Trees and Forests
31/08/2012. Outline. Decision TreesRandom ForestsExtremely Randomized Trees. 31/08/2012. Decision Trees (DT). Classification trees or regression treesPredictive model mapping observations to conclusions about targetsGive descriptions and generalizations of the data.Provides means to easily inte


Trees and Forests
E N D
Presentation Transcript
1. 31/08/2012 Trees and Forests Maria Pavlou
Vision and Information Engineering
Mappin Building
m.pavlou@sheffield.ac.uk
2. 31/08/2012 Outline Decision Trees
Random Forests
Extremely Randomized Trees
3. 31/08/2012 Decision Trees (DT) Classification trees or regression trees
Predictive model mapping observations to conclusions about targets
Give descriptions and generalizations of the data.
Provides means to easily interpret and understand data or underlying model
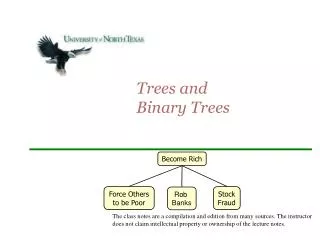
4. 31/08/2012 Decision Tree Structure Each node corresponds to a variable
An arc to a child represents a possible value of that variable
A leaf represents a possible target value given the instance represented by the path from the root.
5. 31/08/2012 Weather Data - Play Tennis?
6. 31/08/2012 Weather Data - Play Tennis? Playing Tennis = Yes:
(Outlook=Sunny & Humidity=Normal)
(Outlook=Overcast)
(Outlook=Rain & Wind=Weak)
7. 31/08/2012 Why Decision Trees? Fast learners, fast testing
Requires little data preparation.
Inexpensive to construct
Virtually parameter free
Easy to understand and interpret.
Handle both numerical and categorical data.
Very popular, good support with available implementations
Performance is comparable to other techniques
8. 31/08/2012 Basic DT Induction Algorithm Create root node N0 containing all instances, S
For each new node
if all instances have same class C
then label the node with C
else
Find �most informative� attribute A (or some test T on A)
Divide node instances assigning to new child nodes
9. 31/08/2012 DT Induction Algorithms Many variants
CART, ID3, C4.5, Random Forests, Extra-trees
Tree type?
Binary, n-way?
Attribute Selection?
Splitting purity, fitness measure?
Stopping criteria?
Pre-pruning?
Pruning?
Overfitting
Diversification & Aggregation
Single or multiple trees (Forests)
10. 31/08/2012 Weather Data - Play Tennis?
11. 31/08/2012 Attribute Selection Compactness
Occam's Razor
Generalization
Smallest tree search NP-complete
Algorithm needs measure of how purely attribute splits the data
12. 31/08/2012 Choosing the split attribute Minimize impurity measure
Entropy
Measures homogeneity of a node.
Maximum (log nc) when records are equally distributed among all classes implying least information
Minimum (0.0) when all records belong to one class, implying most information
13. 31/08/2012 Play Tennis? Entropy Training set S: 14 examples (9 pos, 5 neg)
Notation: S = [9+, 5-]
Computing entropy, if probability is estimated by relative frequency
E([9+,5-]) = - (9/14) log2(9/14) �,
- (5/14) log2(5/14) �,
= 0.940
14. 31/08/2012 Play Tennis? Entropy
15. 31/08/2012 Choosing the split attribute Information Gain
Measures reduction in Entropy achieved because of the split. Choose the split that achieves most reduction (maximizes Gain)
Disadvantage: Tends to prefer splits that result in large number of partitions, each being small but pure.
16. 31/08/2012 Play Tennis? Gain
17. 31/08/2012 Weather Data - Induction
18. 31/08/2012 Weather Data - Induction
19. 31/08/2012 Weather Data - Induction
20. 31/08/2012 Weather Data - Induction
21. 31/08/2012 Weather Data - Induction
22. 31/08/2012 Weather Data - Induction
23. 31/08/2012 Iris Data 3 Classes
50 samples per class
4 dimensional
24. 31/08/2012
25. 31/08/2012
26. 31/08/2012
27. 31/08/2012
28. 31/08/2012
29. 31/08/2012 Stopping Criteria Negligible improvement in Information Gain
Minimum number of instances allowed to split
Pre-pruning, MDL, chi-squared error
30. 31/08/2012 C4.5 DT Algorithm N-way or binary tree structure
Split on Information Gain
Reduce noise overfitting by pruning
Handles missing values
31. 31/08/2012 C4.5 disadvantages Process Intensive
Must compare all possible splits in data at each node.
Sensitive to noise, overfitting.
Partly alleviated by pruning methods.
Low generalization error on complex problems
Requires separate validation data for performance evaluation and pruning.
Poor with very large datasets
32. 31/08/2012 Random Forests Leo Breiman & Adele Cutler
Combination of
Random Subspaces, Tin Kam Ho
Learning via random division of the data space
Data Bootstrapping
Learning on random subsets of data
33. 31/08/2012 Random Forests Algorithm Binary tree
Random selection of attributes to split
Fully grown trees, no pruning
Bootstrap training data
Build multiple trees and aggregate outputs
Built-in error estimation, correlation and strength of trees
Measure of variable importance, instance proximity
Deal with noisy and unbalanced data
Fast to train, test, easily parallelizable
34. 31/08/2012 Aggregating weak learners Definition: a weak learner is a prediction function that has low bias.
Low bias comes at the cost of high variance.
Aggregating many weak learners help give estimates with low bias and variance.
Similar to Boosting, AdaBoost
without weighting training data
Combining trees via averaging or voting
will only be beneficial if the trees are different from each other.
35. 31/08/2012 Noisy Data
36. 31/08/2012 Weak Learner
37. 31/08/2012 Aggregating weak learners Definition: a weak learner is a prediction function that has low bias.
Low bias comes at the cost of high variance.
Aggregating many weak learners help give estimates with low bias and variance.
Similar to Boosting, AdaBoost
Combining trees via averaging or voting
will only be beneficial if the trees are different from each other.
38. 31/08/2012 Average of weak learners
39. 31/08/2012 Aggregating weak learners Definition: a weak learner is a prediction function that has low bias.
Low bias comes at the cost of high variance.
Aggregating many weak learners help give estimates with low bias and variance.
Similar to Boosting, AdaBoost
without weighting training data
Combining trees via averaging or voting
will only be beneficial if the trees are different from each other.
40. 31/08/2012 Random diversity Random trees exhibit good strength, have at least some weak predictive power.
Fully grown trees similar to kd-trees, nearest neighbour classifier
Low correlation between trees
Each tree is grown at least partially at random
Grow each tree on a different random subsample of the training data
Node split selection process is determined partly at random
41. 31/08/2012 RF Attribute Selection At each node
Randomly select about K = sqrt(M) of total attributes M with replacement.
Split node with the best attribute among the K
Radically speeds up tree growing process
42. 31/08/2012 Toy Data
43. 31/08/2012 Single Classification Tree
44. 31/08/2012 25 Classification Trees
45. 31/08/2012 Tree aggregation Classification trees �vote�
assign each case to ONE class only
Winner is the class with the most votes
Votes can be weighted by accuracy of individual trees
Regression trees assign a real predicted value for each case
Predictions are combined via averaging
Results will be much smoother than from a single tree
46. 31/08/2012 Voted Classification
47. 31/08/2012 RF Bootstrapping Each tree grown on random ~2/3 of training data
Remaining 1/3 is called out-of-bag (OOB) data
48. 31/08/2012 RF Bootstrapping Injects variance to individual trees
OOB used to:
give ongoing estimate of generalization error, strength and correlation
how often each record is classified correctly when it belongs to OOB set
determine K and stopping criteria
determine variable importance
determine instance proximity, distance metric
49. 31/08/2012 Extremely Randomized Trees Pierre Geurts et al.
Further improvements on variance
Performance Comparable to RF and others
Easily parallelizable
50. 31/08/2012 Extremely Randomized Trees Binary tree structure
Random selection of attributes to test
Random test point
Weak purity test
Builds multiple trees and aggregates outputs
Super-fast!, Works?
51. 31/08/2012 Toy Data 5 classes
50 samples per class
2-dimnesional
52. 31/08/2012 Toy Data 100 Trees
Fully randomized
Python code courtesy James Hensman
53. 31/08/2012 Toy Data 5 classes
50 samples per class
2-dimnesional
54. 31/08/2012 Toy Data 200 Trees
Weak test on entropy
Python code courtesy James Hensman
55. 31/08/2012 Something to read Ian H. Witten, Data Mining: Practical Machine Learning Tools and Techniques, Second Edition
Random Forests, Leo Breiman http://oz.berkeley.edu/~breiman/RandomForests
Extra-Trees, Pierre Geurts
http://www.montefiore.ulg.ac.be/~geurts
56. 31/08/2012 Some tools WEKA,
http://www.cs.waikato.ac.nz/ml/weka/
Java based, open-source
Orange
http://www.ailab.si/orange/
Python based, open-source