Download

1 / 1
10 likes | 124 Views
td. Gene Model. td. Status. Gene. td. Gene Model. tr. td. Nucleotides (coding/transcript). td. Status. Source Organism. Source Organism. td. Protein. td. Nucleotides (coding/transcript). ProtoNet. td. Amino Acids. tr. Accession Number. Accession Number. td. Protein.

E N D
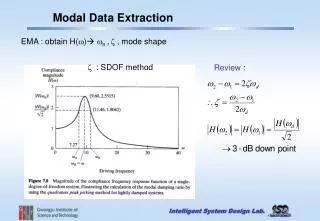
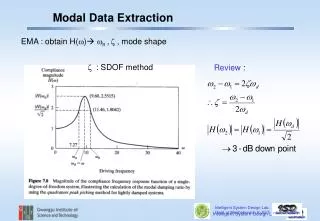
td Gene Model td Status Gene td Gene Model tr td Nucleotides (coding/transcript) td Status Source Organism Source Organism td Protein td Nucleotides (coding/transcript) ProtoNet td Amino Acids tr Accession Number Accession Number td Protein ProtoNet td td F18H3.5a 1, 2 Swissprot Location td td Amino Acids confirmed by cDNA(s) Protein Name Protein Name table table tr td 1029/3051 bp Length in Amino Acid ProtoNet td F47G6.1 1, 2 td WP:CE18608 Length in Amino Acid Length in Amino Acid td confirmed by cDNA(s) td 342 aa ProtoNet “3,?095”: td 1773/7391 bp tr Start End Molecular Weight in Da Molecular Weight in Da td td WP:CE26812 F18H3.5b 1, 2, 3 ProtoNet td td partially confirmed by cDNA(s) DTN1_CAEEL “37,?612,?680”; Source Location by Semantic Indexing ProtoNet tr td td 1221/1704 bp 590 aa “37,?610,?585”; td WP:CE28918 td 406 aa Introduction Ontology Evolution Source Page Understanding Conclusions Contact Information Map to Update values Specie Protein Name Toward Making Online Biological Data Machine Understandable Cui Tao Data Extraction Research Group Department of Computer Science, Brigham Young University, Provo, UT 84602 Data Extraction Research Group • Steps: • Transfer each HTML table to a DOM tree • Find sibling tree pairs • Compare and find matched nodes RELATIONSHIP-SET ENRICHMENT • PROBLEMS: • Huge evolving number of Bio-databases • e.g. molecular biology database collection • 2004: total 548, 162 more than 2003 • 2005: total 719, 171 more than 2004 • Different access capabilities • Syntactic heterogeneity • Semantics heterogeneity • Updated at anytime by independent authorities META-DATA ANNOTATION Source Old ontology Updated ontology Target OBJECT-SET ENRICHMENT Possible new object sets that could be added to the ontology • GOALS: • To help biologists cross search various resources • Examples: • Cross-linked information (Join queries) • “Find genes which are longer than 5kbp, whose products have at least two helices, and participate in glycolysis” – GenBank, PDB, KEGG • Collecting information from similar data sources (Union queries) • “Find genes newly annotated after Jan. 2003 in the fly and worm genomes” – FlyBase, WormBase DATA ANNOTATION Generate a structure pattern for all sibling tables Semantic Web Semantic annotation Query Implementation Status: • SOLUTION: • Source page understanding • Table Interpretation • Aligning with an ontology • Source location through semantic annotation • Metadata vs. instance data annotation • Use of annotation in query processing • Ontology evolution • Adjustments to ISA and Part-Of hierarchies • Addition of attributes Finished: sibling table comparison technique Working on: sample ontology object recognition ontology generation in the biological domain SAMPLE ONTOLOGY OBJECT RECOGNITION • Likely to have “imperfect” ontologies • Can enrich semi-automatically • Two possibilities: • Value enrichment • Object-set and relationship-set enrichment Delimitations: Key Concepts: sample ontology object, expected values Steps: Map the values with the sample ontology object set Map the labels with the ontology concepts Understand all pages from the same web site Ontology: will not cover everything in the domain Source page understanding: structured/semi-structured Value enrichment: only value lexicons Object set and relationship set enrichment: only ISA and Part-Of hierarchies and simple attribute additions VALUE ENRICHMENT SIBLING PAGE COMPARISON Key Concepts: sibling pages and sibling tables Main Idea: Compare two sibling tables: variable fields ~ values & fixed fields ~ labels Structure pattern for one pair of sibling tables General structure pattern for all sibling tables Data Extraction Research GroupDepartment of Computer Science Brigham Young UniversityProvo, UT 84602 Cui Tao, ctao@cs.byu.edu http://www.deg.byu.edu/ Two sample pages (partial information) A sample ontology object (partial information)