Performance
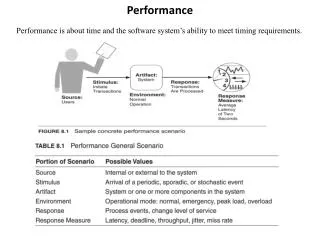
Performance. What hardware accelerators are you using/evaluating ? Cells in a Roadrunner configuration 8-way SPE threads w/ local memory, DMA & vector unit programming issues but tremendous flexibility Fast (25.6 GB/s) & large memory (4GB or larger)


Performance
E N D
Presentation Transcript
Performance • What hardware accelerators are you using/evaluating? • Cells in a Roadrunner configuration • 8-way SPE threads w/ local memory, DMA & vector unit programming issues but tremendous flexibility • Fast (25.6 GB/s) & large memory (4GB or larger) • Augmented C language; also C++ & now Fortran; GNU & XL variants; OpenMP is new; OpenCL is being prototyped • Opterons can run bulk of code not needing acceleration; Cell-only clusters possible
Performance • What hardware accelerators are you using/evaluating? Several years ago… • GPUs (pre CUDA & Tesla) • Brook & Scout (LANL data-parallel language) • No 32bit at the time; limited memory; everything is a data-parallel problem • No ECC memory ; insufficient parity/ECC protection of data paths and logic • Others at LANL still working in this area including Tesla & CUDA) • Clearspeed (several years ago) • Earliest Clearspeeds before the Advance families • Augmented C language; 96 SIMD PEs • Everything is done as long SIMD data parallel and in synch • Low power • FPGAs (HDL, several years ago) • Programming is hard -- very hard • Logic space limited the number of 64bit ops • Fast SRAM but small; external DRAM modest size but no faster than CPUs • One algorithm at a time, so significant impact to use for multi-physics • Low power
Performance • Describe the applications that you are porting to accelerators? • MD (materials), laser-plasma PIC, IMC X-ray (particle) transport, GROMACS, n-body universe & galaxies, DNS turbulence & supernovea, HIV genealogy, nanowire long-time-scale MD • Ocean circulation, wildfires, discrete social simulations, clouds & rain, influenza spread, plasma turbulence, plasma sheaths, fluid instabilities My personal observations: • Particle methods are generally easiest • Codes with good characteristics: • A few computationally intense “algorithms” • pre-existing or obvious “fine-grain” parallel work units • C language versus Fortran or highly OO C++
Performance • Describe the kinds of speed-ups are you seeing (provide the basis for the comparison)? • 5x to 10X over single-Opteron-core for code with high memory BW intensive and 5%-10% peak • 10x to 25x on particle methods, searches, etc. • How does it compare to scaling out (i.e., just using more X86 processors)? What are the bottlenecks to further performance improvements? • Scale out via more sockets is better – BUT! • Scaling efficiencies are a problem already for several LANL applications running at 4,000 to 10,000 cores; scale out of LANL-sized machines means $$$ for HW, space, & power • Scaling out by multi-core is not a clear winner • Memory BW and cache architectures often limit performance which Cells mostly get around • Memory BW per core is decreasing at “inverse Moore’s law” rate!
Economics • Describe the programming effort required to make use of the accelerator. • ½ to 1 man-year to “convert” a code, mostly dealing with data structures and threaded parallelism designs. • Lack of debugging & similar tools are like the earliest days of parallel computing (LANL was leader then as well – remember early PVM Ethernet workstation “carpet” clusters in the mid-80’s before MPPs) • We like to see 1-2 programming experts (PhD-level or equiv) assigned to forefront-science code projects which have 1 to 4+ physics experts (PhD-level) • Amortization • Ready for the future – codes and skilled programmers. We expect our dual-level (MPI+threads) & SIMD-vectorization techniques used for Roadrunner to pay off on future multi-core and many-core chips as well. • It’s not just about running codes this year. Others will have to work through new forms of parallelism soon. • We can do science now that isn’t possible with most other machines
Economics • Compare accelerator cost to scaling out cost • Commodity-processor-only machines would have cost 2X what Roadrunner did in 2006-2007 (~$80M more) • Used 2X or more power (~$1M per MW) • Significantly larger nodes counts cause scaling & reliability issues • Accelerators or heterogeneous chips should be Greener • Ease of use issues • Newer Cell programming techniques (ALF, OpenMP) could make this easier. • A Cell cluster would be easier, but the PPE is really, really slow for non- SPU accelerated code segments. • Not for the faint of heart, but Top20 machines never are
Futures • What is the future direction of hardware based accelerators? • Domain specific libraries can make them far more useful in those specific areas • Some may appear on Intel QPI or AMD HT. • Specialized cores will show up within commodity microprocessors – ignore them or use them • GPU-based systems will have to adopt ECC & partity protection • Convey appears to have the most viable FPGA approach (FPGA as compiler managed co-processor) • Software futures? • OpenCL looks promising but doesn’t address programming the specialized accelerator devices themselves • The uber-auto-wizard-compiler will never come • Heterogeneous compilers may come. • Debuggers & tools may come • What are your thoughts on what the vendors need to do to ensure wider acceptance of accelerators? • Create next generation versions and sell as mainstream products
Steps in a Cell Conversion • Compile & run on PowerPC PPE • Identify & isolate algorithm & data to run parallel on 8 “remote” SPEs • Compile scalar version of algorithm on SPE • Add SPE thread process control • Add DMAs • Use “blocking” DMAs at this stage just for functionality • Worry about data alignments • First on a single SPE, then on 8 SPEs • Optimize SPE code • SIMD, branchesmerges • Add asynch double/triple buffering of DMAs • For Roadrunner, connect to rest of code on Opteron via DaCS and “message relay”
Roadrunner & LANL: addressing the shock moving through high-performance computing • Roadrunner is more than a petascale supercomputer for today’s use • provides a balanced platform to explore new algorithm design, programming models, and to refresh developer skills • LANL has been an early adopter of transformational technology*: • 1970s: HPC is scalarLANL adopts vector (Cray 1 w/ no OS) • 1980s: HPC is vector LANL adopts data parallel (big CM-2) • 2000s: HPC is multi-core clusters LANL adopts hybrid (Roadrunner) *Credit to Scott Pakin, CCS-1, for this list idea
MPI (5B) Non-accelerated code Node Memory Node (Opteron) (5a) (6) (2) (1) PCIe link Cell Memory Serial PPC Processor Each SPE DMA multi-buffers Cell data into local memory (3) (4) until done Parallel SPE Processors Each SPE computes within its local memory buffers Simultaneously (4) Each SPE DMA multi-buffers data back to Cell memory Local Memories 8-way parallel Non-accelerated code Perspective: Fun or Nightmare? Opteron Cell PPC Cell SPE (x8 parallel) MPI (1) Host launches Cell code DaCS Host data pushed/pulled to Cell (2) Cell spawns parallel threads on SPEs (3) Node may need to push/pull more data to/from Cell & to/from cluster or could be available for concurrent work during this time (5b) (5a) DMA MPI DMA Parallel threads completed (6) DaCS Updated data pushed/pulled to Host Cell code completed MPI How much can be automatedin compilers or languages?