid tag cache block cache block valid tag set 0: E=C/B lines in the one and only set … valid tag cache block t bits b bits tag block offset 6.4.4 Fully associative caches • Characterized by all of the lines in the only one set • No set index bits in the address Figure 6.35 P500 Figure 6.36 P500
(1) The valid bit must be set. =1? 0 1 2 3 4 5 6 7 1 1001 0 0110 w0 w1 w2 w3 1 0110 0 1110 (3) If (1) and (2), then cache hit, and block offset selects starting byte. (2) The tag bits in one of the cache lines must match the tag bits in the address = ? t bits b bits 0110 100 m-1 0 tag block offset Accessing set associative caches • Word selection • must compare the tag in each valid line Figure 6.37 P500
6.4.5 Issues with Writes • Write hits • 1) Write through • Cache updates its copy • Immediately writes the corresponding cache block to memory • 2) Write back • Defers the memory update as long as possible • Writing the updated block to memory only when it is evicted from the cache • Maintains a dirty bit for each cache line
Issues with Writes • Write misses • 1) Write-allocate • Loads the corresponding memory block into the cache • Then updates the cache block • 2) No-write-allocate • Bypasses the cache • Writes the word directly to memory • Combination • Write through, no-write-allocate • Write back, write-allocate
Options:separate data and instruction caches, or a unified cache Processor Memory TLB disk L1 D-cache L2 Cache regs L1 I-cache size: speed: $/Mbyte: line size: 8-64 KB 3 ns 32 B 1-4MB SRAM 6 ns $100/MB 32 B 128 MB DRAM 60 ns $1.50/MB 8 KB 30 GB 8 ms $0.05/MB larger, slower, cheaper larger line size, higher associativity, more likely to write back 6.4.6 Multi-level caches Figure 6.38 P504
6.4.7 Cache performance metrics P505 • Miss Rate • fraction of memory references not found in cache (misses/references) • Typical numbers: 3-10% for L1 • Hit Rate • fraction of memory references found in cache (1 - miss rate)
Cache performance metrics • Hit Time • time to deliver a line in the cache to the processor (includes time to determine whether the line is in the cache) • Typical numbers: 1-2 clock cycle for L1 5-10 clock cycles for L2 • Miss Penalty • additional time required because of a miss • Typically 25-100 cycles for main memory
Cache performance metrics P505 • 1> Cache size • Hit rate vs. hit time • 2> Block size • Spatial locality vs. temporal locality • 3> Associativity • Thrashing • Cost • Speed • Miss penalty • 4> Write strategy • Simple, read misses, fewer transfer
Writing Cache-Friendly Code • Principles • Programs with better locality will tend to have lower miss rates • Programs with lower miss rates will tend to run faster than programs with higher miss rates
Writing Cache-Friendly Code • Basic approach • Make the common case go fast • Programs often spend most of their time in a few core functions. • These functions often spend most of their time in a few loops • Minimize the number of cache misses in each inner loop • All things being equal
int sumvec(int v[N]) { int i, sum = 0 ; for (i = 0 ; i < N ; i++) sum += v[i] ; return sum ; } Temporal locality, These variables are usually put in registers v[i] i=0 i= 1 i= 2 i= 3 i= 4 i= 5 i= 6 i= 7 Access order, [h]it or [m]iss 1[m] 2[h] 3[h] 4[h] 5[m] 6[h] 7[h] 8[h] Writing Cache-Friendly Code P507
Writing cache-friendly code • Temporal locality • Repeated references to local variables are good because the compiler can cache them in the register file
Writing cache-friendly code • Spatial locality • Stride-1 references patterns are good because caches at all levels of the memory hierarchy store data as contiguous blocks • Spatial locality is especially important in programs that operate on multidimensional arrays
Writing cache-friendly code P508 • Example (M=4, N=8, 10cycles/iter) int sumvec(int a[M][N]) { int i, j, sum = 0 ; for (i = 0 ; i < M ; i++) for ( j = 0 ; j < N ; j++ ) sum += a[i][j] ; return sum ; }
Writing cache-friendly code P508 • Example (M=4, N=8, 20cycles/iter) int sumvec(int v[M][N]) { int i, j, sum = 0 ; for ( j = 0 ; j < N ; j++ ) for ( i = 0 ; i < M ; i++ ) sum += v[i][j] ; return sum ; }
6.6 Putting it Together: The Impact of Caches on Program Performance 6.6.1 The Memory Mountain
The Memory Mountain P512 • Read throughput (read bandwidth) • The rate that a program reads data from the memory system • Memory mountain • A two-dimensional function of read bandwidth versus temporal and spatial locality • Characterizes the capabilities of the memory system for each computer
Memory mountain main routine Figure 6.41 P513 /* mountain.c - Generate the memory mountain. */ #define MINBYTES (1 << 10) /* Working set size ranges from 1 KB */ #define MAXBYTES (1 << 23) /* ... up to 8 MB */ #define MAXSTRIDE 16 /* Strides range from 1 to 16 */ #define MAXELEMS MAXBYTES/sizeof(int) int data[MAXELEMS]; /* The array we'll be traversing */
Memory mountain main routine int main() { int size; /* Working set size (in bytes) */ int stride; /* Stride (in array elements) */ double Mhz; /* Clock frequency */ init_data(data, MAXELEMS); /* Initialize each element in data to 1 */ Mhz = mhz(0); /* Estimate the clock frequency */
Memory mountain main routine for (size = MAXBYTES; size >= MINBYTES; size >>= 1) { for (stride = 1; stride <= MAXSTRIDE; stride++) printf("%.1f\t", run(size, stride, Mhz)); printf("\n"); } exit(0); }
Memory mountain test functionFigure 6.40 P512 /* The test function */ void test (int elems, int stride) { int i, result = 0; volatile int sink; for (i = 0; i < elems; i += stride) result += data[i]; sink = result; /* So compiler doesn't optimize away the loop */ }
Memory mountain test function /* Run test (elems, stride) and return read throughput (MB/s) */ double run (int size, int stride, double Mhz) { double cycles; int elems = size / sizeof(int); test (elems, stride); /* warm up the cache */ cycles = fcyc2(test, elems, stride, 0); /* call test (elems,stride) */ return (size / stride) / (cycles / Mhz); /* convert cycles to MB/s */ }
The Memory Mountain • Data • Size • MAXBYTES(8M) bytes or MAXELEMS(2M) words • Partially accessed • Working set: from 8MB to 1KB • Stride: from 1 to 16