Download
1 / 24
380 likes | 827 Views
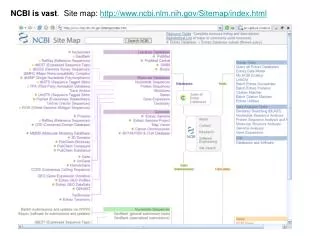
NCBI is vast . Site map: http://www.ncbi.nlm.nih.gov/Sitemap/index.html. NCBI database overview. http://www.ncbi.nih.gov/Database/datamodel/index.html. Some things to keep in mind about NCBI databases:. Scope of data can be intimidating. Just need a little orientation.

E N D
NCBI is vast. Site map: http://www.ncbi.nlm.nih.gov/Sitemap/index.html
NCBI database overview http://www.ncbi.nih.gov/Database/datamodel/index.html
Some things to keep in mind about NCBI databases: • Scope of data can be intimidating. Just need a little orientation. • Constantly growing and evolving • Vestigial features: • some things there for historical reasons – not useful anymore • some things have changed or lost meaning • example: accession numbers: • in past, they provided some information about sequence • now, they’re just a unique identifier • When in doubt: resort to the abundant help pages
Genbank – Foundation of NCBI databases & resources • DB of allprimary DNAsequences • Contains everything: • genomes • plasmids • synthetic sequences • fragments (partial gene seqs) • ESTs • STSs • Many redundant/overlapping sequences. • Released every 2 months. • Most journals require submission of new sequences to Genbank http://www.ncbi.nlm.nih.gov/Genbank/index.html
Genbank: composed of 3 nucleotide databases http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?CMD=Index&DB=nucleotide
International Nucleotide Sequence Database Collaboration • All nucleotide sequences shared between three sites: • Genbank (US) • EMBL (Europe) – European Molecular Biology Laboratory • DDBJ (Japan) – DNA Data Bank of Japan • Since 1986 have exchanged nucleotide records daily: • Data stored in common format (machine & human readable) • ASN.1 format for machine exchange • Genbank record format for human reading • Can access/submit data from any of the sites
Genbank records are more than raw sequence data • Each record includes annotations of sequence – basic information about: • gene structure • coding features • regulatory sites • functions • db cross references • citations • authorship (submitter) • date • identifiers • etc.
Chromosomal DNA region containing CFTR gene Try it – look up via Gene db
Locus name: unique identifier. Usually just the accession number. Seq length: # of nucleotides (bp) in the record Molecule type Revision date: date of most recent update to sequence record Genbank division: Not that important. Tells which FTP site record is stored
Definition: basic information about the sequence Accession number: Unique identifier for each nucleotide sequence. (May have multiple versions as separate records.) Region: refers to subsection of the complete sequence • GI: GeneInfo Identifier. Also a unique sequence record identifier. • Redundant identifier with Version number. • Assigned consecutively with each new sequence deposit or update. • New GI for any deposit or change. • Version: Format is “ACC#.VER#”. • Version numbers are incremented with each sequence revision. Accession number doesn’t change. • Unique for each sequence record.
Unique nucleotide sequence Sequence records Accession Number Version number GI (GeneInfo identifier) Version number GI (GeneInfo identifier) Locus name Version number GI (GeneInfo identifier)
Source: free form information. Usually scientific and common name of organism Organism: scientific name and taxonomic position Reference: Journal references. Numbered sequentially for cross reference. Ordered chronologically
location: nucleotide position. Can use operators: (.), (..), (>), (<), (join), (completment), etc. feature_key: up to 20 letters or numbers • Feature Table: • Contains multiple entries in the form: • Feature key - a single word or abbreviation indicating function type • Location - instructions for finding the feature • Qualifiers - auxiliary information about a feature qualifiers: slash (/), then equal sign (=), then text description (in quotes of multiple lines)
/db_xref: cross references into other related databases • 5’ to 3’ sequence data. • starts after the ORIGIN key • Locations and qualifiers in the feature table refer to this • Numbering is only relevant to this particular record For a detailed example and description of Genbank flat file format see: http://www.ncbi.nlm.nih.gov/Sitemap/samplerecord.html For more information on Feature Table syntax see: http://www.ncbi.nlm.nih.gov/projects/collab/FT/index.html
FASTA format: useful for raw, unannotated sequence Try it – select FASTA from display menu
Searching Genbank Entrez (primary route). Includes CoreNucleotide, dbEST, dbSTS, and dbGSS. http://www.ncbi.nlm.nih.gov/gquery/gquery.fcgi Can access Entrez by selecting nucleotide from virtually any search box menu: http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=Nucleotide BLAST (select “nr” for comprehensive nucleotide search) http://www.ncbi.nlm.nih.gov/BLAST/ Example: try blasting CFTR mRNA against mouse genome Direct search of component databases (dbEST, dbSTS, dbGSS) http://www.ncbi.nlm.nih.gov/Genbank/GenbankSearch.html
RefSeq – a derivative database • Curated, non-redundant database: • includes genomic DNA, transcript (RNA), and protein products, for major organisms. • derived from GenBank primary data, and the annotation is computational, from published literature, or from domain experts. • http://www.ncbi.nlm.nih.gov/RefSeq/ • Why RefSeq when already have Genbank? • Genbank is a mess – overlapping, partial, redundant sequences • Example: Search CFTR (human) in RefSeq (via Gene DB) vs. Genbank (via nucleotide query)
The main features of the RefSeq collection include: • non-redundant • explicitly linked nucleotide and protein sequences • data validation and format consistency • distinct accession series • ongoing curation by NCBI staff and collaborators:updates to reflect current knowledge of sequence data and biology • March 20, 2006: RefSeq Release 16: • Proteins: 2,520,485 • Organisms: 3397 • RefSeq records have a standard accession number format (start with N or X) • Examples:
Searching RefSeq: • Gene DB – access from pull-down menu next to search box • Example: CFTR search • Entrez limits: restrict nucleotide or protein searches to RefSeq • Using Entrez Limits: More info on RefSeq and searching: http://www.ncbi.nlm.nih.gov/RefSeq/key.html
Third Party Annotation (TPA) Database • User-provided annotation for sequence data • Derived from GenBank primary data. • Kind of like Refseq, but built on user-submissions. • To help with curation bottleneck at NCBI – take advantage of the community of expertise and knowledge. http://www.ncbi.nih.gov/Genbank/TPA.html
Other useful DBs at NCBI (many are derivative DBs) Access via Entrez: http://www.ncbi.nlm.nih.gov/gquery/gquery.fcgi Genes: curated gene-centric summary of gene information and related sequences Unigene: gene-centered clusters of transcript sequences from GenBank Genomes: whole genome sequences – no nucleotide fragments Taxonomy: classifications of organisms Example: find relatives of homosapiens and blast CFTR Map Viewer: graphical display of gene records on chromosome OMIM: Online Mendelian Inheritance in Man. Catalog of human genetic disorders. dbSNP: database of Single Nucleotide Polymorphisms Pubmed: database of biomedically-related journal abstracts And many more. See Entrez (All Datbases link from NCBI main page).
Additional NCBI Databases and Tools http://www.ncbi.nlm.nih.gov/Sitemap/ResourceGuide.html
Getting help: General help with NCBI searching: http://www.ncbi.nlm.nih.gov/entrez/query/static/help/helpdoc.html Handbook: http://www.ncbi.nlm.nih.gov/books/bv.fcgi?call=bv.View..ShowTOC&rid=handbook.TOC&depth=2 NCBI: http://www.ncbi.nlm.nih.gov/About/index.html Resource Guide/Overview: http://www.ncbi.nlm.nih.gov/Sitemap/ResourceGuide.html Tools: http://www.ncbi.nlm.nih.gov/Tools/ Tutorials and Exercises: http://www.ncbi.nlm.nih.gov/Class/FieldGuide/
Other useful databases: KEGG (Kyoto Encyclopedia of Genes and Genomes) http://www.genome.jp/kegg/ Ecocyc (Encyclopedia of E. coli Genes and Metabolism) http://www.ecocyc.com/ BIND (Biomolecuar INteraction Database) http://www.bind.ca/Action UCSC Genome Browser http://genome.ucsc.edu/ TIGR databases http://www.tigr.org/db.shtml Many Microbes Microarray Database http://m3d.bu.edu And the list goes on and on and on …