Incorporating Multiple-HMM Acoustic Modeling in Large Vocabulary Speech Recognition System
This paper discusses the integration of multiple acoustic models in a large vocabulary speech recognition system, focusing on gender-specific models. Experimental setups, training methods, and results are detailed, highlighting the effectiveness of using multiple-SCHMM modeling. The study demonstrates a 25% error reduction compared to single-SCHMM systems for a 10,000-word dictionary.

Incorporating Multiple-HMM Acoustic Modeling in Large Vocabulary Speech Recognition System
E N D
Presentation Transcript
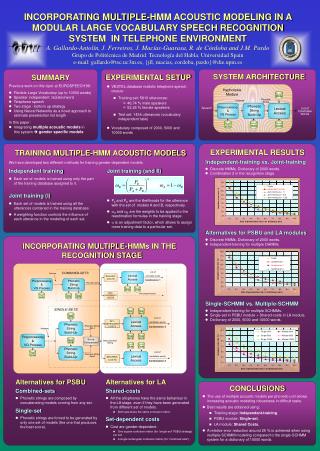
INCORPORATING MULTIPLE-HMM ACOUSTIC MODELING IN A MODULAR LARGE VOCABULARY SPEECH RECOGNITION SYSTEM IN TELEPHONE ENVIRONMENT A. Gallardo-Antolín, J. Ferreiros, J. Macías-Guarasa, R. de Córdoba and J.M. Pardo Grupo de Politécnica de Madrid. Tecnología del Habla. Universidad Spain e-mail: gallardo@tsc.uc3m.es, {jfl, macias, cordoba, pardo}@die.upm.es EXPERIMENTAL SETUP SYSTEM ARCHITECTURE SUMMARY • Previous work on this topic at EUROSPEECH'99: • Flexible Large Vocabulary (up to 10000 words) • Speaker independent. Isolated word • Telephone speech • Two stage - bottom up strategy • Using Neural Networks as a novel approach to estimate preselection list length • VESTEL database realistic telephone speech corpus: • Training set: 5810 utterances: • 46,74 % male speakers • 53,26 % female speakers • Test set: 1434 utterances (vocabulary independent task) • Vocabulary composed of 2000, 5000 and 10000 words • In this paper: • Integrating multiple acoustic models in this system gender specific models TRAINING MULTIPLE-HMM ACOUSTIC MODELS EXPERIMENTAL RESULTS • Independent-training vs. Joint-training • Discrete HMMs. Dictionary of 2000 words. • Combination 2 in the recognition stage. We have developed two different methods for training gender-dependent models: • Independent training • Each set of models is trained using only the part of the training database assigned to it. Joint training (and II) • Joint training (I) • Each set of models is trained using all the utterances contained in the training database. • A weighting function controls the influence of each utterance in the modeling of each set. • PA and PB are the likelihoods for the utterance with the set of models A and B, respectively. • wA and wB are the weights to be applied to the reestimation formulae in the training stage. • a is an adjustment factor, which allows to assign more training data to a particular set. • Alternatives for PSBU and LA modules • Discrete HMMs. Dictionary of 2000 words. • Independent-training for multiple DHMMs. INCORPORATING MULTIPLE-HMMs IN THE RECOGNITION STAGE • Single-SCHMM vs. Multiple-SCHMM • Independent-training for multiple SCHMMs. • Single-set in PSBU module + Shared-costs in LA module. • Dictionary of 2000, 5000 and 10000 words. • Alternatives for PSBU Combined-sets • Phonetic strings are composed by concatenating models coming from any set. Single-set • Phonetic strings are forced to be generated by only one set of models (the one that produces the best score). • Alternatives for LA Shared-costs • All the allophones have the same behaviour in the LA stage, even if they have been generated from different set of models. • Both sets share the same confusion matrix. Set-dependent costs • Cost are gender-dependent. • One square confusion matrix (for “single-set” PSBU strategy) per set. • A single rectangular confusion matrix (for “combined sets”). CONCLUSIONS • The use of multiple acoustic models per phonetic unit allows increasing acoustic modeling robustness in difficult tasks. • Best results are obtained using: • Training stage: Independent-training. • PSBU module: Single-set. • LA module: Shared Costs. • A relative error reduction around 25 % is achieved when using multiple-SCHMM modeling compared to the single-SCHMM system for a dictionary of 10000 words.