Download

1 / 85
870 likes | 1.07k Views
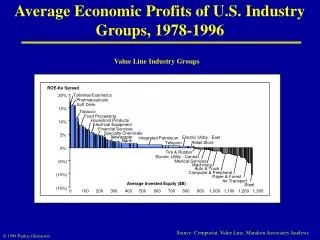
Carl de Marcken’s dissertation 1996. The unsupervised acquisition of a lexicon from continuous speech. “the unsupervised acquisition of a lexicon, given no prior language-specific knowledge.”. T H E R E N T I S D U E. A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7

E N D
Carl de Marcken’s dissertation 1996 The unsupervised acquisition of a lexicon from continuous speech
“the unsupervised acquisition of a lexicon, given no prior language-specific knowledge.”
T H E R E N T I S D U E A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 9 ERE 10
T H E R E N T I S D U E After character 1: Best analysis: T: 3 bits A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 9 ERE 10
T H E R E N T I S D U E After character 1: Best (only) analysis: T: 3 bits After character 2: (1,2) not in lexicon (1,1)’s best analysis + (2,2) which exists: 3 + 3 = 6 bits A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 9 ERE 10
T H E R E N T I S D U E After character 1: Best (only) analysis: T: 3 bits After character 2: (1,2) not in lexicon (1.1)’s best analysis + (2,2) which exists: 3 + 3 = 6 bits (WINNER) After character 3: (1,3) is in lexicon: THE: 3 bits (1,1) best analysis + (2,3) which exists: 3 + 4 = 7 bits T-HE (1,2) best analysis + (3,3): T-H-E: 6 + 3 = 9 bits THE wins (3 bits) A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 7 ERE 8
T H E R E N T I S D U E A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 7 ERE 8 After character 1: Best (only) analysis: T: 3 bits After character 2: (1,2) not in lexicon (1,1)’s best analysis + (2,2) which exists: 3 + 3 = 6 bits After character 3: (1,3) is in lexicon: THE: 3 bits (1,1) best analysis + (2,3) which exists: 3 + 4 = 7 bits T-HE (1,2) best analysis + (3,3): T-H-E: 6 + 3 = 9 THE wins After character 4: (1,4) not in lexicon; (2,4) not in lexicon; (3,4) not in lexicon; best up to 3: THE plus R yields THE-R, cost is 3 + 3 = 6. (Winner, sole entry)
T H E R E N T I S D U E A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 7 ERE 8 1: T 3 2: T-H 6 3: THE 3 4: THE-R 6 5: (1,5) THERE: 5 (1,1) + (2,5)HERE = 3 + 5 = 8 (1,2) + (3,5)ERE = 6 + 10 = 16 (4,5) not in lexicon (1,4) + (5,5) = THE-R-E = 6 + 3 = 9 THERE is the winner (5 bits) 6: (1,6) not checked because exceeds lexicon max length (2,6) HEREN not in lexicon (3,6) EREN not in lexicon (4,6) REN not in lexicon (5,6) EN not in lexicon (1,5) + (6,6) = THERE-N = 5 + 3 = 8 Winner
T H E R E N T I S D U E A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 7 ERE 8 1: T 3 2: T-H 6 3: THE 3 4: THE-R 6 5 THERE 5 6 THERE-N 8 7: start with ERENT: not in lexicon (1,3) + (4,7): THE-RENT=3 + 7 = 10 ENT not in lexicon NT not in lexicon (1,6) + (7,7) = THERE-N-T 8 + 3 = 11 THE-RENT winner (10 bits)
T H E R E N T I S D U E A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 7 ERE 8 1: T 3 2: T-H 6 3: THE 3 4: THE-R 6 5 THERE 5 6 THERE-N 8 7 THE-RENT 10 8 Start with RENTI: not in lexicon ENTI, NTI, TI, none in lexicon (1,7) THE-RENT + (8,8) I = 10 + 3 = 13 The winner by default 9: Start with ENTIS: not in lexicon, nor is NTIS (1,6) THERE-N + (7,9)TIS = 8 + 8 = 16 (1,7) THE-RENT + (8,9) IS= 10 + 4 = 14 (1,8) THE-RENT-I + (9,9) S = 13 + 3 = 16 THE-RENT-IS is the winner (14)
T H E R E N T I S D U E A,B,C… 3 bits each HE 4 THE 3 HERE 5 THERE 5 RENT 7 IS 4 TIS 8 DUE 7 ERE 8 1: T 3 2: T-H 6 3: THE 3 4: THE-R 6 5 THERE 5 6 THERE-N 8 7 THE-RENT 10 8 THE-RENT-I 13 9 THE-RENT-IS 14 10: Not found: NTISD, TISD, ISD, SD (1,9) THE-RENT-IS + (10,10) D = 14 + 3 = 17 11: Not found: TISDU, ISDU, SDU, DU; (1,10) THE-RENT-IS-D + U = 17 + 3 = 20 Winner: THE-RENT-IS-D-U (20) 12: Not found: ISDUE, SDUE; (1,9) THE-RENT-IS + (10,12) DUE = 14+7 = 21; UE not found; WINNER! (1,11) THE-RENT-IS-D-U + (12,12) E = 20 + 3 = 23
Bigger strategy (special case of EM) • We have used these parameters (log probabilities) to find counts. We can either use the single best parse of a string (“Viterbi”), or the distribution from the final set of parses. In the latter case, we split up the count of “1” for each word over the words in each parse.
2nd stage of EM: • With these pseudo-counts on words computed on every sentence (string) in the corpus, we recompute our probabilities (hence, log probabilities) – and then do it all over again. • Probabilities-> Counts -> Probabilities-> Counts -> etc.
Supervisory information • What is it? • Do children use it? • It assumes a pretheoretic division of the input to the algorithm into raw data and something that takes a form similar to what the algorithm’s output is supposed to be like. This input that looks like output is supervision.
Supervision • Supervision comes in various flavors: • The crudest is giving the system the right answer through the training: this can be called association, or association/generalization. • Or we can give the right answer in just some cases.
Supervision • Or we can give the right answer only when the algorithm got it wrong. • The previous case is closely related to what is often the best supervision to have:telling the algorithm what the discrepancy is between what it produced for a given input and what we wanted it to produce.
Supervision • But is there any external supervision in language learning? Is there any external supervision in the case of dividing up the stream of speech into words?
“The learner’s active goal is to find the grammar that best predicts the evidence the learner is exposed to. More specifically, the learner maintains a stochastic, generative model of language that assigns a probability to every utterance u…Roughly speaking, learning consists of finding the grammar that maximizes the joint probability of all the utterances the learner has heard.”
deM notes that “patterns can arise from sources other than language”: eat your peas and clean your plate; *eat your plate and clean your peas. • It’s not obvious, though, that we don’t want to set up categories of words whose probabilities increase as objects of verbs of eating.
[t [ [ f [or] [ [ t [ he] ] [ [p [ur] [ [ [po] s ] e ] ] ] ...
Chapter 2 • Idiosyncratic use of the word “parameters”: any language-particular piece of linguistic knowledge.
Language acquisition... • There is relatively little evidence available to the learner, at least compared to the demands of existing computational models. • The learner chooses a grammar from among a high-dimensional parameters space, spanning many different types of parameters
Parameters are highly interdependent; • the relationship between parameters and observables is complicated and non-transparent; • the evidence available to the learner can be explained by many different parameter settings.
5 Reasons to concentrate efforts on theories with few additional assumptions • Any theory that can be tested on real data can be falsified more convincingly • Such theories act as existence proofs that certain parameters can be learned. • And thus proves that it is not necessary to make assumptions beyond those that are in the theory.
In the course of the implementation, incorrect and implicit assumptions can be identified. • Such testing serves a solution to engineering problems involving acquisition.
Conditions on theories of acquisition • Feasible (reasonable use of computational resources, demand no more from the environment than what is available) • complete (in terms of specification) • independent (the theory must not rely on the presence of other unattested or undemonstrated mechanisms)
Undesirable consequences of current views of modularity • One part may make unreasonable demands of its evidence: e.g., theories of morphology that expect segmented, noiseless phoneme sequences as input; theories of syntax that expect semantic information in treelike form • One part may assume implausible conditions of independence...
E.g., theories of phonological rule acquisition that assume that the underlying form is antecedently known.
Specification of the learning mechanism • “There are good reasons not to overly burden the learning mechanism. Complex learning algorithms are notoriously difficult to analyze and make categorical statements about. In most cases, the only means of evaluating them is to simulate their execution. Thinking in terms of general principles provides greater insight into...
the language learning process as a whole. It is for similar reasons that optimization researchers think in terms of an objective function, even though their algorithms may only consider its derivative when searching.”
Positive and negative examples and restricted lg classes • “It is not surprising that powerful classes of languages are not identifiable from positive examples alone. Any learning algorithm that guesses a language that is a superset of the target will never receive correcting evidence…but more fundamentally, for powerful classes of languages there are simply too many languages consistent with an set of data….
…other parts of language, such as the lexicon, are not so limited [as to be able to avoid ambiguity]. For this reason, it is difficult to construct linguistically plausible classes of grammars that are unambiguous with respect to natural input. …most sentences are logically decomposable into words, but there also exist idiomatic phrases that must be memorized. Given the two ….
possibilities, it seems that a child could account for any sentence as either following from parts or being a lengthy idiom. To rule out the second possibility while still permitting rote-memorized passages is difficult, and leads to baroque and unwieldy theories of language. Any natural class of grammars must allow for both possibilities, hence arbitrary ambiguity.”
Bayesian framework Probability of grammar G given the data U = prob of the data given the grammar * the probability of the grammar / probability of the data. (Leave off that denominator in the comparison). Probability of a grammar similar to its complexity.
Probabilistic grammar • Data is aba, abba, abbbba, abbbbba. Which is better: S-> aBa, B-> Bb, B->b • OR • S->a • S->b • S->SS • “clearly” the first. Why?
Grammar 1 • S -> aBa prob 1 • B-> Bb prob .5 • B-> b prob .5 • Grammar 2 • S -> SS .5 • S->a .25 • S->b .25 (other choices for p’s possible)
Grammar 1 S -> aBa prob 1; B-> Bb prob .5 B-> b prob .5. Prob (aba) = .5. Grammar 2 S -> SS .5, S->a .25, S->b .25 Prob (aba) is 1/128, with two derivations: S; SS (.5); a S; a S S; a b S; a b a; S: SS; [SS] S; [aS]S; ab S; aba.
“The discriminatory power of stochastic language models comes at a steep price.Unless probabilities are computed arbitrarily, grammars must include extra parameters…that define the exact probability of each utterance; the estimation of these extra parameters presumably complicates the learning problem. More fundamentally, stochastic language models burden the grammar with the task of specifying the probability of utterances, which is decidedly counterintuitive given that the source of utterances lies outside of
language altogether: the sentence please remove this egret from my esophagus is undoubtedly rare in English, but not because of linguistic parameters; the frequency that it occurs is principally determined by the circumstances of life. This is one of the reasons why many researchers have denied the appropriateness of stochastic language models. But the fact
that the grammar is not the principal cause of frequency variation does not mean that stochastic extensions to traditional grammars cannot be valuable aids to learning. In particular, because a stochastic grammar’s ability to assign high probability to evidence can be tied to the quality of the (non-stochastic) fit of the grammar to that evidence, statistical measures…can discriminate between …grammars.”
Digression on de Marcken’s work on syntax acquisition. Given evidence: Pron Verb p= .5 Pron Verb Noun p = .25 Pron Verb Det Noun = .25 Grammar 3: S->Pron VP (1) VP->Verb .5 Verb NP .5 NP -> Noun .5 -> Det Noun .5
Pron Verb p= .5 Pron Verb Noun p = .25 Pron Verb Det Noun = .25 Grammar 3: S->Pron VP (1) VP->Verb .5 Verb NP .5 NP -> Noun .5 -> Det Noun .5 Grammar 4: S -> Pron Verb .5 ->Pron NP .5 NP->VP Noun 1 VP ->Verb .5 ->Verb Det .5
DeMarcken hopes that probabilistic relations between a det and its Noun will be greater than the statistical relationship between a verb and the following determiner (of its object). The winning grammar will “assign a higher probability to English evidence than one that naively wastes proability on the indefinite-determiner-plural-noun possibility” if the NP-internal probs are...
Det Noun Prob • def singular .47 • indef singular .20 • definite plural .32 • indef plural .01
de Marcken’s lexicon C 00 ice 1111 A 010 then: I 011 iateicecream => E 100 011 010 1110 100 1111 00 R 101 101 100 010 110 M 110 T 1110
Prefixless encoding • Assume you have the list of permissible encodings (the codewords). You are looking at the coded message from its very beginning with no breaks between codewords. If knowing the codeword table allows you to unambiguously divide the message into codewords, then it is prefixless.
A 1 • b 0 • c 11 • d 10 • what is: 1110? Is it aaab, or c d, or aad, or what?
(A) • o n t h e m a • 00 01 100 101 110 1110 1111 • (B) • o n the m t h e a • 00 01 100 101 1100 1101 1110 1111 • (C) • o n t h e m a • 00 01 100 101 1100 1101 1110 • themanonthemoon • 1111
(A) • 100 101 110 1110 1111 01 00 01 100 101 110 1111 00 00 01 • 42 bits • (B)message: 100 101 1110 01 00 01 100 1101 00 00 01 • grammar: 1100 1101 1110 (t h e) • 40 bits • (C) message:1111 • grammar: 100 101 110 1110 1111 01 00 01 100 101 110 1111 00 00 01 • 48 bits
(A) • o n t h e m a • 00 01 100 101 110 1110 1111 • 100 101 110 1110 1111 01 00 01 100 101 110 1111 00 00 01