Multiple Sequence Alignment (MSA) and Phylogeny
Multiple Sequence Alignment (MSA) and Phylogeny . MSA input: multiple sequence Fasta file.


Multiple Sequence Alignment (MSA) and Phylogeny
E N D
Presentation Transcript
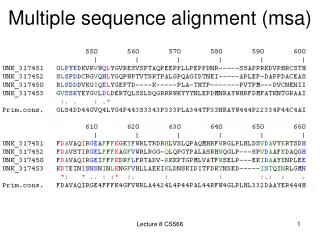
MSA input: multiple sequence Fasta file >gi|10835167|ref|NP_000607.1| CD4 antigen precursor [Homo sapiens] MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLT KGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLT LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV RCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI >gi|57113961|ref|NP_001009043.1| CD4 antigen [Pan troglodytes] MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQTKILGNQGSFLT KGPSKLNDRVDSRRSLWDQGNFTLIIKNLKIEDSDTYICEVGDQKEEVQLLVFGLTANSDTHLLQGQSLT LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV RCRHRRRQAQRMSQIKRLLSEKKTCQCPHRFQKTCSPI >gi|50054438|ref|NP_001001908.1| CD4 antigen [Sus scrofa] MDPGTSLRHLFLVLQLAMLPAASGTQEKYLVLGKAGDLAELPCHSSQKKNLPFNWKNSNQTKILGGHGSF WHTASVTELTSRLDSKKNMWDHGSFPLIIKNLEVTDSGIYICEVEDKRIEVQLLVFRLTASVTRVLLGQS LTLTLEGPSGSHPTVQWKGPGNKSKNDVKSLLLPQVGLEDSGLWTCTVSQDQKTLVFRSNIFVLAFQKVP STVYVKEGDQVALSFPLTFEAESLSGELMWRQTKGASSPQSWITFSLKDRKVTVQKSLQNLKLRMAEKLP LQITLLQALPQYAGSGNLTLVLPEGRLHREVNLVVMRATQSKNEVTCEVLGPTPPKVVLSLKLGNQSMKV SDQQKLVTVLDPEAGMWRCLLRDKDKVLLESQVEVLPTAFTRAWPELLASVIGGIIGLLFLAGFCIACVK CWHRRRRAERMSQIKRLLSEKKTCQCAHRQQKNYSLT >gi|6978631|ref|NP_036837.1| Cd4 molecule [Rattus norvegicus] MCRGFSFRHLLPLLLLQLSKLLVVTQGKTVVLGKEGGSAELPCESTSRRSASFAWKSSDQKTILGYKNKL LIKGSLELYSRFDSRKNAWERGSFPLIINKLRMEDSQTYVCELENKKEEVELWVFRVTFNPGTRLLQGQS LTLILDSNPKVSDPPIECKHKSSNIVKDSKAFSTHSLRIQDSGIWNCTVTLNQKKHSFDMKLSVLGFAST SITAYKSEGESAEFSFPLNLGEESLQGELRWKAEKAPSSQSWITFSLKNQKVSVQKSTSNPKFQLSETLP LTLQIPQVSLQFAGSGNLTLTLDRGILYQEVNLVVMKVTQPDSNTLTCEVMGPTSPKMRLILKQENQEAR VSRQEKVIQVQAPEAGVWQCLLSEGEEVKMDSKIQVLSKGLNQTMFLAVVLGSAFSFLVFTGLCILFCVR CRHQQRQAARMSQIKRLLSEKKTCQCSHRMQKSHNLI
Uploaded sequences A little unclear…
Edit Fasta headers… >Homo_sapiens_CD4 <gi|10835167|ref|NP_000607.1| CD4 antigen precursor [Homo sapiens] MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQIKILGNQGSFLT KGPSKLNDRADSRRSLWDQGNFPLIIKNLKIEDSDTYICEVEDQKEEVQLLVFGLTANSDTHLLQGQSLT LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV RCRHRRRQAERMSQIKRLLSEKKTCQCPHRFQKTCSPI MNRGVPFRHLLLVLQLALLPAATQGKKVVLGKKGDTVELTCTASQKKSIQFHWKNSNQTKILGNQGSFLT KGPSKLNDRVDSRRSLWDQGNFTLIIKNLKIEDSDTYICEVGDQKEEVQLLVFGLTANSDTHLLQGQSLT LTLESPPGSSPSVQCRSPRGKNIQGGKTLSVSQLELQDSGTWTCTVLQNQKKVEFKIDIVVLAFQKASSI VYKKEGEQVEFSFPLAFTVEKLTGSGELWWQAERASSSKSWITFDLKNKEVSVKRVTQDPKLQMGKKLPL HLTLPQALPQYAGSGNLTLALEAKTGKLHQEVNLVVMRATQLQKNLTCEVWGPTSPKLMLSLKLENKEAK VSKREKAVWVLNPEAGMWQCLLSDSGQVLLESNIKVLPTWSTPVQPMALIVLGGVAGLLLFIGLGIFFCV RCRHRRRQAQRMSQIKRLLSEKKTCQCPHRFQKTCSPI MDPGTSLRHLFLVLQLAMLPAASGTQEKYLVLGKAGDLAELPCHSSQKKNLPFNWKNSNQTKILGGHGSF WHTASVTELTSRLDSKKNMWDHGSFPLIIKNLEVTDSGIYICEVEDKRIEVQLLVFRLTASVTRVLLGQS LTLTLEGPSGSHPTVQWKGPGNKSKNDVKSLLLPQVGLEDSGLWTCTVSQDQKTLVFRSNIFVLAFQKVP STVYVKEGDQVALSFPLTFEAESLSGELMWRQTKGASSPQSWITFSLKDRKVTVQKSLQNLKLRMAEKLP LQITLLQALPQYAGSGNLTLVLPEGRLHREVNLVVMRATQSKNEVTCEVLGPTPPKVVLSLKLGNQSMKV SDQQKLVTVLDPEAGMWRCLLRDKDKVLLESQVEVLPTAFTRAWPELLASVIGGIIGLLFLAGFCIACVK CWHRRRRAERMSQIKRLLSEKKTCQCAHRQQKNYSLT MCRGFSFRHLLPLLLLQLSKLLVVTQGKTVVLGKEGGSAELPCESTSRRSASFAWKSSDQKTILGYKNKL LIKGSLELYSRFDSRKNAWERGSFPLIINKLRMEDSQTYVCELENKKEEVELWVFRVTFNPGTRLLQGQS LTLILDSNPKVSDPPIECKHKSSNIVKDSKAFSTHSLRIQDSGIWNCTVTLNQKKHSFDMKLSVLGFAST SITAYKSEGESAEFSFPLNLGEESLQGELRWKAEKAPSSQSWITFSLKNQKVSVQKSTSNPKFQLSETLP LTLQIPQVSLQFAGSGNLTLTLDRGILYQEVNLVVMKVTQPDSNTLTCEVMGPTSPKMRLILKQENQEAR VSRQEKVIQVQAPEAGVWQCLLSEGEEVKMDSKIQVLSKGLNQTMFLAVVLGSAFSFLVFTGLCILFCVR CRHQQRQAARMSQIKRLLSEKKTCQCSHRMQKSHNLI >Pan_troglodytes_CD4 >gi|57113961|ref|NP_001009043.1| CD4 antigen [Pan troglodytes] >Sus_scrofa_CD4 >gi|50054438|ref|NP_001001908.1| CD4 antigen [Sus scrofa] >gi|6978631|ref|NP_036837.1| Cd4 molecule [Rattus norvegicus] >Rattus_norvegicus_CD4
Uploaded sequences Much better
The Newick tree format is used to represent trees as strings A C B D In Newick format: ((A,C),(B,D)); • Each pair of parenthesis () encloses a clade in the tree • A comma “,” separates the members of the corresponding clade • A semicolon “;” is always the last character
Step 4: View tree with NJPlot Note: unrooted tree
Swapping nodes Note: The order inside a split doesn’t matter
Bootstrap A. Resample (100-1000 time). 12345 100 1 : ATCTG…A 2 : ATCTG…C 3 : ACTTA…C 4 : ACCTA…T 12345 100 1 : AATTT…T 2 : AATTT…G 3 : AACTT…T 4 : AACTT…T 11244 x 12345 100 1 : TTTAT…T 2 : TAACC…G 3 : TAACC…T 4 : TGGGA…T 47789…x 12345 100 1 : AGGTA…T 2 : AGGAC…G 3 : AAAAC…A 4 : AAAGG…C 15578… x
Sp1 Sp2 Sp3 Sp4 Bootstrap B. Reconstruct a tree from each data set. 12345 100 1 : AATTT…T 2 : AATTT…G 3 : AACTT…T 4 : AACTT…T 11244 x 12345 100 1 : TTTAT…T 2 : TAACC…G 3 : TAACC…T 4 : TGGGA…T 47789…x 12345 100 1 : AGGTA…T 2 : AGGAC…G 3 : AAAAC…A 4 : AAAGG…C 15578… x Sp1 Sp1 Sp2 Sp2 Sp3 Sp3 Sp4 Sp4
Sp1 Sp2 Sp3 Sp4 Bootstrap C. We compute the majority rule consensus. Sp1 Sp1 Sp2 Sp2 Sp3 Sp3 Sp4 Sp4 In 67% of the data sets, the split between SP1+SP2 and the rest of the tree was found. 67% Sp1 100% Sp2 Sp3 Sp4
Bootstrap values on NJPlot Note:ClustalX saves trees with .ph extension. Trees with bootstrap are saved with .phb extension
Detecting selection forces using phlogeny (ConSeq, ConSurf, Selecton)
“Important”sites evolve slower than “unimportant” ones.
Conservation scores: • The scores are standardized: the average score for all residues is zero, and the standard deviation is one • The lowest score represents the most conserved site in the protein • negative values: slowly evolving (= low evolutionary rate), conserved sites • The highest score represents the most variable site in the protein • positive values: rapidly evolving (= fast evolutionary rate), variable sites • Scores are relative to the protein. Scores of different proteins are incomparable !!!
Conservation in the structure Protein core:structurally constrained - usually conserved Active site: functionally constrained - usually conserved Surface loops: tolerant to mutations - usually variable Active site Surface loops Hydrophobic core
http://consurf.tau.ac.il Same algorithm as ConSeq, but here the results are projected onto the 3D structure of the protein
ConSeq/ConSurf user intervention(advanced options) • Choosing the method for calculating the amino-acid conservation scores: (Bayesian/Max Likelihood) • Entering your own MSA file • Performing the MSA using: (MUSCLE/CLUSTALW) • Collecting the homologs from: (SWISS-PROT/UniProt) • Max. number of homologs: (50) • No. of PSI-BLAST iterations: (1) • PSI-BLAST 3-value cutoff: (0.001) • Model of substitution for proteins: (JTT/Dayhoff/mtREV/cpREV/WAG) • Entering your own PDB file • Entering your own TREE file
Solution – look at the DNA Adaptive evolution = Positive selectionNon-syn > Syn Purifying selectionSyn > Non-syn NeutralselectionSyn = Non-syn
Ka/Ks also known as… (or dn/ds, or ω) Selection score (Ka/Ks) < 1 purifying selection Selection score (Ka/Ks) > 1 positive selection Selection score (Ka/Ks) = 1 no selection Ka Ks Non-synonymous mutation rate Synonymous mutation rate
Selecton input Codon-level sequences !!! • The user must provide the sequences – no psi-blast option • Coding sequences • Only ORF • No stop codons • If an MSA is provided it must be codon aligned(RevTrans)
> 0.05 (a) accept H0 < 0.05 (a) reject H0 P-value Solution: statistics helps us to compare between hypotheses • H0: There’s no positive selection • H1: There is positive selection • H0: compute the probability (likelihood) of the data using a model that does not account for positive selection • H1: compute the probability (likelihood) of the data using a model that does account for positive selection • Perform a statistical test to accept or reject H0 (likelihood ratio test)
Results Human rhesus swaps at sites 332, 335-340 confer human resistance to HIV and rhesus resistance to SIV