Download

1 / 22
220 likes | 362 Views
Kshitij: A Search and Page Recommendation System for Wikipedia. Phanikumar Bhamidipati, Kamalakar Karlapalem Center for Data Engineering International Institute of Information Technology, Hyderabad, India COMAD 2008. Nam, Kwang-hyun Intelligent Database Systems Lab

E N D
Kshitij: A Search and Page Recommendation System for Wikipedia Phanikumar Bhamidipati, Kamalakar Karlapalem Center for Data Engineering International Institute of Information Technology, Hyderabad, India COMAD 2008 Nam, Kwang-hyun Intelligent Database Systems Lab School of Computer Science & Engineering Seoul National University, Seoul, Korea Center for E-Business Technology Seoul National University Seoul, Korea
Contents • Motivation • Problem statement • Kshitij • Overview • Graph Model • Architecture • Algorithms • CBR, LBR, YBR, AR • Results • Conclusion & Future Work • Discussion
Motivation • New paradigms in Search • Increased interest after PageRank and HITS (Hyperlink-Induced Topic Search) algorithms • Wikipedia • Powerful online collaborative encyclopedia • Vast knowledge, available in structured format • The links in each page represent some kind of relation with the base page • Can be mine both the semantics and data from Wikipedia • Need for systems that leverage Wikipedia knowledge in recommendations
Kshitij • A generic recommendation system based on Wikipedia semantics • Provides two services • Search Recommendations • Page Recommendations • Uses Yago as the stored knowledge base • Extracts additional knowledge dynamically from the Wiki pages.
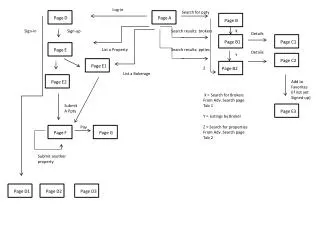
Search Recommendations Result from Search Engine Kshitij Recommendations Keyword as input
Page Recommendations • When the user visit a page, its identifier is sent as input to the algorithms to obtain recommendations • The most relevant aggregated results • Displayed as hyperlinks
Kshitij - Overview • Leverages the structured model powered by Wikis • Categories • Links • YAGO • An ontology compiled from Wikipedia • The static source of knowledge
The Graph Structure Search Atari 7800 Atari Jaguar Atari Jaguar II Jaguar Felidae Jaguar Cars Black Panther William Lyons Automobile Mammal
Kshitij - Algorithms • Three individual recommendations that explore different semantics • CBR • LBR • YBR • A link based aggregator (AR) • Combines the three into single set of recommendations
Category Based Recommendations (CBR) • Key idea • If two pages belong to multiple categories together, the probability that they belong to the same topic increases • London and Berlin in Capitals In Europe and Host cities of the Summer Olympic Games • Algorithm • Starts with a set of pages (search output) • Explores category structure to obtain candidate pages • Prunes the list based on similarity values calculated from shared categories using threshold T1 and T2
Link Based Recommendations (LBR) • Key idea • If two pages are referred together from the same set of pages, they could be considered as related • Competing sports persons, countries in same alliance • Algorithm • Start with search results and output of CBR • Identify frequent item sets • Support by search results is high over CBR output
Yago Based Recommendations (YBR) • Set of facts in triplet form <E1, R, E2> • <New Delhi, Is Capital Of, India> • Prune the relation types • Key idea • To find a prioritized set of entities that are related to a given set of Wikipedia pages • Algorithm • Start with search output • Retrieve entities related to these pages based on the weight measure • Merge the lists and identify the related pages
Diversity of the algorithms • Each explores different knowledge space • The graph explored along edges of a specific color • Recommendations of individual algorithms differ • Need for aggregation • Combines and prioritizes the results
Aggregated Recommendations (AR) • To group them based on the topic each result belongs to • A link based approach • Algorithm • Start with search results and an aggregated list of CBR, LBR and YBR (Cumulative List (CL)) • Explore the neighborhood for each search result to find how many in CL are reachable • A threshold T on the nearness value to filter the related page • Each result page as a point in k-dimensional space (each dimension by one page in CL) • Run Agglomerative Nesting (AGNES – A hierarchical clustering algorithm) to obtain clusters of result pages
Results: Evaluation • Mean Absolute Error (MAE) • To evaluate the effectiveness of a recommendation system
Results: Search Recommendations • A value of 0.4 for T balances both fetching moderate number of recommendation and keeping good quality
Results: Search Recommendations • Keyword: jaguar
Results: Search Recommendations • Keyword: amazon
Conclusion & Future Work • Good quality recommendations can be obtained from annotated knowledge bases using only semantic information • More Wikipedia structures • Templates, References, Info-Boxes, History • Currently, calculates the recommendations on-demand • Plan to come up with a strategy that pre-calculates and stores recommendations set
Discussion • Pros • Present a generic recommendation system that utilizes the stored as well as dynamically extracted semantics from Wikipedia • Good examples • Cons • The figures and tables are not sequentially located. • No comparison with other recommendation system • But, the authors mention that there is no existing recommendation system with which they can directly compare theirs.