Download
1 / 1
10 likes | 154 Views
Prediction of the Melting Point Temperature Using a Linear QSPR for Homologous Series. Inga Paster and Mordechai Shacham, , Dept. of Chem. Engng, Ben Gurion University of the Negev, Beer-Sheva, Israel Neima Brauner, School of Engineering, Tel-Aviv University, Tel-Aviv, Israel. Abstract

E N D
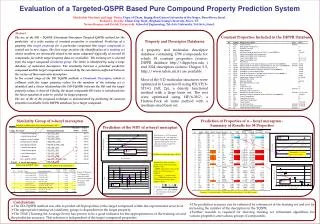
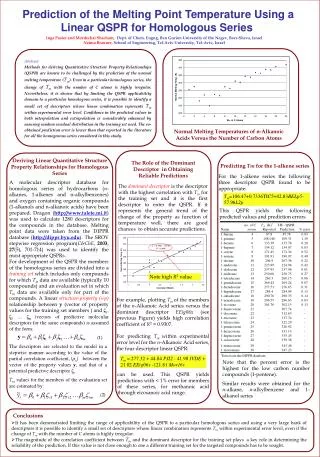
Prediction of the Melting Point Temperature Using a Linear QSPR for Homologous Series Inga Paster and Mordechai Shacham,, Dept. of Chem. Engng, Ben Gurion University of the Negev, Beer-Sheva, Israel Neima Brauner,School of Engineering, Tel-Aviv University, Tel-Aviv, Israel Abstract Methods for deriving Quantitative Structure Property Relationships (QSPR) are known to be challenged by the prediction of the normal melting temperature (Tm). Even in a particular homologous series, the change of Tm with the number of C atoms is highly irregular. Nevertheless, it is shown that by limiting the QSPR applicability domain to a particular homologous series, it is possible to identify a small set of descriptors whose linear combination represents Tm within experimental error level. Confidence in the predicted values in both interpolation and extrapolation is considerably enhanced by ensuring random residual distribution in the training set used. The so-obtained prediction error is lower than that reported in the literature for all the homogenous series considered in this study. Normal Melting Temperatures of n-Alkanoic Acids Versus the Number of Carbon Atoms Deriving Linear Quantitative Structure Property Relationships for Homologous Series The Role of the Dominant Descriptor in Obtaining Reliable Predictions Predicting Tm for the 1-alkene series For the 1-alkene series the following three descriptor QSPR found to be appropriate: A molecular descriptor database for homologous series of hydrocarbons (n-alkanes, 1-alkenes and n-alkylbenzenes) and oxygen containing organic compounds (1-alkanols and n-alkanoic acids) have been prepared. Dragon (http://www.talete.mi.it) was used to calculate 1280 descriptors for the compounds in the database. Melting point data were taken from the DIPPR database (http://dippr.byu.edu). The SROV stepwise regression program(C&ChE, 2003, 27(5), 701-714) was used to identify the most appropriate QSPRs. For development of the QSPR the members of the homologous series are divided into a training set which includes only compounds for which Tm data are available (typically 10 compounds) and an evaluation set in which Tm data are available only for part of the compounds. A linear structure-property(s-p) relationship between y (vector of property values for the training set members ) and ζ1, ζ2 … ζm (vectors of predictive molecular descriptors for the same compounds) is assumed of the form: The dominant descriptor is the descriptor with the highest correlation with Tm for the training set and it is thefirst descriptor to enter the QSPR. If it represents the general trend of the change of the property as function of temperature well, there are good chances to obtain accurate predictions. Tm=106.47+0.7336TIC5+42.83BELp5-57.96L2p This QSPR yields the following predicted values and prediction errors Note high R2 value For example, plotting Tm of the members of the n-Alkanoic Acidseriesversus the dominant descriptor EEig06x (see previous Figure) yields high correlation coefficient of R2 = 0.9307. For predicting Tm within experimental error level for the n-Alkanoic Acidseries,the four descriptor linear QSPR: (1) The descriptors are selected to the model in a stepwise manner according to the value of the partial correlation coefficient, |yj| between the vector of the property values y, and that of a potential predictive descriptor ζj. Tm values for the members of the evaluation set are estimated by: Tm = 277.32 + 44.84 PJI2 - 41.98 IVDE + 21.02 EEig06x -121.81 Mor16v Note that the percent error is the highest for the low carbon number compounds (1-pentene). Similar results were obtained for the n-alkane, n-alkylbenzene and 1-alkanol series can be used. This QSPR yields predictions with < 1% error for members of these series, for methanoic acid through eicosanoic acid range. (2) Conclusions • It has been demonstrated limiting the range of applicability of the QSPR to a particular homologous series and using a very large bank of descriptors it is possible to identify a small set of descriptors whose linear combination represents Tm within experimental error level, even if the change of Tm with the number of C atoms is highly irregular. • The magnitude of the correlation coefficient between Tm and the dominant descriptor for the training set plays a key role in determining the reliability of the prediction. If this value is not close enough to one a different training set for the targeted compounds has to be sought.