Download
1 / 37
370 likes | 518 Views
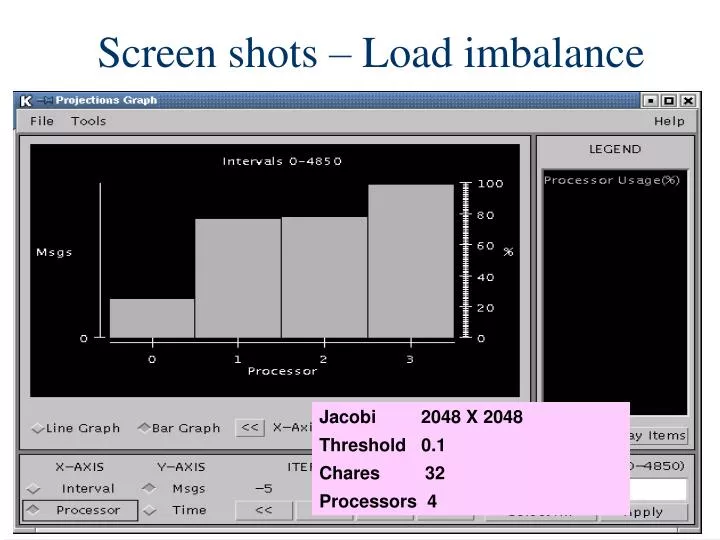
Screen shots – Load imbalance. Jacobi 2048 X 2048 Threshold 0.1 Chares 32 Processors 4. Timelines – load imbalance. Migration. Array objects can migrate from one PE to another To migrate, must implement pack/unpack or pup method pup combines 3 functions into one

E N D
Screen shots – Load imbalance Jacobi 2048 X 2048 Threshold 0.1 Chares 32 Processors 4
Migration • Array objects can migrate from one PE to another • To migrate, must implement pack/unpack or pup method • pup combines 3 functions into one • Data structure traversal : compute message size, in bytes • Pack : write object into message • Unpack : read object out of message • Basic Contract : here are my fields (types, sizes and a pointer)
Pup – How to write it? Class ShowPup { double a; int x; char y; unsigned long z; float q[3]; int *r; // heap allocated memory public: … other methods … void pup(PUP:er &p) { p(a); p(x); p(y); p(z); p(q,3); if(p.isUnpacking() ) r = new int[ARRAY_SIZE]; p(r,ARRAY_SIZE); } };
Load Balancing • All you need is a working pup • link a LB module • -module <strategy> • CommLB, Comm1LB, GreedyLB, GreedyRefLB, MetisLB, NeighborLB, RandCentLB, RandRefLB, RecBisectLB, RefineLB • EveryLB will include all load balancing strategies • runtime option • +balancer CommLB
Centralized Load Balancing • Uses information about activity on all processors to make load balancing decisions • Advantage: since it has the entire object communication graph, it can make the best global decision • Disadvantage: Higher communication costs/latency, since this requires information from all running chares
Neighborhood Load Balancing • Load balances among a small set of processors (the neighborhood) to decrease communication costs • Advantage: Lower communication costs, since communication is between a smaller subset of processors • Disadvantage: Could leave a system which is globally poorly balanced
Centralized Load Balancing Strategies • RandCentLB – randomly assign objects to processors, with no reference to the object call graph • GreedyLB – starting with no load on any processor, places objects with highest load on processors with lowest load until all objects are allocated to a processor • RefineLB – move objects off overloaded processors to under-utilized processors to reach average load • RandRefLB – randomly assign objects to processors, then refine • GreedyRefLB – assign objects to processors using the greedy load balancer, then refine
Centralized Load Balancing Strategies, Part 2 • RecBisectBfLB – recursively partition the object communication graph until there is one partition for each processor • MetisLB – use Metis to partition object communication graph • CommLB – similar to the greedy load balancer, but also takes communication graph into account • Comm1LB – variation of CommLB
Neighborhood Load Balancing Strategies • NeighborLB – neighborhood load balancer, currently uses a neighborhood of 4 processors
AtSync method: enable load balancing at specific point Object ready to migrate Re-balance if needed AtSync(), ResumeFromSync() Manual trigger: specify when to do load balancing All objects ready to migrate Re-balance now TurnManualLBOn(), StartLB() When to Re-balance Load? • Default: Load balancer will migrate when needed • Programmer Control
LiveViz – What is it? • Charm++ library • Visualization tool • Inspect your program’s current state • Client runs on any machine (java) • You code the image generation • 2D and 3D modes
LiveViz – Monitoring Your Application • LiveViz allows you to watch your application’s progress • Can use it from work or home • Doesn’t slow down computation when there is no client
LiveViz - Compilation • Compile the LiveViz library itself • Must have built charm++ first! • From the charm directory, run: • cd tmp/libs/ck-libs/liveViz • make
Running LiveViz • Build and run the server • cd pgms/charm++/ccs/liveViz/serverpush • Make • ./run_server • Or in detail…
Running LiveViz • Run the client • cd pgms/charm++/ccs/liveViz/client • ./run_client [<host> [<port>]] • Should get a result window:
Client Get Image LiveViz Server Code Send Image to Client Image Chunk Passed to Server Buffer Request Server Combines Image Chunks Poll Request Returns Work Poll for Request Parallel Application LiveViz Request Model
Jacobi 2D Example Structure Main: Setup worker array, pass data to them Workers: Start looping Send messages to all neighbors with ghost rows Wait for all neighbors to send ghost rows to me Once they arrive, do the regular Jacobi relaxation Calculate maximum error, do a reduction to compute global maximum error If timestep is a multiple of 64, load balance the computation. Then restart the loop. Main: Setup worker array, pass data to them Workers: Start looping Send messages to all neighbors with ghost rows Wait for all neighbors to send ghost rows to me Once they arrive, do the regular Jacobi relaxation Calculate maximum error, do a reduction to compute global maximum error If timestep is a multiple of 64, load balance the computation. Then restart the loop. Main: Setup worker array, pass data to them Workers: Start looping Send messages to all neighbors with ghost rows Wait for all neighbors to send ghost rows to me Once they arrive, do the regular Jacobi relaxation Calculate maximum error, do a reduction to compute global maximum error If timestep is a multiple of 64, load balance the computation. Then restart the loop.
LiveViz Setup #include <liveVizPoll.h> void main::main(. . .) { // Do misc initilization stuff // Create the workers and register with liveviz CkArrayOptions opts(0);// By default allocate 0 // array elements. liveVizConfig cfg(true, true);// color image = true and // animate image = true liveVizPollInit(cfg, opts);// Initialize the library // Now create the jacobi 2D array work = CProxy_matrix::ckNew(opts); // Distribute work to the array, filling it as you do } #include <liveVizPoll.h> void main::main(. . .) { // Do misc initilization stuff // Now create the (empty) jacobi 2D array work = CProxy_matrix::ckNew(0); // Distribute work to the array, filling it as you do }
Adding LiveViz To Your Code void matrix::serviceLiveViz() { liveVizPollRequestMsg *m; while ( (m = liveVizPoll((ArrayElement *)this, timestep)) != NULL ) { requestNextFrame(m); } } void matrix::startTimeSlice() { // Send ghost row north, south, east, west, . . . sendMsg(dims.x-2, NORTH, dims.x+1, 1, +0, -1); // Now having sent all our ghosts, service liveViz // while waiting for neighbor’s ghosts to arrive. serviceLiveViz(); } void matrix::startTimeSlice() { // Send ghost row north, south, east, west, . . . sendMsg(dims.x-2, NORTH, dims.x+1, 1, +0, -1); }
Generate an Image For a Request void matrix::requestNextFrame(liveVizPollRequestMsg *m) { // Compute the dimensions of the image bit we’ll send // Compute the image data of the chunk we’ll send – // image data is just a linear array of bytes in row-major // order. For greyscale it’s 1 byte, for color it’s 3 // bytes (rgb). // The liveViz library routine colorScale(value, min, max, // *array) will rainbow-color your data automatically. // Finally, return the image data to the library liveVizPollDeposit((ArrayElement *)this, timestep, m, loc_x, loc_y, width, height, imageBits); }
Link With The LiveViz Library OPTS=-g CHARMC=charmc $(OPTS) LB=-module RefineLB OBJS = jacobi2d.o all: jacobi2d jacobi2d: $(OBJS) $(CHARMC) -language charm++ \ -o jacobi2d $(OBJS) $(LB) -lm \ -module liveViz jacobi2d.o: jacobi2d.C jacobi2d.decl.h $(CHARMC) -c jacobi2d.C OPTS=-g CHARMC=charmc $(OPTS) LB=-module RefineLB OBJS = jacobi2d.o all: jacobi2d jacobi2d: $(OBJS) $(CHARMC) -language charm++ \ -o jacobi2d $(OBJS) $(LB) –lm jacobi2d.o: jacobi2d.C jacobi2d.decl.h $(CHARMC) -c jacobi2d.C
LiveViz Summary • Easy to use visualization library • Simple code handles any number of clients • Doesn’t slow computation when there are no clients connected • Works in parallel, with load balancing, etc.
Advanced Features: Groups • Groups are similar to arrays, except only one element is on each processor – the index to access the group is the processor ID • Advantage: Groups can be used to batch messages from chares running on a single processor, which cuts down on the message traffic • Disadvantage: Does not allow for effective load balancing, since groups are stationary (they are not virtualized)
Advanced Features: Node Groups • Similar to groups, but only one per node, instead of one per processor – the index is the node number • Similar advantages and disadvantages as well – node groups can be used to batch messages on a single node, but are not virtualized and do not participate in load balancing • Node groups can have exclusive entry methods – only one exclusive entry method may be running at once
Advanced Features: Priorities • Messages can be assigned different priorities • The simplest priorities just specify that the message should either go on the end of the queue (standard behavior) or the beginning of the queue • Specific priorities can also be assigned to messages • Priorities can be specified with either numbers or bit vectors • For numeric priorities, lower numbers have a higher priority
Advanced Features: Custom Array Indexes • Standard, system supplied indexes are available for 1D, 2D, and 3D arrays • You can create your own custom index for higher dimension arrays or for custom indexing information • Need to create a custom class that provides indexing functionality, supply this with the array definition
Advanced Features: Entry Method Attributes entry [attribute1, ..., attributeN] void EntryMethod(parameters); Attributes: • threaded • entry methods which are run in their own non- preemptible threads • sync • methods return message as a result
Advanced features: Reductions • Callbacks • transfer control back to a client after a library has finished • Various pre-defined callbacks, eg: CkExit the program • Callbacks in reductions • Can be specified in the main chare on processor 0:myProxy.ckSetReductionClient(new CkCallback(...)); • Can be specified in the call to contribute by specifying the callback method:contribute(sizeof(x), &x, CkReduction::sum_int,processResult );
Reductions, Part 2 • Predefined Reductions • Sum values or arrays with CkReduction::sum_[int, float, double] • Calculate the product of values or arrays with CkReduction:: product_[int,float,double] • Calculate the maximum contributed value with CkReduction:: max_[int,float,double] • Calculate the minimum contributed value with CkReduction:: min_[int,float,double] • Calculate the logical and of integer values with CkReduction:: logical_and
Reductions, Part 3 • Predefined Reductions, continued… • Calculate the logical or of contributed integers with CkReduction::logical_or • Form a set of all contributed values with CkReduction::set • Concatenate bytes of all contributed values with CkReduction::concat
Reductions, Part 4 • User defined reductions • performing a user-defined operation on user-defined data • Defined as CkReductionMsg *reductionFn(int nMsg, CkReductionMsg **msgs) • Registered using CkReducer::addReducer, which returns a reduction type you can pass to Contribute
Benefits of Virtualization • Better Software Engineering • Logical Units decoupled from “Number of processors” • Message Driven Execution • Adaptive overlap between computation and communication • Predictability of execution • Flexible and dynamic mapping to processors • Flexible mapping on clusters • Change the set of processors for a given job • Automatic Checkpointing • Principle of Persistence
More Information • http://charm.cs.uiuc.edu • Manuals • Papers • Download files • FAQs • ppl@cs.uiuc.edu



















