Understanding Ensemble Methods in Machine Learning: Techniques and Applications
230 likes | 360 Views
Ensemble methods are powerful techniques in machine learning that involve combining multiple classifiers to improve predictive performance. By constructing a diverse set of classifiers from training data, these methods aggregate the predictions to enhance accuracy, especially useful in cases with high variance or biased classifiers. This overview explores how ensembles like bagging and boosting work, their impacts on bias and variance, and their application in real-world scenarios such as the Netflix Prize challenge, where fine-tuning predictive algorithms can yield substantial improvements.

Understanding Ensemble Methods in Machine Learning: Techniques and Applications
E N D
Presentation Transcript
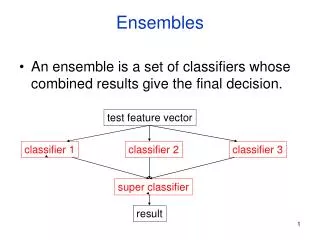
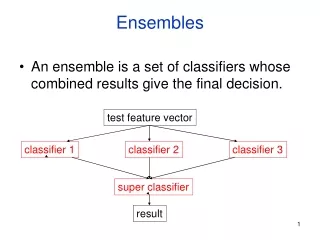
Ensemble Methods • Ensemble methods construct a set of classifiers from the training data • Predict class label of previously unseen records by aggregating predictions made by multiple classifiers • In Olympic Ice-Skating you have multiple judges? Why? • When would multiple judges/classifiers help the most?
Suppose there are 25 base classifiers Each classifier has error rate, = 0.35 Assume classifiers are independent Probability that the ensemble classifier makes a wrong prediction: Practice has shown that even when independence does not hold results are good Why does it work?
Other reasons why it works • Classifier performance can be impacted by: • Bias: assumptions made to help with generalization • "Simpler is better" is a bias • Variance: a learning method will give different results based on small changes (e.g., in training data). • When I run experiments and use random sampling with repeated runs, I get different results each time.
Other reasons why it works (cont.) • Ensemble methods can assist with the bias and variance • Averaging over multiple runs reduces variance • I observe this when I use 10 runs with random sampling and see that my learning curves are much smoother • Ensemble methods especially helpful for unstable classifier algorithms • Decision trees are unstable since small changes in the training data can greatly impact the structure of the learned decision tree • If you combine different classifier methods into an ensemble, then you are using methods with different biases so perhaps more robust
Expressiveness of Ensembles • We discussed the expressiveness of a classifier • What does its decision boundary look like? • An ensemble has more expressive power • Consider 3 linear classifiers where you classify positive only if all three agree–triangular region
Ways to Generate Multiple Classifiers • How many ways can you generate multiple classifiers (what can you vary)? • Manipulate the training data • Sample the data differently each time • Examples: Bagging and Boosting • Manipulate the input features • Sample the features differently each time • Makes especially good sense if there is redundancy • Example: Random Forest • Manipulate the learning algorithm • Vary amount of pruning, learning parameters, or simply use completely different algorithms
Examples of Ensemble Methods • How to generate an ensemble of classifiers? • Bagging • Boosting • These methods have been shown to be quite effective • A technique ignored by the textbook is to combine classifiers built separately • By simple voting • By voting and factoring in the reliability of each classifier
Bagging • Sampling with replacement • Build classifier on each bootstrap sample • Each sample has probability (1 – 1/n)n of being selected (about 63% for large n) • Some values will be picked more than once • Combine the resulting classifiers, such as by majority voting • Greatly reduces the variance when compared to a single base classifier
Boosting • An iterative procedure to adaptively change distribution of training data by focusing more on previously misclassified records • Initially, all N records are assigned equal weights • Unlike bagging, weights may change at the end of boosting round • One of few practical developments from computational learning theory • Idea is that if you have independent weak learners (just a bit better than guessing) you can boost them and perform arbitrarily well (if you have enough of them)
Records that are wrongly classified will have their weights increased and are more likely to be sampled Records that are classified correctly will have their weights decreased Boosting • Example 4 is hard to classify • Its weight is increased, therefore it is more likely to be chosen again in subsequent rounds
The Netflix Prize:$1 million for a 10% improvement over Netflix’s CINEMATCH Algorithm
Netflix Prize Video • https://www.youtube.com/watch?v=ImpV70uLxyw • https://www.youtube.com/watch?v=ImpV70uLxyw
Netflix • Netflix is a subscription-based movie and television show rental service that offers media to subscribers: • Physically by mail • Over the internet • Has a catalog of over 100,000 movies and television shows • Subscriber base of over 10 million
Recommendations • Netflix offers users the ability to rate movies and television shows that they have seen • Depending on those ratings, Netflix provides recommendations of movies and television shows that the subscriber would like to watch • These recommendations are based on an algorithm called Cinematch
Cinematch • Uses straightforward statistical linear models with a lot of data conditioning • This means that the more a subscriber rates, the more accurate the recommendations will become
Netflix Prize • Competition for the best collaborative filtering algorithm to predict user ratings for movies and television shows, based on previous ratings • Offered a $1 million prize to the team who could improve Cinematch’s accuracy by 10% • Awarded a $50,000 progress prize for the team who makes the most progress for each year before the 10% mark was reached • The contest started on October 2, 2006 and would run until at least October 2, 2011, depending on when a winner was chosen
Metrics • The accuracy of the algorithms was measured by using root mean square error, or RMSE • Chosen because it is a well-known, single value that can account for and amplify the contributions of errors such as false positives and false negatives
Metrics • Cinematch scored 0.9525 on the test subset • The winning team needed to score at least 10% lower, with an RMSE of 0.8563
Results • The contest ended on June 26, 2009 • The threshold was broken by the teams “BellKor's Pragmatic Chaos” and “The Ensemble”, both achieving a 10.06% improvement over Cinematch, with an RMSE of 0.8567 • “BellKor's Pragmatic Chaos” won the prize due to the team submitting their results 20 minutes before “The Ensemble”
Netflix Prize Sequel • Due to the success of their contest, Netflix announced another contest to further improve their recommender system • Unfortunately, it was discovered that the anonymized customer data that they provided to the contestants could actually be used to identify individual customers • This, combined with a resulting investigation by the FTC and a lawsuit, led Netflix to cancel their sequel
Sources • http://blog.netflix.com/2010/03/this-is-neil-hunt-chief-product-officer.html • http://www.netflixprize.com • http://www.nytimes.com/2010/03/13/technology/13netflix.html?_r=1