Human Language Technology (HLT) and Knowledge Acquisition for the Semantic Web: a Tutorial
1.44k likes | 1.66k Views
Human Language Technology (HLT) and Knowledge Acquisition for the Semantic Web: a Tutorial Diana Maynard (University of Sheffield) Julien Nioche (University of Sheffield) Marta Sabou (Vrije Universiteit Amsterdam) Johanna V ö lker (AIFB) Atanas Kiryakov (Ontotext Lab, Sirma AI)

Human Language Technology (HLT) and Knowledge Acquisition for the Semantic Web: a Tutorial
E N D
Presentation Transcript
Human Language Technology (HLT) and Knowledge Acquisition for the Semantic Web: a Tutorial Diana Maynard (University of Sheffield) Julien Nioche (University of Sheffield) Marta Sabou (Vrije Universiteit Amsterdam) Johanna Völker (AIFB) Atanas Kiryakov (Ontotext Lab, Sirma AI) EKAW 2006 [This work has been supported by SEKT (http://sekt.semanticweb.org/) andKnowledgeWeb (http://knowledgeweb.semanticweb.org/ ]
Structure of the Tutorial • Motivation, background • GATE overview • Information Extraction • GATE’s HLT components • IE and the Semantic Web • Ontology learning with Text2Onto • Focused ontology learning • Massive Semantic Annotation 2
Aims of this tutorial • Investigates some technical aspects of HLT for the SW and brings this methodology closer to non-HLT experts • Provides an introduction to an HLT toolkit (GATE) • Demonstrates using HLT for automating SW-specific knowledge acquisition tasks such as: • Semantic annotation • Ontology learning • Ontology population 3
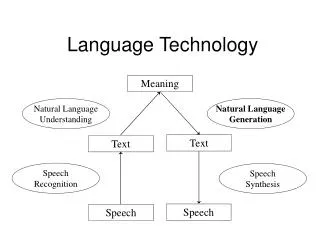
SomeTerminology • Semantic annotation – annotate in the texts all mentions of instances relating to concepts in the ontology • Ontology learning – automatically derive an ontology from texts • Ontology population – given an ontology, populate the concepts with instances derived automatically from a text 4
Semantic Annotation: Motivation • Semantic metadata extraction and annotation is the glue that ties ontologies into document spaces • Metadata is the link between knowledge and its management • Manual metadata production cost is too high • State-of-the-art in automatic annotation needs extending to target ontologies and scale to industrial document stores and the web 5
Challenge of the Semantic Web • The Semantic Web requires machine processable, repurposable data to complement hypertext • Once metadata is attached to documents, they become much more useful and more easily processable, e.g. for categorising, finding relevant information, and monitoring • Such metadata can be divided into two types of information: explicit and implicit. 6
Metadata extraction • Explicit metadata extraction involves information describing the document, such as that contained in the header information of HTML documents (titles, abstracts, authors, creation date, etc.) • Implicit metadata extraction involves semantic information deduced from the text, i.e. endogenous information such as names of entities and relations contained in the text. This essentially involves Information Extraction techniques, often with the help of an ontology. 7
Ontology Learning and Population: Motivation • Creating and populating ontologies manually is a very time-consuming and labour-intensive task • It requires both domain and ontology experts • Manually created ontologies are generally not compatible with other ontologies, so reduce interoperability and reuse • Manual methods are impossible with very large amounts of data 8
Semantic Annotation vs Ontology Population • Semantic Annotation • Mentions of instances in the text are annotated wrt concepts (classes) in the ontology. • Requires that instances are disambiguated. • It is the text which is modified. • Ontology Population • Generates new instances in an ontology from a text. • Links unique mentions of instances in the text to instances of concepts in the ontology. • Instances must be not only disambiguated but also co-reference between them must be established. • It is the ontology which is modified. 9
Structure of the Tutorial • Motivation, background • GATE overview • Information Extraction • GATE’s HLT components • IE and the Semantic Web • Ontology learning with Text2Onto • Focused ontology learning • Massive Semantic Annotation 10
GATE : an open source framework for HLT • GATE (General Architecture for Text Engineering) is a framework for language processing (http://gate.ac.uk) • Open Source (LGPL licence) • Hosted on SourceForgehttp://sourceforge.net/projects/gate • Ten years old (!), with 1000s of users at 100s of sites • Current version 3.1 11
4 sides to the story • Anarchitecture: A macro-level organisational picture for HLT software systems. • Aframework: For programmers, GATE is an object-oriented class library that implements the architecture. • Adevelopment environment: For language engineers, computational linguists et al, a graphical development environment. • Acommunityof users and contributors 12
Architectural principles • Non-prescriptive, theory neutral(strength and weakness) • Re-use, interoperation, not reimplementation (e.g. diverse XML support, integration of Protégé, Jena, Yale...) • (Almost) everything is a component, and component sets are user-extendable • (Almost) all operations are available both from API and GUI 13
All the world’s a Java Bean.... CREOLE: a Collection of REusable Objects for Language Engineering: • GATE components: modified Java Beans with XML configuration • The minimal component = 10 lines of Java, 10 lines of XML, 1 URL Why bother? • Allows the system to load arbitrary language processing components 14
OBIE ANNIE … ADiff DocVR OntolVR ... Application Layer IDE GUI Layer (VRs) XMLDocumentFormat PDF docs RTF docs HTML docs email XML docs Corpus Document HTMLDocumentFormat DocumentContent AnnotationSet PDFDocumentFormat Annotation TRs NE POS Co-ref FeatureMap TEs … … Processing Layer (PRs) Corpus Layer (LRs) DocumentFormatLayer (LRs) … XML Oracle PostgreSql .ser DataStore Layer GATE APIs Onto-logy ProtégéOnto-logy Word- net Gaz-etteers ... Language Resource Layer (LRs) • NOTES • everything is a replaceable bean • all communication via fixed APIs • low coupling, high modularity, high extensibility 15
GATE Users • American National Corpus project • Perseus Digital Library project, Tufts University, US • Longman Pearson publishing, UK • Merck KgAa, Germany • Canon Europe, UK • Knight Ridder, US • BBN (leading HLT research lab), US • SMEs: Melandra, SG-MediaStyle, ... • a large number of other UK, US and EU Universities • UK and EUprojects inc. SEKT, PrestoSpace, KnowledgeWeb, MyGrid, CLEF, Dot.Kom, AMITIES, CubReporter, … 17
Past Projects using GATE • MUMIS: conceptual indexing: automatic semantic indices for sports video • MUSE: multi-genre multilingual IE • HSL: IE in domain of health and safety • Old Bailey: IE on 17th century court reports • Multiflora: plant taxonomy text analysis for biodiversity research in e-science • EMILLE: creation of S. Asian language corpus • ACE/ TIDES: IE competitions and collaborations in English, Chinese, Arabic, Hindi • h-TechSight: ontology-based IE and text mining 18
Current projects using GATE • ETCSL: Language tools for Sumerian digital library • SEKT: Semantic Knowledge Technologies • PrestoSpace: Preservation of audiovisual data • KnowledgeWeb: Semantic Web network of excellence • MEDIACAMPAIGN: Discovering, inter-relating and navigating cross-media campaign knowledge • TAO: Transitioning Applications to Ontologies • MUSING : SW-based business intelligence tools • NEON : Networked Ontologies 19
GATE 20
Structure of the Tutorial • Motivation, background • GATE overview • Information Extraction • GATE’s HLT components • IE and the Semantic Web • Ontology learning with Text2Onto • Focused ontology learning • Massive Semantic Annotation 21
IE is not IR IR pulls documentsfrom large text collections (usually the Web) in response to specific keywords or queries. You analyse thedocuments. IE pulls factsand structured information from the content of large text collections. You analyse the facts. 22
IE for Document Access • With traditional query engines, getting the facts can be hard and slow • Where has the Queen visited in the last year? • Which places on the East Coast of the US have had cases of West Nile Virus? • Which search terms would you use to get this kind of information? • How can you specify you want someone’s home page? • IE returns information in a structured way • IR returns documents containing the relevant information somewhere (if you’re lucky) 23
HaSIE: an example application • Application developed by University of Sheffield, which aims to find out how companies report about health and safety information • Answers questions such as: “How many members of staff died or had accidents in the last year?” “Is there anyone responsible for health and safety?” “What measures have been put in place to improve health and safety in the workplace?” 24
HaSIE • Identification of such information is too time-consuming and arduous to be done manually. • Each company report may be hundreds of pages long. • IR systems can’t help because they return whole documents • System identifies relevant sections of each document, pulls out sentences about health and safety issues, and populates a database with relevant information • This can then be analysed by an expert 25
HASIE 26
Named Entity Recognition: the cornerstone of IE • Identification of proper names in texts, and their classification into a set of predefined categories of interest • Persons • Organisations (companies, government organisations, committees, etc) • Locations (cities, countries, rivers, etc) • Date and time expressions • Various other types as appropriate 27
Why is NE important? • NE provides a foundation from which to build more complex IE systems • Relations between NEs can provide tracking, ontological information and scenario building • Tracking (co-reference) “Dr Smith”, “John Smith”, “John”, he” • Ontologies “Athens, Georgia” vs “Athens, Greece” 28
Knowledge Engineering rule based developed by experienced language engineers make use of human intuition require only small amount of training data development can be very time consuming some changes may be hard to accommodate Learning Systems use statistics or other machine learning developers do not need LE expertise require large amounts of annotated training data some changes may require re-annotation of the entire training corpus Two kinds of approaches 29
Typical NE pipeline • Pre-processing (tokenisation, sentence splitting, morphological analysis, POS tagging) • Entity finding (gazeteer lookup, NE grammars) • Coreference (alias finding, orthographic coreference etc.) • Export to database / XML 30
Ryanair announced yesterday that it will make Shannon its next European base, expanding its route network to 14 in an investment worth around €180m. The airline says it will deliver 1.3 million passengers in the first year of the agreement, rising to two million by the fifth year. An Example • Entities: Ryanair, Shannon • Mentions: it=Ryanair, The airline=Ryanair, it=the airline • Descriptions: European base • Relations: Shannon base_of Ryanair • Events: investment(€180m) 31
System development cycle • Collect corpus of texts • Manually annotate gold standard • Develop system • Evaluate performance against gold standard • Return to step 3, until desired performance is reached 32
Performance Evaluation 2 main requirements: • Evaluation metric: mathematically defines how to measure the system’s performance against human-annotated gold standard • Scoring program: implements the metric and provides performance measures • For each document and over the entire corpus • For each type of NE 33
Evaluation Metrics • Most common are Precision and Recall • Precision = correct answers/answers produced • Recall = correct answers/total possible correct answers • Trade-off between precision and recall • F1 (balanced) Measure = 2PR / 2(R + P) • Some tasks sometimes use other metrics, e.g. cost-based (good for application-specific adjustment) • Ontology-based IE requires measures sensitive to the ontology 34
Corpus-level Regression Testing • Need to track system’s performance over time • When a change is made we want to know implications over whole corpus • Why: because an improvement in one case can lead to problems in others • GATE offers corpus benchmark tool, which can compare different versions of the same system against a gold standard • This operates on a whole corpus rather than a single document 36
Structure of the Tutorial • Motivation, background • GATE overview • Information Extraction • GATE’s HLT components • IE and the Semantic Web • Ontology learning with Text2Onto • Focused ontology learning • Massive Semantic Annotation 38
GATE’s Rule-based System - ANNIE • ANNIE – A Nearly-New IE system • A version distributed as part of GATE • GATE automatically deals with document formats, saving of results, evaluation, and visualisation of results for debugging • GATE has a finite-state pattern-action rule language - JAPE, used by ANNIE • A reusable and easily extendable set of components 39
What is ANNIE? ANNIE is a vanilla information extraction system comprising a set of core PRs: • Tokeniser • Gazetteers • Sentence Splitter • POS tagger • Semantic tagger (JAPE transducer) • Orthomatcher (orthographic coreference) 40
Re-using ANNIE • Typically a new application will use most of the core components from ANNIE • The tokeniser, sentence splitter and orthomatcher are basically language, domain and application-independent • The POS tagger is language dependent but domain and application-independent • The gazetteer lists and JAPE grammars may act as a starting point but will almost certainly need to be modified • You may also require additional PRs (either existing or new ones) 42
DEMO of ANNIE and GATE GUI • Loading ANNIE • Creating a corpus • Loading documents • Running ANNIE on corpus • Demo 43
Gazetteers • Gazetteers are plain text files containing lists of names (e.g rivers, cities, people, …) • Information used by JAPE rules • Each gazetteer set has an index file listing all the lists, plus features of each list (majorType, minorType and language) • Lists can be modified either internally using Gaze, or externally in your favourite editor • Gazetteers can also be mapped to ontologies • Generates Lookup results of the given kind 45
JAPE grammars • JAPE is a pattern-matching language • The LHS of each rule contains patterns to be matched • The RHS contains details of annotations (and optionally features) to be created • The patterns in the corpus are identified using ANNIC 48
Input specifications The head of each grammar phase needs to contain certain information • Phase name • Inputs • Matching style e.g. Phase: location Input: Token Lookup Number Control: appelt 49
NE Rule in JAPE Rule: Company1 Priority: 25 ( ( {Token.orthography == upperInitial} )+ //from tokeniser {Lookup.kind == companyDesignator} //from gazetteer lists ):match --> :match.NamedEntity = { kind=company, rule=“Company1” } => will match “Digital Pebble Ltd” 50
LHS of the rule • LHS is expressed in terms of existing annotations, and optionally features and their values • Any annotation to be used must be included in the input header • Any annotation not included in the input header will be ignored (e.g. whitespace) • Each annotation is enclosed in curly braces • Each pattern to be matched is enclosed in round brackets and has a label attached 51