Subspace Representation for Face Recognition
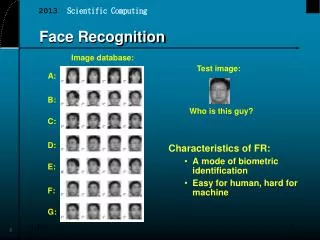
Subspace Representation for Face Recognition. Presenters: Jian Li and Shaohua Zhou. Overview. 4 different subspace representations PCA, PPCA, LDA, and ICA 2 options Kernel v.s. Non-Kernel 2 databases with 3 different variations Pose, Facial expression, and Illumination.


Subspace Representation for Face Recognition
E N D
Presentation Transcript
Subspace Representation for Face Recognition Presenters: Jian Li and Shaohua Zhou
Overview • 4 different subspace representations • PCA, PPCA, LDA, and ICA • 2 options • Kernel v.s. Non-Kernel • 2 databases with 3 different variations • Pose, Facial expression, and Illumination
Subspace representations • Training data X (d,n) • X = [x1, x2, …, xn] • Subspace decomposition matrix W (d,m) • W = [w1, w2, …, wm] • Representation Y (m,n) • Y = W’ * X
PCA, PPCA, LDA and ICA • PCA, in an unsupervised manner, minimizes the representation error ||X – Y||. • LDA, in a supervised manner, minimizes the within-class distance while maximizing the between-class distance. • ICA, in an unsupervised manner, maximizes the independence between Y ’s. • Probabilistic PCA, coming late …
Kernel or Non-Kernel • Often somewhere reduces to some forms related to dot product • Kernel trick • Replacing dot product by kernel function • Mapping the original data space into a high-dimensional feature space • K(x,y) = <f(x) , f(y)> • Gaussian kernel: exp(- 0.5 |x – y|^2/sigma^2)
Gallery, Probe, Pre-processing • Training dataset • Testing dataset • Gallery: Reference images in testing • Probe: Probe images in testing • Pre-processing • Down-sampling • Zero-mean-unit-variance • x = { x - mean(x) } / var(x) • Crop face region only
AT&T Database • Pose variation • 40 classes, 10 images/class, 28 by 23 Set1 Set2 (Mirror of Set1)
FERET Database • Facial expression and illumination variation • 200 classes, 3 images/class, 24 by 21 Set1 Set2 Set3
Probabilistic PCA (PPCA) -- I • PCA only extracts PCs thereby losing probabilistic flavor • PPCA add this by interpreting the reconstruction error as confidence level • y = u + W * x + e • Different choices of e • Factor analysis, • PPCA (Tipping and Bishop ’99) • PCA
Probabilistic PCA (PPCA) -- II • Assume e has covariance matrix, pho*I • R = U * D * U’ • W = Um * (Dm – pho*I) ^(1/2) • Pho = mean of the remaining eigenvalues • Implemented algorithm • B. Moghaddam ’01 • W = Um * (Dm) ^(1/2) • - 2log P(y) = sum (Pci^2/Di) + e^2 / pho + const • Construct inter-person space
Probabilistic KPCA (PKPCA) • Replace PCA by KPCA in the PPCA algorithm • Estimating e by computing sum of all remaining PC’s.
ICA • Independent face • PCA pre-whitening: X1 = U’ * X • Y = W * X1 • Independent facial expression • Y = W * X’
Kernel ICA • F. Bach and M. I. Jordan ‘01 • ‘Kernel trick’ is played when measuring independence • Canonical correlation -- independence
Experimental Setup • Training • Ranking the gallery based on the distance or probability • CMS curve
Distance Metric • SAD, SQD, Correlation (mean removed)
Eigenfaces & Fisherfaces Eigenfaces Fisherfaces
Independent Basis Faces & Facial Features Ind. Faces Ind. Facial Features
Computational load • Training time: • PCA < LDA < PPCA < ICA • KPCA < KLDA < PKPCA << KICA • Testing time: • PCA = LDA = ICA < PPCA • KPCA = KLDA = KICA < PKPCA