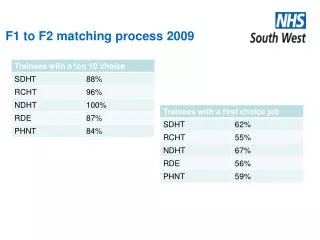
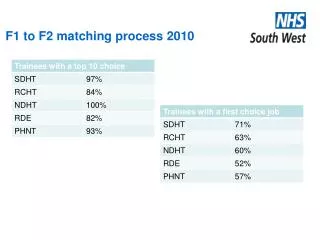
Understanding Document-Query Matching in Information Retrieval Systems
This chapter explores the complexities of the matching process between user queries and documents in information retrieval (IR) systems. It critiques the assumption that all words in a query necessarily appear in relevant documents and emphasizes relevance and topicality as focal points. The chapter reviews different matching techniques, including Boolean and vector-based approaches, as well as the role of user knowledge and preferences in assessing relevance. It also discusses the challenges posed by missing terms and term relationships, ultimately advocating for probabilistic models that account for uncertainties in relevance assessment.


Understanding Document-Query Matching in Information Retrieval Systems
E N D
Presentation Transcript
Matching Process • query의 한 단어가 문서에 나타났다고 해서 반드시 검색되어야 하는 것은 아니다 • query에 여러 단어가 있을 수 있다 • 그 단어가 문맥상 중요하지 않을 수 있다 • e.g. “This document is not about...” • 이 장에서는 문서가 query에 불확실하게 match되는 것으로 가정 • 관련도(relevance)가 얼마나 강한지에 촛점 • Topicality of document에 촛점 • 문서의 topic과 query의 topic의이 일치하는 정도 • 사용자의 지식과 배경 및 선호도: 6장
4.1 Relevance and Similarity Measure • document space: organized set of document • document space doesn’t contain queries • mapping from the document space into the query space (Boolean systems) • characteristic function having the value on documents relevanceto the query: [0, 1] • document space contains queries • query is a point in the document space • relevant documents: a cluster near the query point • evaluation function: define a contour • measure • basis for evaluation of each document • some computable function
measure • whether document is relevant to a query • as relevance is ultimately in the mind of the user, it is difficult to measure directly • IR systems rely primarily on measurementsfrom document and query representation • most systems equate relevance with lexical similarity- matching of words
4.2Boolean-Based Matching • whether containing a given term • query is a logical function of given words, document is not. • 구조적 유사성이 없슴: characteristic function • no basis for the development of significant similarity judgments.-satisfy query or not. • 수정사례: ‘A OR B OR C’의 결과에 grade • Since Boolean systems operate on the basis of the presence or absence of terms, many such systems do not include the term frequency data.
4.3 Vector-Based Matching: Metrics • metrics: distance measure & angular measure • distance measure • 벡터 공간에서 가까우면 유사하다는 가정 • angular measure • 벡터 공간에서 비슷한 방향에 있으면 유사하다는 가정 • distance of a document from itself is 0. • not similarity measure, but dissimilarity measure • 변환이 필요 • linear conversion from a metric to a similarity measure is generally not desirable. • metric 에 대한 변환 를 = k - 로 할 경우 적절한 k값의 선정이 어렵다
4.3 Vector-Based Matching: Metrics • inversion transform(역변환) that maps the distance into fixed positve range of numbers • , b>1, P()는 단조증가
4.4 Vector-Based Matching: Cosine Measure • this is not a distance measure, but an angular measure. • where tk is the value of term k in the document and qk is its value in the query • this is inner product of the document and query vectors, normalized by their lengths.
Measure comparison • distance measures • Similarity depends only on how far a given document is from the point • Angular mesures • not consider the distance of each document from the origin, but only the direction • two documents that lie along the same vector from the origin will be judged identically, despite the fact that they may be far apart in the document space.
Measure comparison • ex) D1=<1, 3>, D2=<100, 300>, D3=<3, 1> • consine measure • (D1, D2) = 1.0, (D1, D3) = 0.6 • euclidean distance • (D1, D2) = 314.96, (D1, D3) = 2.83 • consine measure는 D1과 D2가 더 유사한 것으로 보고 distance measure는 D1과 D3이 더 유사한 것으로 본다 • In practice, distance and angular measures seem to give results of similar quality • sufficiently far from the origin
4.5 Missing Terms and Term Relationship • one problem - missing term • 0은 2가지 의미: no occurrence, no information of occurrence (e.g. <3, 0>, <0, 4>) • it may be that a term is missing from a document description because an indexer did not think it significant, rather than because it does not occur in the document. - also missing from a query by user.
4.5 Missing Terms and Term Relationship • Another problem - term relationship • vector 연산 – 각 원소가 서로 독립임을 가정 • 잘못된 결과 발생 가능성: e.g. “digital computer” • Final problem – symmetricity • distance and angular measure는 모두 query와 document에 대해 대칭적인 관점을 유지 • 사용자는 query에 맞는 document를 원하지만 document에 맞는 query를 원하지는 않는다 • e.g. 백과사전: 사용자 query에 해당하는 항목에는 query에 나타나지 않는 단어가 매우 많이 존재
4.6 Probabilistic Matching • focus attention on models that include uncertainties more directly • to calculate the probability that the document is relevant to the query • assumption • at any given time a sigle query is being used • the number of documents within the database that are relevant to the query is known
4.6 Probabilistic Matching • 무작위(random)로 문서를 선택할 때의 확률 • P(rel) = n/N • P(ㄱrel) = 1- P(rel) = (N-n)/N • 실제로는 query와 document의 단어를 비교하여 선택 • P(computer|digital) > P(computer|?) • 사례 1 • 선택된 어떤 문서 집합 S의 모든 문서에 대해, P(rel|selected) > P(ㄱrel|selected)이면 relevant • Discriminant function dis(selected)= • 어떤 집합의 모든 문서에 대해 dis(selected)>1이면 그 집합 을 검색
4.6 Probabilistic Matching • 사례 2 • 조건: 관련 확률이 무관련 확률의 3배 초과 • P(rel|selected) > 3 P(ㄱrel|selected) • P(rel|selected) > 3 (1 - P(rel|selected)) • P(rel|selected) + 3 P(rel|selected) > 3 • P(rel|selected) > 0.75 • discrimination function criterion is then, • dis(selected) > 3 • 하나의 문서에 대한 관련성 판단을 위해서는 위의 공식을 ‘단어’ 단위로 적용
4.6 Probabilistic Matching • Bayes’s theorem • applying this to the discriminant function, • assume that a document is represented by terms and these terems are statistically independent. • P(selected|rel)=P(t1 |rel)P(t2 |rel)....P(t n |rel)
4.6 Probabilistic Matching • If estimates for the probability of occurrence of various terms in relevant documents and in nonrelevant documents can be obtained, then the probabiliy that a document will be etreived can be estimated.
4.6 Probabilistic Matching • Example • 전체 문서 중 관련 문서의 비율 = 0.1 • 1보다 작으므로 검색되지 않음
4.7 Fuzzy Matching • probabilistic matching involves much calculation and many assumption. • In fuzzy matching the calculation is based on defined membership grades for terms. • this computation is simpler than that for probabilistic retrieval, since it involves simple functions of the membership grades for each document: fuzzy arithmetic에 기반 • e.g. Avg(max(D1(t1), D2(t1),...), max(D1(t2), D1(t2),...)) • how such terms translate into the membership functions associated with fuzzy retrieval.
4.8 Proximity Matching • a much older and more widely used matching method involves the proximity of terms in a text. • Frequently proximity measures are used as additional criteria to further refine the set of documents identified by one of the other matching methods. • Modifications of proximity crireria can increase their effectiveness. • e.g. ordered proximity • “junior college” vs. “college junior”
4.9 Effects of Weighting • Not all terms are equally important in a query. • Weighting of terms modifies the calculations upon which relevance judgments are made. • Weighting can also be applied at a broder level than individual terms. • (beef and broccoli):5; (beef but not broccoli):2, noodles:1; snow peas:1 • Filtering without weighting: more complex calculations will be confined to a relatively small set of documents.
4.10 Effects of Scaling • impact of the size of the document collection can be major. • whether it will be feasible to apply it to real document collections • false drops become more likely • documents that appear to match the query but are not appropriate • 컴퓨터 문서 집합에서는 “object-oriented programming”의 허위 드롭 가능성이 작지만, 일반 문서 집합에서는 크다(TV도 object로 취급) • Information filtering • produce a relatively small set containing a high proportion of relevant document. • 간단한 기법으로 작은 후보 문서 집합을 추출한 후 복잡한 기법으로 추출된 집합을 처리: 금의 가공 과정과 유사
4.11 Data Fusion • no single retrieval technique will work equally well in all situations has led to data fusion • the study of techniques for merging the results of multiple search techniques on multiple databases to produce the best possible response to a query • to develop a retrieval technique that can adapt • DB의 표준화가 문제 • to determine a method to fairly combine • 서로 다른 성격의 measure들을 결합
4.12 A User-Centered View • Each user has an individual vocabulary • retrieval systems commonly miss some documents that might have been informative to the user and retrieve others that the user does not find helpful