Maximum Entropy (ME) Maximum Entropy Markov Model (MEMM) Conditional Random Field (CRF )
320 likes | 923 Views
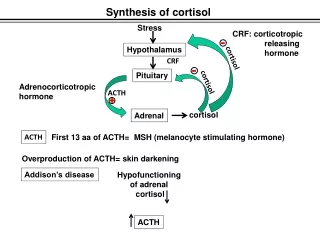
Maximum Entropy (ME) Maximum Entropy Markov Model (MEMM) Conditional Random Field (CRF ). Boltzmann-Gibbs Distribution. Given: States s 1 , s 2 , … , s n Density p ( s ) = p s Maximum entropy principle : Without any information, one chooses the density p s to maximize the entropy

Maximum Entropy (ME) Maximum Entropy Markov Model (MEMM) Conditional Random Field (CRF )
E N D
Presentation Transcript
Maximum Entropy (ME)Maximum Entropy Markov Model (MEMM)Conditional Random Field (CRF)
Boltzmann-Gibbs Distribution • Given: • States s1, s2, …, sn • Density p(s) = ps • Maximum entropy principle: • Without any information, one chooses the density ps to maximize the entropy subject to the constraints
Boltzmann-Gibbs (Cnt’d) • Consider the Lagrangian • Take partial derivatives of L with respect to psand set them to zero, we obtain Boltzmann-Gibbs density functions where Z is the normalizing factor
Exercise • From the Lagrangian derive
Boltzmann-Gibbs (Cnt’d) • Classification Rule • Use of Boltzmann-Gibbs as prior distribution • Compute the posterior for given observed data and features fi • Use the optimal posterior to classify
Boltzmann-Gibbs (Cnt’d) • Maximum Entropy (ME) • The posterior is the state probability density p(s | X), where X = (x1, x2, …, xn) • Maximum entropy Markov model (MEMM) • The posterior consists of transition probability densities p(s | s´, X)
Boltzmann-Gibbs (Cnt’d) • Conditional random field (CRF) • The posterior consists of both transition probability densities p(s | s´, X) and state probability densities p(s | X)
References • R. O. Duda, P. E. Hart, and D. G. Stork, Pattern Classification, 2nd Ed., Wiley Interscience, 2001. • T. Hastie, R. Tibshirani, and J. Friedman, The Elements of Statistical Learning, Springer-Verlag, 2001. • P. Baldi and S. Brunak, Bioinformatics: The Machine Learning Approach, The MIT Press, 2001.
An Example • Five possible French translations of the English word in: • Dans, en, à, au cours de, pendant • Certain constraints obeyed: • When April follows in, the proper translation is en • How do we make the proper translation of a French word y under an English context x?
Formalism • Probability assignment p(y|x): • y: French word, x: English context • Indicator function of a context feature f
Expected Values of f • The expected value of f with respect to the empirical distribution • The expected value of f with respect to the conditional probabilityp(y|x)
Constraint Equation • Set equal the two expected values: or equivalently,
Maximum Entropy Principle • Given n feature functions fi, we want p(y|x) to maximize the entropy measure where p is chosen from
Constrained Optimization Problem • The Lagrangian • Solutions
Iterative Solution • Compute the expectation of fi under the current estimate of probability function • Update Lagrange multipliers • Update probability functions
Feature Selection • Motivation: • For a large collection of candidate features, we want to select a small subset • Incremental growth
Approximation • Computation of maximum entropy model is costly for each candidate f • Simplification assumption: • The multipliers λ associated with S do not change when f is added to S
Difference from MEMM • If the state feature is dropped, we obtain a MEMM model • The drawback of MEMM • The state probabilities are not learnt, but inferred • Bias can be generated, since the transition feature is dominating in the training
Difference from HMM • HMM is a generative model • In order to define a joint distribution, this model must enumerate all possible observation sequences and their corresponding label sequences • This task is intractable, unless observation elements are represented as isolated units
CRF Training Methods • CRF training requires intensive efforts in numerical manipulation • Preconditioned conjugate gradient • Instead of searching along the gradient, conjugate gradient searches along a carefully chosen linear combination of the gradient and the previous search direction • Limited-Memory Quasi-Newton • Limited-memory BFGS (L-BFGS) is a second-order method that estimates the curvature numerically from previous gradients and updates, avoiding the need for an exact Hessian inverse computation • Voted perceptron
Voted Perceptron • Like the perceptron algorithm, this algorithm scans through the training instances, updating the weight vectorλt when a prediction error is detected • Instead of taking just the final weight vector, the voted perceptron algorithms takes the average of theλt
References • A. L. Berger, S. A. D. Pietra, V. J. D. Pietra, A maximum entropy approach to natural language processing • A. McCallum and F. Pereira, Maximum entropy Markov models for information extraction and segmentation • H. M. Wallach, Conditional random fields: an introduction • J. Lafferty, A. McCallum, F. Pereira, Conditional random fields: probabilistic models for segmentation and labeling sequence data • F. Sha and F. Pereira, Shallow parsing with conditional random fields







![[CRF] = Q.R.W [TRF]](https://cdn2.slideserve.com/4138927/slide1-dt.jpg)