Kuliah Statistik
610 likes | 1.25k Views
Kuliah Statistik. UNISSULA SEMARANG. 1. PENDAHULUAN. A. Statistika dalam Kehidupan Sehari-hari Kemajuan ilmu pengetahuan dan teknologi tidak dapat dipisahkan dari statistika

Kuliah Statistik
E N D
Presentation Transcript
Kuliah Statistik UNISSULA SEMARANG
1. PENDAHULUAN A. Statistika dalam Kehidupan Sehari-hari Kemajuan ilmu pengetahuan dan teknologi tidak dapat dipisahkan dari statistika Jaeger (1990) menyimpulkan bahwa statistika tidak dapat dipisahkan dari kehidupan para peneliti, pendidik, manajer, analis olahraga, analis politik, pengusaha & hampir semua orang yang terdidik. Keperluan akan statistika berbeda-beda, baik tingkat kedalamannya maupun jenis tekniknya
B. Pengertian dan Jenis Statistika Statistika adalah bagian dari matematika yang secara khusus membicarakan cara-cara pengumpulan, analisis dan penafsiran data. • Jenis Statistika berdasarkan pembahasannya: - Statistika matematika /statistika teoritis yang lebih berorientasi pada pemahaman model & teknik-teknik statistika secara matematis. - Statistika Terapan, yang lebih berorientasi pada pemahaman intuitif atas konsep & teknik-teknik statistika serta penggunaannya di berbagai bidang.
Jenis Statistika berdasarkan Tahapan Tujuan Analisisnya: - Statistika Deskriptif Bertugas hanya untuk memperoleh gambaran/ ukuran-ukuran tentang data yang ada di tangan (ukuran sampel, ukuran populasi) - Statistika Inferensial (to infer = menyimpulkan) Kita dapat menggunakan data & ukuran sampel untuk melakukan inferensi tentang populasi (statistika inilah yang disebut statistika inferensial)
Berdasarkan asumsi mengenai distribusi populasi data yang dianalisis, statistika dibedakan menjadi 1. Statistika Parametrik Jenis ini didasarkan pada model distribusi normal 2. Statistika Nonparametrik Statistik ini tidak didasarkan pada suatu model distribusi tertentu • Statistika juga dibedakan berdasarkan jumlah peubah (variabel) terikat (dependent variabel) yang dianalisis, yakni menjadi statistika unvariat & statistika multivariat
C. Pengukuran & Data Statistik • Pentingnya pengukuran dalam penelitian Teknik statistik bukanlah prosedur yang dapat mengubah sampah menjadi kertas atau pupuk yang berharga. Pengukuran merupakan kegiatan untuk menyediakan data yang akan dijadikan masukan dalam analisis statistika. Validitas penelitian antara lain amat bergantung pada validitas data yang diperoleh. Jika data yang diperoleh tidak valid maka kegiatan analisis & penafsiran data yang mengikutinya tidak valid.
2. Jenis data & skala pengukuran Data dapat digolongkan menjadi data diskrit & data kontinu. Banyaknya anak di suatu keluarga, jumlah rumah di suatu desa, banyaknya penduduk disuatu daerah, dan jumlah mobil di kantor tertentu merupakan contoh data diskrit (merupakan bilangan bulat) Sedangkan tingkat kecerdasan, prestasi belajar, berat badan, dan daya tahan mobil merupakan contoh data kontinu (termasuk bilangan desimal)
Dilihat dari skala pengukuran yang digunakan, data dibagi menjadi menjadi 4 jenis yang bersifat hirarkis, yaitu: 1. Data Nominal Data ini memiliki skala yang bersifat kategorikal/ pengelompokan (jenis kelamin, warna kulit, agama), digunakan untuk mengenali identitas subyek. 2. Data Ordinal Data ini memiliki skala yang menunjukkan perbedaan tingkatan subjek secara kuantitatif (data yang dinyatakan dalam bentuk peringkat atau rangking) Data ini selain memiliki sifat yang dimiliki data nominal juga menunjukan kedudukan subjek dalam suatu kelompok pada suatu variabel. Termasuk aplikasi skala likert 3. Data Interval Selain memiliki kedua ciri diatas, data ini juga memiliki sifat kesamaan jarak (equality of interval) antara nilai yang satu dengan nilai yang lain 4. Data Rasio Data rasio hampir sama dengan data interval. Yakni keduannya memiliki ketiga sifat diatas ( menunjukan klasifikasi & kedudukan subjek dalam suatu kelompok) contoh: 20 kg adalah 2 x 10 kg dsb
D. Penelitian Kuantitatif Menurut Sukaji, 1992: kemajuan pesat negara2 industri maju dan negara2 industri baru ternyata lebih tergantung pada mutu SDM, kegiatan penelitian serta inovasi teknologi daripada Sumberdaya alam. 1. Memahami makna penelitian Gay (1982), merumuskan penelitian sebagai suatu proses sistematis untuk menjawab suatu pertanyaan. Nasution (1992), menggambarkan sifat-sifat penelitian, yaitu penelitian adalah suatu upaya pengkajian yang cermat, teratur & tekun mengenai suatu masalah. • Penggolongan penelitian - Penelitian eksperimental: termasuk eksperimen semu yang tidak melakukan random assigment. Penelitian eksperimental dari penelitian lainnya adalah adanya manipulasi peubah bebas. - Penelitian Korelasional Penelitian korelasional sendiri merupakan Penelitian yang peubah bebasnya tidak dimanipulasi
Cara pandang lain yang melihat penelitian berada pada suatu garis kontinum yang membentang diantara dua kutub, penelitian murni di suatu pihak dan penelitian terapan dipihak lain. • Dalam arti yang sesungguhnya, penelitian murni bertujuan untuk memperoleh temuan yang berguna bagi pengembangan ilmu pengetahuan, sedangkan penelitian terapan bertujuan untuk memperoleh temuan bagi perbaikan keadaan yang tengah berlangsung.
3. Penggolongan peubah penelitian Beberapa jenis peubah yang sangat penting dipahami antara lain (4): a. Peubah terikat, yaitu peubah yang dipengaruhi oleh peubah lain b. Peubah bebas, yaitu peubah yang mempengaruhi peubah lain c. Peubah Kontrol, yaitu peubah yang pengaruhnya kepada peubah terikat dikendalikan d. Peubah Moderator, yaitu peubah yang mempengaruhi hubungan antara peubah bebas dengan peubah terikat
4. Hubungan Antara Peubah Penelitian 1. Hubungan Kausal (pengaruh) 2. Hubungan Korelasional 3. Hubungan Perbandingan 5. Validitas Penelitian Validitas penelitian diklasifikasikan menjadi: 1. Validitas Internal, berkaitan dengan keyakinan peneliti tentang kesahihan hasil penelitian 2. Validitas Eksternal, berkaitan dengan tingkat generalisasi penelitian yang diperoleh • Validitas Internal dapat ditingkatkan dengan cara kumulatif a. Melakukan pengukuran yang valid & reliabel atas seluruh peubah yang dikaji b. Mengontrol peubah yang diduga mempengaruhi peubah terikat
Penelitian eksperimen di laboratorium biasanya memiliki validitas yang lebih tinggi dibandingkan dengan penelitian lapangan • Salah satu yang mendukung validitas eksternal suatu penelitian adalah pemilihan subjek secara acak, sehingga sampel yang diteliti dapat mewakili populasi yang diharapkan. • Perbedaan validitas internal & validitas eksternal biasanya lebihmudah dikendalikan pada penelitian lapangan daripada penelitian laboratoris
2. TABEL DAN GRAFIK • Data statistik dan hasil penelitian sering disajikan dalam bentuk tabel & grafik. Sebuah grafik atau tabel dapat mewakili ratusan atau ribuan kata dalam suatu bentuk yang kompak dan menarik. A. Daftar Distribusi Frekuensi Langkah-langkah adalah: 1. Menentukan rentang 2. Menentukan panjang kelas 3. Menentukan banyak kelas 4. Menyusun interval kelas 5. Menghitung frekuensi untuk setiap kelas
R= Nilai terbesar – Nilai terkecil 1. Rentang: Suatu perangkat data yang biasanya dilambangkan dengan huruf R adalah skor terbesar dikurangi skor terkecil. 2. Banyak Kelas: Banyak kelas menunjukkan jumlah interval kelas yang diperlukan untuk mengelompokan suatu perangkat data. 3. Panjang Kelas: Panjang kelas (p) atau interval (I) menunjukkan banyaknya angka (nilai) yang tercakup oleh suatu interval kelas bk=1+3,3 log n
4. Interval Kelas: Untuk menyusun interval kelas, perlu ditentukan dahulu bilangan awal untuk interval kelas pertama (paling bawah) - merupakan kelipatan dari P - < skor terkecil 5. Frekuensi: Frekuensi setiap kelas dapat diperoleh dengan cara mentally (turus) setiap nilai yang ada pada interval kelas masing-masing dan kemudian menjumlahkan banyaknya tally (turus) yang didapat
B. Grafik Perangkat data statistik dapat ditampilkan secara visual dalam bentuk grafik 1. Histogram Merupakan suatu grafik yang menggambarkan sebaran frekuensi suatu perangkat data dalam bentuk batang 2. Frekuensi Poligon pada Histogram diasumsikan bahwa skor-skor pada interval kelas meyebar secara merata. Contoh dalam Excel
3. UKURAN GEJALA PUSAT A. Modus Merupakan nilai yang paling sering muncul dalam suatu pengukuran - kasus sederhana - kasus interval klas dimana: b : batas bawah interval kelas dengan frekuensi terbanyak p : panjang kelas b1 : frekuensi terbanyak - frekuensi kelas sebelumnya b2: frekuensi terbanyak - frekuensi interval kelas sesudahnya
P(n/2-fk11) Me= X11+ fi B. Median merupakan titik/ nilai yang membagi seperangkat data menjadi dua bagian sama banyak dimana: Me : Median X11 : batas nyata bawah kelas median p : panjang kelas n : banyak data fk11: frekuensi kumulatif interval kelas di bawah kelas median fi : frekuensi kelas median
n X= fiXi X= X i-1 n n k X= fiXi i-1 k ni i-1 C. Rata-rata Merupakan ukuran gejala pusat yang sering digunakan Rumus lain yang dapat ditulis adalah: D. Menentukan Rata-rata dari sejumlah sampel
X Me Mo X Mo Me Mo Me X E. Hubungan antara Modus, median & Rata-rata gambar dibawah menunjukkan perbandingan letak modus, median & rata-rata dalam tiga macam bentuk distribusi a. Data yang distribusinya simetris Mo= Me= X b. data yang distribusinya juling ke negatif X < Me < Mo c. data yang distribusinya juling ke positif Mo< Me < X c=juling + a = simetris b = juling -
Dalam kegiatan penelitian, rata-rata lebih sering digunakan kepada ukuran lainnya karena peneliti tidak hanya hendak menggambarkn keaadaan sampel, tapi juga ingin melakukan referensi tentang keadaan populasinya F. Kuartil, desil & Persentil sejalan dengan konsep median kita juga memiliki ukuran statistik yang dikenal dengan sebutan kuartil, desil & persentil Tiga nilai kuartil (K1, K2 dan K3), sembilan nilai desil (D1-D9) dan 99 nilai persentil (Pi-P99) K2 = D5 = P50 = Median, K1 = P25 dan D6 = P60
4. UKURAN DISPERSI DAN VARIASI • Statistika sering disebut studi tentang variasi karena membahas dan menyediakan cara-cara untuk menyelidiki variasi gejala alam sosial serta membuat kesimpulan tentang hal-hal yang melatar belakangi terjadinya variasi (Ferguson & Takane, 1989) • Para ahli statistika telah mengusulkan sejumlah ukuran yang dapat membantu memahami variasi suatu perangkat data. Rentang dapat diartikan sebagai selisih antara skor terbesar dan skor terkecil pada suatu perangkat data A. Rentang (R) Merupakan ukuran yang paling sederhana dan kasar tentang variasi suatu perangkat data. Rentang dapat diartikan juga sebagai selisih antara skor terbesar dan skor terkecil pada suatu perangkat data
Rentang jarang digunakan utuk menggambarkan variasi perangkat data, karena beberapa alasan berikut yang saling berkaitan (Shavelson, 1988: Ferguson & Takane, 1989): 1. Rentang merupakan ukuran yang tidak stabil 2. Rentang tidak mencerminkan pola variasi suatu distribusi data 3. Rentang bergantung pada besarnya sampel (n) B. Rentang Antar Kuartil RAK = K3-K1 = P75-P25 dimana: RAK: Rentang Antar Kuartil K1 : Nilai kuartil ke-1 K2 : Nilai kuartil ke-2 P75 : Nilai persentil ke-75 P25 : Nilai persentil ke-25
n x = [Xi-X] n=1 n C. Rata-rata Simpangan merupakan jumlah harga mutlak skor simpangan dibagi dengan banyaknya data (n) D. Variasi (s2) dan Simpangan Buku (s) Merupakan dua buah ukuran yang paling sering digunakan tentang variasi suatu perangkat data Variasi adalah kuadrat dari simpangan baku, & sebaliknya, simpangan baku adalah akar.
n S2 = (Xi -)2 i=1 n • Contoh, mengambil sampel yang terdiri dari 40 subjek dari suatu populasi. Secara teoritis, populasi itu terdiri dari N subjek (N= jumlah anggota populasi) yang memiliki parameter tertentu. Seperti rata-rata () dan variasi (2). Sampel dilambangkan dengan huruf n (disini n= 40). Secara teknis, variasi sampel tersebut kemudian dapat ditentukan dengan rumus: dimana: S2 : variasi sampel Xi : skor (nilai) ke-I pada suatu perangkat data : rata-rata populasi n : jumlah sampel (banyaknya data) Merupakan cara menentukan sampel yang tidak bias terhadap variasi populasinya.
n S2 = (Xi -X)2 i-1 n-1 • Cara menentukan sampel yang tidak bias terhadap variasi populasinya. Variasi sampel dapat ditulis kembali menjadi rumus: Untuk jumlah data kecil dibagi n Untuk jumlah data besar dibagi n-1 • Simpangan baku adalah akar dua dari variasi seperti terlihat pada rumus diatas. Simpangan baku yang sering dilambangkan dengan huruf s untuk simpangan baku sampel dan untuk simpangan baku populasi makin bervariasi suatu perangkat data makin besarlah simpangan bakunya, dan sebaliknya
Besaran variasi dan simpangan baku sangat bergantung pada skala data. Data yang dicatat dalam skala satuan cenderung memiliki simpangan baku yang lebih kecil daripada data yang dicatat dalam skala puluhan • Perlu dicari suatu ukuran variasi yang tidak terlalu tergantung kepada skala data. Masalah ini memunculkan pemikiran untuk menggunakan rasio simpangan baku terhadap rata-ratanya yang kemudian dikenal istilah koefisien variasi (KV) yang dapat diperoleh dengan menggunakan rumus KV= s X • Variasi antara suatu perangkat data dapat dibandingkan dengan variasi perangkat data lain dengan cara membandingkan kaefisien variasinya tanpa harus khawatir terhadap skala datanya karena koefesien variasi telah memperhitungkan perbedaan skala data.
E. Skor Baku (z) merupakan skor mentah dikurangi rata-ratanya skor baku (yang dikembangkan dengan z dan dikenal dengan sebutan z-score) dapat diperoleh dengan rumus Statistika inferensial banyak menggunakan distribusi normal baku (standart normal distribution) sebagai model distribusi data yang hendak dianalisis. Distribusi normal baku itu tidak lain adalah distribusi seperangkat skor baku (z) sehingga dikenal dengan istilah distribusi z (z-distribution)
Tugas 1 • Buat/ Kumpulkan kira-kira 50 data sesuai bidang tugas. • Tentukan Rentang data, Jumlah Kelas dan Panjang kelas • Tentukan jumlah masing-masing kelas • Tentukan ukuran tendensi sentral: • Mean, Median dan Modus • Tentukan jenis distribusi datanya
Tugas 2 Dari data tugas 1, tentukan: a. Variansi (s2) b. Simpangan baku (s) c. Koefisien Variasi (KV)
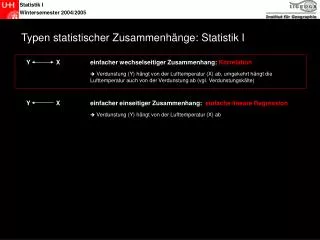
5. REGRESI LINEAR SEDERHANA • Istilah ini digunakan untuk analisis regresi yang melibatkan sebuah peubah bebas (X) dan sebuah peubah terikat (Y) . Pemahaman atas regresi linier sederhana ini merupakan dasar untuk memahami regresi linier jamak (multiple linier regretion) dan model regresi lainnya. • Model Regresi sederhana mengatakan pada kita bahwa setiap nilai pada peubah Y merupakan jumlah dari tiga komponen, yaitu Intercept, koefesien regresi kali nilai pada peubah X, dan galat prediksi ( R ) b = Intercept b1 = koefisien regresi
Menemukan Harga dan Kolom tabel yang diperlukan untuk menemukan koefesien dengan menggunakan rumus
6. Distribusi Normal • Distribusi normal dapat dipandang sebagai model atau dasar teori statistika moderen • Distribusi normal adalah suatu model yang didefinisikan dengan rumus: • Dimana y = ordinat grafik x = skor yang diperoleh m = rata2 populasi s = simpangan baku populasi = 3,1416 e = 2,7183
Distribusi normal berbentuk lonceng (bell-shape) sehingga sering disebut bell shape distribution. Model ini memiliki empat karakteristik: • Unimodal: satu modus • Simetrik : distribusi sebelum dan sesudah median sama • Modus = Median = Mean • Asimtotik : kurva distribusi tidak akan menyentuh absisnya
Daerah dibawah kurva normal • Luas daerah 0 ke z dapat diperoleh dengan: • Luas daerah dibawah normal dari 0 ke z ditabelkan
Pada pengukuran 200 subyek yang diambil secara acak dari populasi N=1000 menghasilkan: • Mean sampel = 40 • Simpangan baku = 10 • Berapa persen subyek yang memperoleh skor antara 40 dan 55? • Berapa persen subyek yang memperoleh skor di atas 55? • Berapa persen subyek yang memperoleh skor di bawah 35? • Berapa skor yang dicapai oleh mereka yang tergolong 10% terbesar?
Pada pengukuran IQ terhadap sampel 100 siswa dari populasi 500 siswa menghasilkan: • Mean sampel = 120 • Simpangan baku = 10 • Berapa siswa yang IQ antara 120 dan 130? • Berapa jumlah siswa yg IQ diatas 130? • Berapa IQ mereka yg merupakan 5% siswa tertinggi?
Mencari data sekitar 100 buah • Menentukan jumlah kelas • Menentukan interval kelas • Menentukan Mean, Median dan Modus • Menentukan varian dan Deviasi Standar
Tugas Matematika Terapan • 1. Kumpulkan data sebanyak 50 buah kemudian tentukan: • a. Rentang data • b. Banyak kelas dan panjang kelas • c. Daftar distribusi frekwensi • d. Grafik histogram • e. Grafik poligon • f. Grafik distribusi dalam % 2. Tentukan Mean, Median dan Modus data kelas di atas. Berdasar hasilnya bagaimana tipe distribusinya
3. Berdasar data sebelumnya tentukan ukuran dispersinya dengan: • Variasi (s2) • Simpangan Baku (s) • Koefisien variasi (kv) • 4. Tentukan 8 data untuk x dan y yang memiliki kecenderungan yang sama: • Buat grafik titik2nya • Buat tabel dengan kolom x, y, x2, xy, y2 • Tentukan nilai intercept (b0) dan koefisien regresinya (b1) • Tentukan koefisien korelasinya (r) • Bagaimana pendapat tentang hasil yang didapat
Furqon, ph.D. , 2001, Statistika terapan untuk penelitian, ISBN 979-8433-13-0, CV Alfabeta, Bandung, 230p • Sugiono, Dr. & Eri ibowo S.Pd., Statistika penelitian dan Aplikasi dengan SPSS 10.0 for Window, ISBN 979-8433-50-3, CV Alfabeta, Bandung, 238p