Download
1 / 1
10 likes | 119 Views
Mendelian randomization uses genetic variants as instrumental variables to assess causal associations in observational data, overcoming confounding and reverse causation challenges. Learn how to estimate causal effects and address structural uncertainty in causal modeling. Contact Stephen Burgess for more information.

E N D
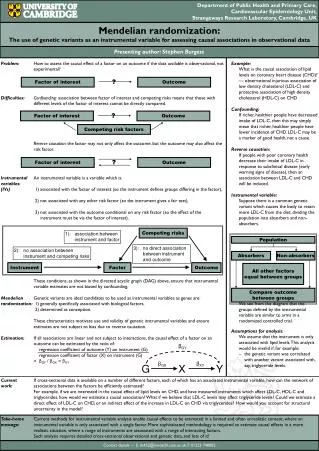
Department of Public Health and Primary Care,Cardiovascular Epidemiology Unit,Strangeways Research Laboratory, Cambridge, UK Mendelian randomization:The use of genetic variants as an instrumental variable for assessing causal associations in observational data Presenting author: Stephen Burgess Problem: How to assess the causal effect of a factor on an outcome if the data available is observational, not experimental? Difficulties:Confounding: association between factor of interest and competing risks means that those with different levels of the factor of interest cannot be directly compared. Reverse causation: the factor may not only affect the outcome, but the outcome may also affect the risk factor. Instrumental An instrumental variable is a variable which is: variables: (IVs) 1) associated with the factor of interest (so the instrument defines groups differing in the factor), 2) not associated with any other risk factor (so the instrument gives a fair test), 3) not associated with the outcome conditional on any risk factor (so the effect of the instrument must be via the factor of interest). These conditions, as shown in the directed acyclic graph (DAG) above, ensure that instrumental variable estimates are not biased by confounding. Mendelian Genetic variants are ideal candidates to be used as instrumental variables as genes are: randomization: 1) generally specifically associated with biological factors, 2) determined at conception. These characteristics motivate use and validity of genetic instrumental variables and ensure estimates are not subject to bias due to reverse causation. Estimation: If all associations are linear and not subject to interactions, the causal effect of a factor on an outcome can be estimated by the ratio of: regression coefficient of outcome (Y) on instrument (G) regression coefficient of factor (X) on instrument (G) = βGY / βGX = βXY Example: What is the causal association of lipid levels on coronary heart disease (CHD)? — observational injurious association of low density cholesterol (LDL-C) and protective association of high density cholesterol (HDL-C) on CHD Confounding: If richer, healthier people have decreased intake of LDL-C, then this may simply mean that richer, healthier people have lower incidence of CHD. LDL-C may be a marker of good health, not a cause. Reverse causation: If people with poor coronary health decrease their intake of LDL-C in response to subclinical disease (early warning signs of disease), then an association between LDL-C and CHD will be induced. Instrumental variable: Suppose there is a common genetic variant which causes the body to retain more LDL-C from the diet, dividing the population into absorbers and non-absorbers. We see from the diagram that the groups defined by the instrumental variable are similar to arms in a randomized controlled trial. Assumptions for analysis: We assume that the instrument is only associated with lipid levels. This analysis would be invalid if, for example: – the genetic variant was correlated with another variant associated with, say, triglyceride levels. Factor of interest Outcome ? Factor of interest Outcome ? Competing risk factors Factor of interest Outcome ? Competing risks 1): association between instrument and factor Population 3): no direct association between instrument and outcome 2): no association between instrument and competing risks Absorbers Non-absorbers Instrument Factor Outcome All other factors equal between groups Compare outcome between groups βGY βGX βXY G X Y Current If cross-sectional data is available on a number of different factors, each of which has an associated instrumental variable, how can the network of work: associations between the factors be efficiently estimated? For example, if we are interested in the causal effect of lipid levels on CHD, and have measured instruments which affect LDL-C, HDL-C and triglycerides, how would we estimate a causal association? What if we believe that LDL-C levels may affect triglyceride levels? Could we estimate a direct effect of LDL-C on CHD, or an indirect effect of the increase in LDL-C on CHD via triglycerides? How would you account for structural uncertainty in the model? Take-home Current methods for instrumental variable analysis enable causal effects to be estimated in a limited and often unrealistic context, where an message: instrumental variable is only associated with a single factor. More sophisticated methodology is required to estimate causal effects in a more realistic situation, where a range of instruments are associated with a range of interacting factors. Such analysis requires detailed cross-sectional observational and genetic data, and lots of it! Contact details — E: sb452@medschl.cam.ac.uk, T: 01223 740002