Reliability
Reliability. Reliability. Welcome every one. : The Instructor Presented by: Dr. Çise Çavuşoğlu Saman A. Hasan . Reliability and Validity. Example :1


Reliability
E N D
Presentation Transcript
Reliability Welcome every one :The InstructorPresented by: Dr. Çise Çavuşoğlu Saman A. Hasan
Reliability and Validity Example :1 A test designed to measure typing ability. if the test is reliable we would expect a student who receives a high score the first time he takes the test to receive a high score the next time he takes the test, but they should be close. Example :2 If you test someone and he is got 100, after a period of time do again if you get the same result, it is reliability but if you get different result it is validity. Example 3 When all the students know the answer of your question it is reliability , but when students have different answers for your question it is validity. Example 4 How much time do I need for studying master? The answer is reliability How much time do I need for learning Turkish? The answer is validity
Reliability and Validity Example 5 Suppose a researcher gave a group of eighth graders two forms of a test designed to measure their knowledge of the constitution of the united states and found their scores to be consistent: those who scored high on form A also scored high on form B ; and so on . we would say that the scores are reliable. Example 6 When we talk about human's organs , It is reliability When we talk about human's behavior, It is validity Example 7 What does consistency to be measure? (Reliability) What does suppose to be measure? (Validity)
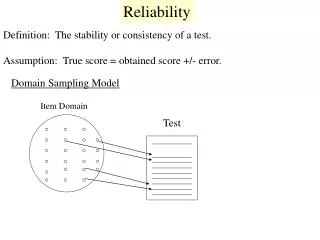
Definition Reliability refers to the consistency of scores or answers from one set of items to another. Reliability of research concerns the replicability and consistency of the methods, conditions, and results. Reliable data is evidence that you can trust. That means that if someone else did the same experiment they would get the same result. ”“Your evidence will be more reliable if you repeat your reading
Types of reliability External reliability : involves the extent to which independent researchers working in the same or similar context would obtain consistent results. Such as psychometric tests and questionnaires can be assessed using the test-retest method. This involves testing the same participant twice over a period of time on the same test. Similar scores would suggest that the test has external reliability.
Types of reliability Internal reliability: involves the extent to which researchers concerned with the same data and constructs would be consistent in matching them. Such as psychometric tests and questionnaires can be assessed using the split half method. This involves splitting a test into two and having the same participant doing both halves of the test. If the two halves of the test provide similar results this would suggest that the test has internal reliability.
Reliability Errors of measurement Whenever people take the same test twice , they will seldom perform exactly the same –that is, their scores or answers will not usually be identical. This may due to variety of factors. Here’s a crazy (but true) example: many years ago, people used to believe that if you had a large brain then you were intelligent. Suppose you went around and measured the circumference of your friend's heads because you also believed this theory. Is the size of a person’s head a reliable measure (Think first!)? The answer is YES. If I measured the size of your head today and then next week, I would get the same number. Therefore, it is reliable. However, the whole idea is wrong! Because we now know that larger headed people are not necessarily smarter than smaller headed ones, we know that the theory behind the measure is invalid.
Reliability coefficient • Expresses a relationship , but this time it is between scores of the same individuals on the same instrument at two different times, or between two parts of the same instrument. • Reliability is related to these parts. If scores have large error components,reliability is low; but if there is little error in the scores, Reliability is high. • Reliability coefficient can take on values from 0 to 1.0, inclusive. Conceptually, if a reliability coefficient where 0, there would be no "true" component in the observed score. The observed score would consist entirely of error. On the other hand, if the reliability coefficient where 1.0, the observed score would contain no error
Procedures for Estimating Reliability (The three best – known ways to obtain a reliability coefficient) Test-Retest Method: the test retest method involves administering the same test twice to the same group after a certain time interval has elapsed. A reliability coefficient is then calculated to indicate the relationship between the two sets of scores obtained. • If the test is reliable, the scores that each student receives on the first administration should be similar to the scores on the second. • Reliability coefficient will be affected by the length of time that elapses between the two administrations of the test. • The longer the time interval, the lower the reliability coefficient is likely to be
Procedures for Estimating Reliability Equivalent-Forms Method :(also called alternate or parallel) when the equivalent –forms is used, two different but equivalent forms of an instrument are administered to the same group of individuals during the same time period. Although the questions are different, they should sample the same content and they should be constructed separately from each other. A reliability coefficient is then calculated between the two sets of scores obtained.
Inter-Rater Reliability Whenever observations of behavior are used as data in research, we want to assure that these observations are reliable. One way to determine this is to have two or more observers rate the same subjects and then correlate their observations. If, for example, rater A observed a child act out aggressively eight times, we would want rater B to observe the same amount of aggressive acts. If rater B witnessed 16 aggressive acts, then we know at least one of these two raters is incorrect. If there ratings are positively correlated, however, we can be reasonably sure that they are measuring the same construct of aggression. It does not, however, assure that they are measuring it correctly, only that they are both measuring it the same.
There are several internal consistency methods of estimating reliability Split- half procedure The split-half procedure involves scoring two halves of a test separately for each person and then calculating the correlation coefficient for the two sets of scores. The coefficient indicates the degree to which the halves of the test provide the same results. Hence describe the internal consistency of the test. Reliability of scores On total test Thus, if we obtained a correlation coefficient of .56 by comparing on–half of the test items to the other half, the reliability of scores for the total test would be: Reliability of scores = = .72 On total test This illustrates an important characteristic of reliability. The reliability of a test can generally be increased by increasing its length, if the items added are similar to the original ones.
Kuder - Richardson Approaches Perhaps the most frequently employed method for determining internal consistency is the Kuder - Richardson Approach, particularly formulas KR20 and KR21. These formulas require only three pieces of information- • The number of the items in the test. • The mean • The standard deviation *That formula KR21 can be used only if it can be assumed that the items are of equal difficulty. As the following: KR21 reliability = Coefficient K= number of items in the test M= mean of the test of test scores SD= standard deviation of the set of test scores.
For example, if (K= 50 M= 40 SD= 4) The reliability coefficient would be calculated as shown below: Reliability = = ( ) = (1.02) ( 1 - .50 ) = (1.02) (.50) = .51 Thus the reliability estimate for scores on this test is (.51) *Formula KR20 does not require the assumption that all items are of equal difficulty, although it is more difficult to calculate. Computer programs for doing so are commonly available, however, and should be used whenever a researcher cannot assume that all items are of equal difficulty.
How do you know the reliability estimate of .51 good or bad, high or low? First we can compare a given coefficient with the extremes that are possible. As you will recall, a coefficient of ( .00) indicates a complete absence of a relationship; hence no reliability at all, whereas (1.00) is the maximum possible coefficient that can be obtained. Second we can compare a given reliability coefficient with the sorts of coefficient that are usually obtained for measures of the same type. The reported reliability coefficients for many commercially available achievement tests, for example, are typically .90 or higher when Kurder-Rechardson formulas are used. Many classroom tests report reliability coefficient of .70 and higher. Compared to these figures, our obtained coefficient must be judged rather low. For research purposes, a useful rule of thumb is that reliability should be at least .70 and preferably higher.
Alpha Coefficient Another check on the internal consistency of an instrument is to calculated an alpha coefficient ( frequently called Cronbach alpha after the man who developed it) This coefficient (a) is a general form of the KR20 formula to be used in calculating the reliability of items that are not scored right versus wrong, as in some easy tests where more than one answer is possible. You might see a problem in that you picked two halves at random. Why not try to take into account all possible split halves. Wouldn't that you give you a better estimate? In fact, that is done by Cronbach's Alpha:
Summary of the three methods of estimating the instrument 1 2 2 1 1
An example of the importance of reliability It is the use of measuring devices in Olympic track and field events. For the vast majority of people, ordinary measuring rulers and their degree of accuracy are reliable enough. However, for an Olympic event, such as the discus throw, the slightest variation in a measuring device -- whether it is a tape, clock, or other device -- could mean the difference between the gold and silver medals. Additionally, it could mean the difference between a new world record and outright failure to qualify for an event. Olympic measuring devices, then, must be reliable from one throw or race to another and from one competition to another. They must also be reliable when used in different parts of the world, as temperature, air pressure, humidity, interpretation, or other variables might affect their readings.
References • Fraenkel, J., R., & Wallen, N., E., (1990). Howto design and evaluate research in education. New York. • Jones, J. E. & Bearley, W.L. (1996, Oct 12). Reliability and validity of training instruments. Organizational Universe Systems. Available: http://ous.usa.net/relval.htm • Wiersma, W. , & Jurs , S. G., ( 2005 ). Research Methods in Education. Boston: Pearson Education
Thanks for your attention NEAR EAST UNIVERSITY Department of ELT 22-Nov-2011