Enhancing Fault-Tolerance in Wide-Area Service Composition through Hierarchical Monitoring
This paper addresses the challenges of monitoring and optimal operator placement in wide-area service compositions. It introduces a novel approach to fault tolerance by utilizing a hierarchical monitoring infrastructure that distinguishes between cluster-level and wide-area failures. By leveraging clustered operators, the proposed model enhances quick fail-over capabilities while ensuring efficient resource management. Applications for this system include media streaming and communication services. The evaluation focuses on latency in path construction and failure recovery times, providing insights into the efficiency and scalability of the design.

Enhancing Fault-Tolerance in Wide-Area Service Composition through Hierarchical Monitoring
E N D
Presentation Transcript
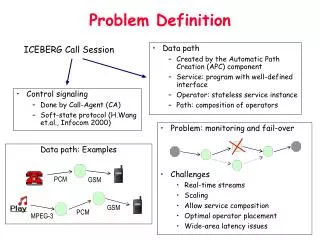
GSM PCM MPEG-3 PCM GSM Problem Definition ICEBERG Call Session • Data path • Created by the Automatic Path Creation (APC) component • Service: program with well-defined interface • Operator: stateless service instance • Path: composition of operators • Control signaling • Done by Call-Agent (CA) • Soft-state protocol (H.Wang et.al., Infocom 2000) • Problem: monitoring and fail-over • Challenges • Real-time streams • Scaling • Allow service composition • Optimal operator placement • Wide-area latency issues Data path: Examples
Related Work • Transcoding platforms for client adaptation • Active Services (E. Amir), TACC (A. Fox) • AS: Composition not considered • TACC: no long-lived sessions • What happens on cluster failure? • Optimal operator placement not addressed • Fault-tolerant networks • Telephone, ATM, Supercomputing: link-level failure detection • Will not work for application-level operation on the Internet • Distributed computing platforms • Fault-tolerant computing, State recovery protocols • Monitoring and load-balancing (Remulac, N/w Weather Service) • We do not require strict consistency (assumption) • Fail-over in our case – almost like handoffs
Cluster Destination Source Manager Cluster 2 Destination Cluster 1 Source Single-cluster vs. Wide-Area paths • Single-cluster-based approach • Path contained within single cluster running APC • Appealing since we can reuse a lot mechanisms from TACC/AS • Cluster-wide manager(s) to monitor and restore operators (workers/servents) • Wide-area approach • Multiple clusters of operators • Allow composition across clusters
Single-cluster-based approach Tight control possible Quick fail-over Communication between two adjacent operators is easier Entire path fails on cluster failure May result in non-optimal network resource usage Difficulties with proprietary operators, special hardware-based operators Wide-area approach Need a cross-cluster monitoring mechanism Wide-area latency issues Can handle cluster-failure or cut-off Allows better resource management (optimal operator placement) Orthogonality in fault-tolerance: geographical, across ISPs More flexible in terms of deployment Comparing the two approaches
Monitoring and Fail-over inWide-area Service Composition Bhaskaran Raman, Z. Morley Mao ICEBERG, EECS, U.C.Berkeley Service 3 Service 2 Service 1
Wide-Area Approach • Monitoring the path • Centralized Lack of tight control Sacrifice quick recovery • Distributed Complications (how to do?) • Hierarchical approach to fault-tolerance • Within cluster: • Handle failure within cluster if possible • Cluster managers to do this • Can be done quickly because of tight control within cluster • Across clusters: • Separate cluster failure detection mechanism • Need monitoring infrastructure • This is appropriate since: • Pr(process-failure) > Pr(machine-failure) > Pr(cluster-failure)
Cluster Cluster Manager Control Path Wide-Area Approach (Continued) • Network of clusters • Control paths for cluster monitoring • Replicated across manager machines in the cluster-pair • Replicated in the wide-area • To handle machine and network failures • Aggregated control paths for scaling • Fits in well with ICEBERG model of iPOP clusters
Status and Plans • Finished the first prototype using Ninja 1.5 (iSpace) • Supports the following applications: • Listening to MPEG-3 songs from a Jukebox using cell-phone • Communication between a VAT and a cell-phone • Retrieving emails using cell-phone • Failure recovery model: • Partial path repair when possible • Detects process-level failure • Proposed evaluation mechanisms • Wide-area test-bed: between Berkeley and TU-Berlin • Trace-driven simulation of failure recovery algorithms • Evaluation criteria: • Path construction latency • Failure-recovery time • Scaling in number of paths, control mechanism overhead • Ease of service composition
Summary • Monitoring/fail-over infrastructure crucial for data paths • Hierarchical monitoring to align with failure probabilities • Application to other replicated services? • having loose consistency semantics • E.g., Internet video servers, OceanStore storage servers, Web-cache servers • Interesting research issues: • Cross-cluster monitoring • Aggregated, hierarchical monitoring • Shadow data paths • Replicated control paths • Feasibility of real-time operator recovery • Optimal operator placement