Load Shedding in Stream Databases – A Control-Based Approach
190 likes | 229 Views
Load Shedding in Stream Databases – A Control-Based Approach. Yicheng Tu, Song Liu, Sunil Prabhakar, and Bin Yao Department of Computer Science, Purdue University Presented by Chris Mayfield VLDB Conference, Seoul, Korea September 14, 2006. Data stream management systems. Applications

Load Shedding in Stream Databases – A Control-Based Approach
E N D
Presentation Transcript
Load Shedding in Stream Databases – A Control-Based Approach Yicheng Tu, Song Liu, Sunil Prabhakar, and Bin Yao Department of Computer Science, Purdue University Presented by Chris Mayfield VLDB Conference, Seoul, Korea September 14, 2006
Data stream management systems • Applications • Financial analysis • Mobile services • Sensor networks • Network monitoring • More … • Continuous data, discarded after being processed • Continuous query • Data-active query-passive model
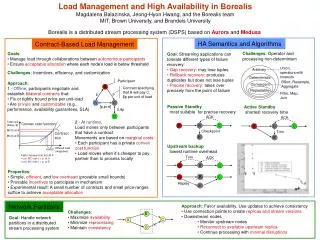
DSMS architecture • Network of query operators (O1 – O3) • Each operator has its own queue (q1 – q4) • Scheduler decides which operator to execute • Query results (Q1, Q2) pushed to clients • Example systems: • Aurora/Borealis • STREAM
Quality in DSMS data processing • Data processing in DSMS is quality-critical • tuple delay • data loss • sampling rate, window size, … • Overloading during spikes degraded quality (delay) • Solution: adjust data loss (i.e., load shedding) • On DSMS side • Eliminating excessive load by dropping data items • The real problem is: tuple delay is the major concern: results generated from old data are useless! How to maintain processing delays while minimizing data loss ?
Related work (load shedding) • Accuracy of aggregate queries under load shedding (Babcock et al., ICDE04) • Data triage (Reiss & Hellerstein, ICDE05) • Put data into an asylum upon overloading • LoadStar (Chi et al., VLDB05) • QoS-driven load shedding (Tatbul et al., VLDB03) • Key questions - When? - How much? - Where? • Use a load shedding roadmap (LSRM) to decide where • Intuitive algorithm to decide when and how much
Example Limitations • Highly dynamic environment is reality • Bursty data input • Variable unit processing cost • Fails to capture current system status (queue length) and output (delay) • Delay positively related to queue length • Example 1. Unbounded increase of delay • Example 2. Unnecessary data loss
Our approach • View load shedding as a control theory problem • Control: manipulation of system behavior by adjusting input • Cruise control of automobiles, room temperature control, etc. • Open-loop (preset) vs. closed-loop (feedback) control • The feedback control loop: • Plant • Monitor • Controller • Actuator • How it works • Error (e) = desirable output (yr) - measured output (y) • Focal point: controller, which maps e to control signal u • Disturbances
Challenges (theory → practice) • Can we model the system? • Analytical model may not be easy to derive • System identification: experimental methods • How to design the controller? • Use control theoretical tools for guaranteed performance • DSMS-specific problems • Lack of real-time measurement of output signal ( y ) • How to set control period (T) • Real system evaluation • we use Borealis in our study
Modeling a DSMS • Borealis data stream manager • Round robin operator scheduler • FIFO waiting queues • For now, fix the per-tuple processing cost c • Proposed model: y = qc where q is the number of outstanding data tuples • Discrete form: y(k) = q(k-1) c • Denote the input load as fiandsystem processing power as fo:
Controller design • Design based on pole placement • Locations tell how fast/well system responds • Guaranteed performance targeting • Convergence rate - responsiveness • Damping - smoothness • The controller: (see appendix for details)
Control period • Provides more complete answer to the question “when to shed load”? • Empirically set in previous studies • Case-by-case decision with some systematic rules • In our problem, a tradeoff between: • Sampling theory (Nyquist-Shannon Theorem): in order to capture the moving trends of the disturbances, higher (shorter) sampling frequency (period) is preferred • Stochastic feature of output ( y ) and parameter ( c ): more samples are needed longer period is preferred • The first factor should be given more weight
Input for experiments • Controller and load shedder implemented in Borealis • Synthetic (“Pareto”) and real (“Web”) data streams • Small query network with variable average processing cost
Experimental results • Experiments for comparison • Aurora – open loop solution • Baseline – a simple feedback method • Target delay: 2 sec • Control period: 1 sec • Total time: 400 sec • For both input types, data loss are almost the same for all three load shedding strategies
Future work • Time-varying DSMS model • For example, time-varying cost c • Possible solution: adaptive control • Adaptation other than load shedding • New disturbances? • Model changes? (i.e. at runtime) • Other database problems
Summary • Load shedding is an effective quality adaptation method • Ad hoc solutions do not work well under dynamic load and system features • We propose an approach to guide load shedding in a highly dynamic environment based on feedback control theory • Initial experimental results performed in a real-world DSMS show promising potential of our approach
Backup - 2 • Lack of robustness of open-loop solution • More optimistic policy adapted in Aurora • Unstable performance • Our solution is robust • Under input streams with different burstiness
Backup - 4 (Model verification) • Feed Borealis with synthetic streams • Input rate: step or sinusoidal function of time • Average processing cost is fixed