Pipeline Datapath
Pipeline Datapath. With some slides from: John Lazzaro and Dan Garcia. השעון. מחשב פנטיום במהירות של פירושו שהוא מבצע 8^10 *2 מחזורי שעון בשניה. כל מחזור שעון לוקח. 200 MHZ. Hertz=1/sec. 5*10^-9=5nanosecond. כמה לוקחת פקודה בימינו?. ALU. 2. Decode/ Register Read.


Pipeline Datapath
E N D
Presentation Transcript
Pipeline Datapath With some slides from: John Lazzaro and Dan Garcia
השעון מחשב פנטיום במהירות של פירושו שהוא מבצע 8^10 *2 מחזורי שעון בשניה. כל מחזור שעון לוקח 200MHZ Hertz=1/sec 5*10^-9=5nanosecond כמה לוקחת פקודה בימינו?
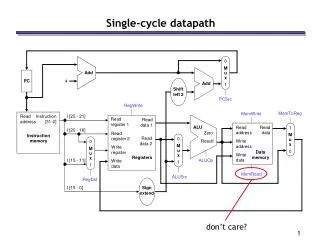
ALU 2. Decode/ Register Read 5. WriteBack 1. Instruction Fetch 4. Memory 3. Execute datapath מבנה ה- rd instruction memory registers PC rs Data memory rt +4 imm
A B C D Gotta Do Laundry • Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, fold, and put away • Washer takes 30 minutes • Dryer takes 30 minutes • “Folder” takes 30 minutes • “Stasher” takes 30 minutes to put clothes into drawers
2 AM 12 6 PM 1 8 7 11 10 9 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 30 T a s k O r d e r Time A B C D Sequential Laundry • Sequential laundry takes 8 hours for 4 loads
2 AM 12 6 PM 1 8 7 11 10 9 Time 30 30 30 30 30 30 30 T a s k O r d e r A B C D Pipelined Laundry • Pipelined laundry takes 3.5 hours for 4 loads!
General Definitions • Latency: time to completely execute a certain task • for example, time to read a sector from disk is disk access time or disk latency • Throughput: amount of work that can be done over a period of time
6 PM 7 8 9 Time T a s k O r d e r 30 30 30 30 30 30 30 A B C D Pipelining Lessons (1/2) • Pipelining doesn’t help latencyof single task, it helps throughput of entire workload • Multiple tasks operating simultaneously using different resources • Potential speedup = Number pipe stages • Time to “fill” pipeline and time to “drain” it reduces speedup:2.3X v. 4X in this example
30 30 30 30 30 30 30 A B C D Pipelining Lessons (2/2) 6 PM 7 8 9 Time T a s k O r d e r • Suppose new Washer takes 20 minutes, new Stasher takes 20 minutes. How much faster is pipeline? • Pipeline rate limited by slowestpipeline stage • Unbalanced lengths of pipe stages also reduces speedup
Car body shell The clock Merge station Car chassis Bolting station Inspiration: Automobile assembly line Assembly line moves on a steady clock. Each station does the same task on each car.
Inspiration: Automobile assembly line Simpler station tasks → more cars per hour. Simple tasks take less time, clock is faster.
Inspiration: Automobile assembly line Line speed limited by slowest task. Most efficient if all tasks take same time to do
Inspiration: Automobile assembly line Simpler tasks, complex car → long line! These lines go 24 x 7, and rarely shut down. Why?
Lessons from car assembly lines Faster line movement yields more cars per hour off the line. Faster line movement requires morestages, each doing simpler tasks. To maximize efficiency, all stages should take same amount of time (if not, workers in fast stages are idle) “Filling”, “flushing”, and “stalling” assembly line are all bad news.
ALU 2. Decode/ Register Read 5. WriteBack 1. Instruction Fetch 4. Memory 3. Execute datapath מבנה ה- rd instruction memory registers PC rs Data memory rt +4 imm
Stage #3 Stage #4 Stage #2 Stage #5 IR IR IR IR Controls hardware in stage 2 Controls hardware in stage 3 Controls hardware in stage 4 Controls hardware in stage 5 Key Analogy: The instruction is the car Pipeline Stage #1 Instruction Fetch “Data-stationary control”
Good for visualizing pipeline fills. Time: t1 t2 t3 t4 t5 t6 t7 t8 Sample Program Inst I1: ADD R4,R3,R2 I1: ID EX MEM WB I2: AND R6,R5,R4 I2: IF ID EX MEM WB I3: SUB R1,R9,R8 I3: IF ID EX MEM WB I4: XOR R3,R2,R1 I4: IF ID EX MEM WB I5: OR R7,R6,R5 I5: IF ID EX MEM Pipeline is “full” I6: IF ID EX Representation #1: Timeline IF (Fetch) ID (Decode) EX (ALU) MEM WB IR IR IR IR IF
Time: t1 t2 t3 t4 t5 t6 t7 t8 Stage IF: I2 I3 I4 I5 I6 I7 I8 ID: I1 I2 I3 I4 I5 I6 I7 EX: I1 I2 I3 I4 I5 I6 MEM: I1 I2 I3 I4 I5 WB: I1 I2 I3 I4 Pipeline is “full” Representation #2: Resource Usage IF (Fetch) ID (Decode) EX (ALU) MEM WB IR IR IR IR Good for visualizing pipeline stalls. Sample Program I1: I1 ADD R4,R3,R2 I2: AND R6,R5,R4 I3: SUB R1,R9,R8 I4: XOR R3,R2,R1 I5: OR R7,R6,R5
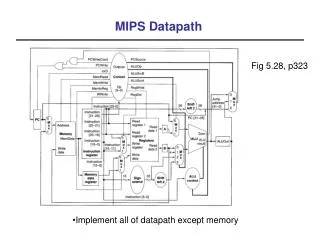
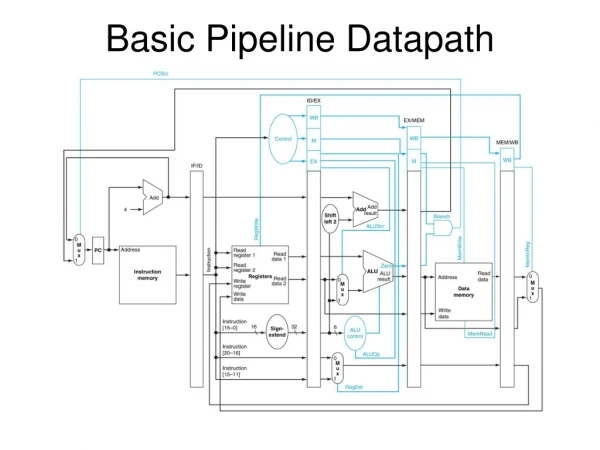
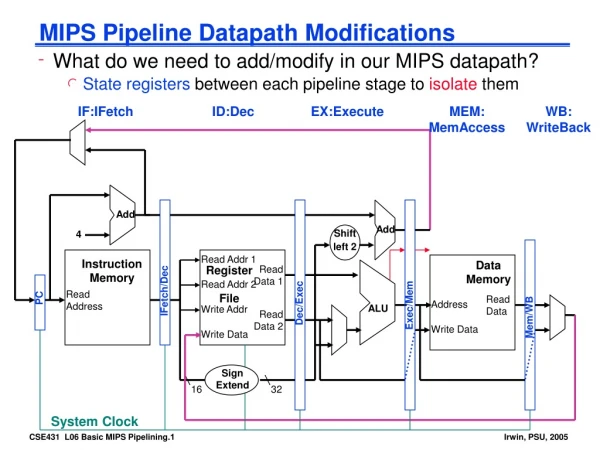
IFtch Dcd Exec Mem WB ALU 2. Decode/ Register Read 5. WriteBack 1. Instruction Fetch 4. Memory 3. Execute I$ D$ Reg Reg ALU Review: Datapath for MIPS rd instruction memory PC registers rs Data memory rt • Use datapath figure to represent pipeline +4 imm Stage 2 Stage 3 Stage 4 Stage 5 Stage 1
Time (clock cycles) I n s t r. O r d e r I$ Reg ALU Load D$ Reg I$ Add ALU D$ Reg Reg I$ Reg ALU Store D$ Reg D$ Reg Sub ALU I$ Reg I$ D$ Reg Or ALU Reg Graphical Pipeline Representation (In Reg, right half highlight read, left half write)
Example • Suppose 2 ns for memory access, 2 ns for ALU operation, and 1 ns for register file read or write • Nonpipelined Execution: • lw : IF + Read Reg + ALU + Memory + Write Reg = 2 + 1 + 2 + 2 + 1 = 8 ns • add: IF + Read Reg + ALU + Write Reg = 2 + 1 + 2 + 1 = 6 ns • Pipelined Execution: • Max(IF,Read Reg,ALU,Memory,Write Reg) = 2 ns
l w I n s t r u c t i o n f e t c h 0 M u x 1 I F / I D I D / E X E X / M E M M E M / W B A d d A d d 4 A d d r e s u l t S h i f t l e f t 2 R e a d n o r e g i s t e r 1 i A d d r e s s P C t R e a d c u d a t a 1 r t R e a d s Z e r o r e g i s t e r 2 n I I n s t r u c t i o n R e g i s t e r s A L U R e a d A L U m e m o r y 0 R e a d W r i t e A d a t a 2 r e s u l t 1 d a t a r e g i s t e r M M u u W r i t e x x d a t a 1 0 W r i t e d a t a 1 6 3 2 S i g n e x t e n d IF/ID
l w 0 I n s t r u c t i o n d e c o d e M u x 1 I F / I D I D / E X E X / M E M M E M / W B A d d A d d 4 A d d r e s u l t S h i f t l e f t 2 n o R e a d i t c r e g i s t e r 1 A d d r e s s P C u R e a d r t s d a t a 1 R e a d n I Z e r o r e g i s t e r 2 I n s t r u c t i o n R e g i s t e r s A L U R e a d A L U m e m o r y 0 R e a d W r i t e A d d r e s s d a t a 2 r e s u l t 1 d a t a r e g i s t e r M M u D a t a u W r i t e x m e m o r y x d a t a 1 0 W r i t e d a t a 3 2 1 6 S i g n e x t e n d ID/EX
l w 0 M e m o r y M u x 1 I F / I D I D / E X E X / M E M M E M / W B A d d A d d 4 A d d r e s u l t S h i f t l e f t 2 n o R e a d i t c r e g i s t e r 1 A d d r e s s P C u R e a d r t d a t a 1 s R e a d n I Z e r o r e g i s t e r 2 I n s t r u c t i o n R e g i s t e r s A L U R e a d A L U m e m o r y 0 R e a d W r i t e A d d r e s s d a t a 2 r e s u l t 1 d a t a r e g i s t e r M D a t a M u u m e m o r y W r i t e x x d a t a 1 0 W r i t e d a t a 1 6 3 2 S i g n e x t e n d MEM/WB
l w 0 M u W r i t e b a c k x 1 I F / I D I D / E X E X / M E M M E M / W B A d d A d d 4 A d d r e s u l t S h i f t l e f t 2 n o R e a d i t c r e g i s t e r 1 A d d r e s s P C u R e a d r t d a t a 1 s R e a d n I Z e r o r e g i s t e r 2 I n s t r u c t i o n R e g i s t e r s A L U R e a d A L U m e m o r y 0 R e a d W r i t e A d d r e s s d a t a 2 r e s u l t 1 d a t a r e g i s t e r M D a t a M u m e m o r y u W r i t e x x d a t a 1 0 W r i t e d a t a 1 6 3 2 S i g n e x t e n d
A correction !!! תיקון Keep the right Rd all the way!
דוגמא A demonstration of a sequence of instructions: Lw $10,20($1) Sub $11,$2,$3 And $12,$4,$5 Or $13,$6,$7 Add $14,$8,$9
I F : a f t e r I D : a f t e r < 3 > E X : a f t e r < 2 > M E M : a f t e r < 1 > W B : a d d $ 1 4 , . . . I F / I D I D / E X E X / M E M M E M / W B W B M W B E X M A d d 4 A d d e r e s u l t t i r W B r a n c h S h i f t g e R l e f t 2 A L U S r c g n e o i R t c o A d d r e s s t u r m t s e n M I Z e r o I n s t r u c t i o n A L U m e m o r y 0 r e s u l t 1 A L U c o n t r o l 0 A L U O p 1 R e g D s t < 4 > 0 M 0 0 0 0 u x 1 0 0 0 0 0 0 0 0 C o n t r o l 0 0 1 0 0 0 0 0 0 0 W B 0 0 0 A d d e t i r W m e R e a d M r e g i s t e r 1 P C R e a d d a t a 1 R e a d r e g i s t e r 2 R e g i s t e r s A L U R e a d 1 4 R e a d W r i t e d a t a 2 A d d r e s s 1 d a t a r e g i s t e r M M D a t a u u m e m o r y W r i t e x x d a t a 0 W r i t e d a t a I n s t r u c t i o n [ 1 5 – 0 ] S i g n M e m R e a d e x t e n d I n s t r u c t i o n [ 2 0 – 1 6 ] M 1 4 u I n s t r u c t i o n x [ 1 5 – 1 1 ] C l o c k 9
Problems for Computers • Limits to pipelining:Hazards prevent next instruction from executing during its designated clock cycle • Structural hazards: HW cannot support this combination of instructions (single person to fold and put clothes away) • Control hazards: Pipelining of branches & other instructions stall the pipeline until the hazard “bubbles” in the pipeline • Data hazards: Instruction depends on result of prior instruction still in the pipeline
An example for data hazards: sub $2, $1, $3 and $12, $2, $5 or $13, $6, $2 add $14, $2, $2 sw $15, 100($2)
An example for data hazards: sub $2, $1, $3 and $12, $2, $5 or $13, $6, $2 add $14, $2, $2 sw $15, 100($2) An example for data hazards:Register $2 is updated only at the WB phase, i.e., the 5th clock cycle (actually at the end of the 5th clock cycle). However, we try to use it at the 3rd clock cycle when we read $2 at the decode phase of the and instruction
Solving data hazards by adding nops sub $2, $1, $3 nop nop nop and $12, $2, $5 or $13, $6, $2 add $14, $2, $2 sw $15, 100($2)
T i m e ( i n c l o c k c y c l e s ) C C 1 C C 2 C C 3 C C 4 C C 5 C C 6 C C 7 C C 8 C C 9 C C 10 C C 11 C C 12 V a l u e o f r e g i s t e r $ 2 : 1 0 1 0 1 0 1 0 1 0 / – 2 0 – 2 0 – 2 0 – 2 0 – 2 0 – 2 0 – 2 0 – 2 0 s u b $ 2 , $ 1 , $ R R R g g g e e e I I I M M M R R R e e e g g g D D D M M M P r o g r a m e x e c u t i o n o r d e r ( i n i n s t r u c t i o n s ) R e g I M R e g D M I M D M R e g R e g I M D M R e g R e g I M D M R e g R e g I M D M R e g R e g Solving data hazards by adding nops 3 nop nop nop 5 a n d $ 1 2 , $ 2 , $ o r $ 1 3 , $ 6 , $ 2 2 a d d $ 1 4 , $ 2 , $ ) s w $ 1 5 , 1 0 0 ( $ 2
The internal structure of the Register File Rd reg 1 (= Rs) 32 5 32 32 32 32 Read data 1 write data 32 32 32 Rd reg 2 (= Rt) 5 32 32 32 Read data 2 32 32 Wr reg (= Rd) 5 E RegWrite קוראים משתי היציאות בוזמנית ערכים של שני רגיסטרים שונים כותבים לאחד הרגיסטרים האחרים (בעליית השעון הבאה)
T i m e ( i n c l o c k c y c l e s ) C C 1 C C 2 C C 3 C C 4 C C 5 C C 6 C C 7 C C 8 C C 9 C C 10 C C 11 C C 12 V a l u e o f r e g i s t e r $ 2 : 1 0 1 0 1 0 1 0 1 0 / – 2 0 – 2 0 – 2 0 – 2 0 – 2 0 – 2 0 – 2 0 – 2 0 s u b $ 2 , $ 1 , $ R R g g e e I I M M R R e e g g D D M M P r o g r a m e x e c u t i o n o r d e r ( i n i n s t r u c t i o n s ) R e g I M R e g D M I M D M R e g R e g I M D M R e g R e g I M D M R e g R e g I M D M R e R e g We could earn 1 ck cycle if GPR is “transparent” 3 nop nop 5 a n d $ 1 2 , $ 2 , $ o r $ 1 3 , $ 6 , $ 2 We could earn 1 ck cycle if GPR is “transparent”, i.e, we could see the write data to the GPR at the GPR outputs (if the write address equals the read address), i.e., during Ck #5. 2 a d d $ 1 4 , $ 2 , $ g ) s w $ 1 5 , 1 0 0 ( $ 2
The internal structure of the modified Register File. We ‘bypass” the input data (the write data) to the read data1 output whenever Rs=Rd/Rt (i.e., whenever read reg1=write reg but not zero). We “bypass” the input data (the write data) to the read data2 output whenever Rt=Rd/Rt (i.e., whenever read reg2=write reg, but not zero). Wr reg 5 Rd reg 1 (= Rs) 5 write data 32 32 Read data 1 32 0 32 32 32 32 32 write data 32 32 Wr reg 32 5 Rd reg 2 (= Rt) write data 5 32 Read data 2 32 0 32 32 32 32 32 32 Wr reg (= Rd) 5 E RegWrite קוראים משתי היציאות בוזמנית ערכים של שני רגיסטרים שונים כותבים לאחד הרגיסטרים האחרים (בעליית השעון הבאה)
After doing that change we only need 2 nops sub $2, $1, $3 nop nop and $12, $2, $5 or $13, $6, $2 add $14, $2, $2 sw $15, 100($2) After the change the WB of an early instruction can happen at the same time with the read reg (decode) phase of a newer instruction (3 with two other instructions in between). In case we have a data hazard, we need to add only two nop instructions.Unfortunately, this happens too often. We need a better solution!