
Scalar Processor Design
Scalar Processor Design. Phenomenal advances in its brief lifetime of 30+ years : X2/18mo in 30yr. multi -GFLOPs processors, inspiring and facilitating major innovations in: Embedded microcontrollers (300 millions sold in 2000) Personal computers (150 millions sold in 2000)

Scalar Processor Design
E N D
Presentation Transcript
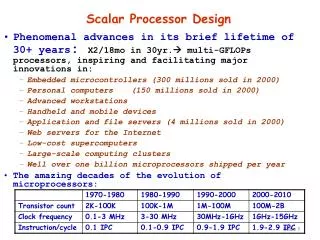
Scalar Processor Design • Phenomenal advances in its brief lifetime of 30+ years: X2/18mo in 30yr. multi-GFLOPs processors, inspiring and facilitating major innovations in: • Embedded microcontrollers (300 millions sold in 2000) • Personal computers (150 millions sold in 2000) • Advanced workstations • Handheld and mobile devices • Application and file servers (4 millions sold in 2000) • Web servers for the Internet • Low-cost supercomputers • Large-scale computing clusters • Well over one billion microprocessors shipped per year • The amazing decades of the evolution of microprocessors:
Scalar Processor Design Past (Milestones): • First electronic computer ENIAC in 1946: 18,000 vacuum tubes, 3,000 cubic feet, 20 2-foot 10-digit registers, 5 KIPs (thousand additions per second); • First microprocessor (a CPU on a single IC chip) Intel 4004 in 1971: 2,300 transistors, 60 KIPs, $200; • Virtual elimination of assembly language programming reduced the need for object-code compatibility; • The creation of standardized, vendor-independent operating systems, such as UNIX and its clone, Linux, lowered the cost and risk of bringing out a new architecture • RISC instruction set architecture paved ways for drastic design innovations that focused on two critical performance techniques: instruction-level parallelism and use of caches
Scalar Processor Design Present (State of the art): • Microprocessors approaching/surpassing 10 GFLOPS; • A high-end microprocessor (<$10K) today is easily more powerful than a supercomputer (>$10million) ten years ago; • While technology advancement contributes a sustained annual growth of 35%, innovative computer design accounts for another 25% annual growth rate a factor of 15 in performance gains!(fig1.1) • Three different computing markets (fig. 1.3): • Desktop Computing –- driven by price-performance (a few hundreds through over 10K); • Servers – availability driven (distinguished from reliability), providing sustained high performance • Embedded Computers – fastest growing portion of the computer market, real-time performance driven, and need to minimize memory and power, as well as ASIC
Scalar Processor Design Present (State of the art): • The Task of the Computer Designer: • Instruction Set Architecture (Traditional view of what Computer Architecture is), the boundary between software and hardware; • Organization, high-level aspects of a computer’s design, such as the memory system, the bus structure, the internal design of CPU, based on a given instruction set architectrue; • Hardware, the specifics of a machine, including the detailed logic design and the packaging technology of the machine. Future (Technology Trends): • A truly successful instruction set architecture (ISA) should last for decades, however it takes an computer architect’s acute observation and knowledge of the rapidly changing technology, in order for the ISA to survive and cope with such changes:
Scalar Processor Design • IC logic technology: transistor count on a chip grows at 55% annual rate (35% density growth rate + 10-20% die size growth) while device speed scales more slowly; • Semiconductor DRAM: density grows at 60% annually while cycle time improves very slowly (decreasing one-third in ten years). Bandwidth per chip increases twice as fast as latency decreases; • Magnetic dish technology: density increases at 100% annual rate since 1990 while access time improves at about a third every ten years; and • Network technology: both latency and bandwidth have been improving, with more focus on bandwidth of late; the increasing importance of networking has led to faster improvement in performance than before—Internet bandwidth doubles every year in the U.S. • Scaling of transistor performance: while transistor density increases quadratically with linear decrease in feature size, transistor performance increases roughly linearly with decrease in feature sizechallenge & opportunity for computer designer! • Wires and power in IC: propagation delay and power needs?
Instruction Set Architecture • ISA should reflect application characteristics: • Desktop computing is compute-intensive, thus focusing on features favoring Integer and FP ops; • Server computing is data-intensive, focusing on integers and char-strings (yet FP ops are still standard in them) • Embedded computing is time-sensitive, memory and power conciouse, thus focusing on code-density, real-time and media data streams. • ISA has been defined as a contract between the software and hardware, or between the program and the machine, thus facilitating independent development of programs and machines.
Instruction Set Architecture • Taxonomy of ISA: • Stack: both operands are implicit on the top of the stack, a data structure in which items are accessed an a last in, first out fashion. • Accumulator: one operand is implicit in the accumulator, a special-purpose register. • General Purpose Register: all operands are explicit in specified registers or memory locations. Depending on where operands are specified and stored, there are three different ISA groups: • Register-Memory:one operand in register and one in memory.Examples: IBM 360/370, Intel 80x86 family, Mototola 68000; • Memory-Memory:both operands are in memory. Example: VAX. • Register=Register (load & store): all operands, except for those in load and store instructions, are in registers. Examples: SPARC (Sun Microsystems), MIPS, Precision Architecture (HP), PowerPC (IBM), Alpha (DEC).
Instruction Set Architecture CA+B Taxonomy of ISA: Examples (a) Stack (e) Memory-Memory (d) Reg-Reg/Load-Store (b) Accumulator (c) Register-Memory TOS Reg. Set Reg. Set Stack Accumulator ALU ALU ALU ALU ALU Memory Memory Memory Memory Memory Push A Push B Add Pop C Load A Add B Store C Load R1,A Add R3,R1,B Store R3,C Load R1,A Load R2,B Add R3,R1,R2 Store R3,C Add C,A,B
Dynamic and Static Interface • Inherent in each ISA’s definition is an associated definition of an interface, called the dynamic and static interface (DSI), that separates what is done statically at compile time versus what is done dynamically at run time. • A key issue in the design of an ISA is the placement of the DSI: Program (Software) Compiler complexity Exposed to software “Static” (DSI) Architecture Hardware complexity Hidden in hardware “Dynamic” Machine (Hardware) ~CISC ~VLIW ~RISC DEL HLL Program DSI-1 DSI-2 DSI-3 Hardware
Processor Performance • Performance Equation: • 1/Performance = Time/Program = (Instuctions/Program)(Cycles/Instructions)(Time/Cycle) = IC * CPI * CCT Where: IC=Instruction Count; CPI=Cycles per Instruction; CCT=Clock cycle time • Performance Optimization: reducing one or more of the three factors (IC, CPI, CCT) • IC: ISA dependent (CISC vs RISC); compiler dependent; dynamic elimination of redundant computation (computation reuse); • CPI: ISA and instruction complexity dependent; microarchitecture dependent (pipelining and speculative execution of instructions); • CCT: microarchitecture; pipelining; clock frequency; pipeline depth; can affect CPI;
Processor Performance • Performance Evaluation: functional (ISA) and performance (CPI) • Trace-driven simulation • Execution-driven simulation Physical execution with software instrumentation Cycle-based performance simulator Traces Traces Physical execution with hardware instrumentation Functional simulator Trace storage Trace-driven Timing simulation Trace generation Execution trace Cycle-based performance simulator Functional simulator (instruction interpretation) Checkpoint and control Functional simulation Execution-driven Timing simulation
Processor Performance • Performance Evaluation: Amdahl’s Law • Idealized pipeline execution profile • Realistic pipeline execution profile • Refined speedup equation : N Pipeline Depth 1 1-g g Pipeline stall Pipeline stall N 1
















