Download

1 / 20
200 likes | 330 Views
COMP/EECE 7/8740 Neural Networks. Structural Learning in Neural Networks Contents 1. Motivation of structural learning 2. Methodology 3. Applications March 4, 2003. Structural Learning in Neural Networks. Why structural learning?

E N D
COMP/EECE 7/8740 Neural Networks Structural Learning in Neural Networks Contents 1. Motivation of structural learning 2. Methodology 3. Applications March 4, 2003
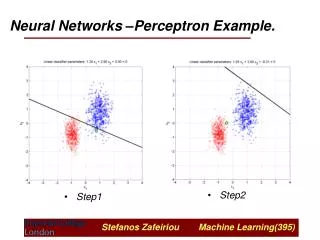
Structural Learning in Neural Networks • Why structural learning? • Standard backpropagation learning techniques • good approximation with arbitrary accuracy • no preliminary knowledge is required • easy and widely applicable • BUT • no explanation of the obtained results • problems with local minima/structure selection • overtraining can occur
Structural Learning of Neural Networks(cont’d) • Optimum structure is selected • nodes, connections • Knowledge is generated during training • as rules (crisp or fuzzy) • Interpretation of the obtained results • making the ‘black-box’ transparent • Improved performance • better generalization, robustness to noise • BUT: increased complexity of learning
Implementing Structural Learning • Regularisation/penalty concept • cost function • J = SSE + lambda * COMPLEXITY • Possible approaches to regularisation • entropy • Optimum Brain Damage OBD (LeCun’90) • forgetting (Ishikawa, ‘90) • lateral inhibition (Yasui, ‘92)
Learning with Forgetting in Neural Networks • Cost function • J = SSE + lambda * S |w_ij| • Learning rule • Dw_ij = Dw’_ij + lambda*sign(w_ij) • Simple to implement • very good performance as compared to other regularisation methods • (Ishikawa, 1996, Kozma et al. 1996)
Evolution of Weights • 3 types of weights/nodes after structural learning: • Survivors: small fraction of all • Decayed: 90%+ • Strugglers: on the interface • Separation of groups • Survivors<-> decayed by orders of magnitudes (100-times or more) • Discrete / integer representation is feasible • When environment changes • 3-level structure diminishing • Rearrangement among levels
Dynamics of Dimensions in NNs • Example of structural evolution: • IRIS Cluster Deformation III I II* II
Dimension Expansion Dynamics • Intermediate steps of adaptation
Application in speech recognition • Speech (phoneme) data analysis: wave form; frequency analysis; formants; speech transformation: FFT; mel- scale; • Phoneme recognition from time-series speech data • Initialization of the phoneme classifiers (units) • Training the phoneme units • Extracting information from phoneme units • Adaptation to new speakers and accents
NN for speech and language processing:ASR systems Main blocks in a speech recognition system
Speech waveform • The waveform of “Fish”
Frequency analysis • Repeating sound can be described as a series of sine waves • Small segments of sound may be approximated the same way • Fourier analysis • DFT • FFT
Example of DFT: Spectrogram Time Frequency • Color represents amplitude • Intense => higher amplitude
Example of Structural learning in NNsspeech/phoneme recognition • Skeleton structure of phoneme /e/ Yes_/e/ Not_/e/ F1(t) F2(t) F2(t-1) F2(t-2)
/au/ /^/ /r/ /n/ /h/ /d/ /p/ Difficulties in phoneme and word recognition (recognition of the word “up”)
Example: prediction of chaotic time series • Mackey-Glass time series • control parameter: internal time constant
Mackey-Glass data for various time constants • tau=14 (limit cycle) 17 • 30 100
Structural learning in fuzzy-neural network • Original (fully connected) • Structured Input - time series points 1 to 200
Representation of the dynamics in the structure • major cycles identified • 3T 2T T
ConclusionRule Extraction by Structural Learning • Knowledge is generated during training • In the form of crisp or fuzzy rules • The NN’s skeleton structure represents the rules • Additional advantages: • Optimum structure is selected • Improved performance (better generalization and robustness to noise)