Download
1 / 21
220 likes | 238 Views
Explore the characteristics of speech, spectrum analysis, and acoustic features for audio processing. Learn about volume, pitch, timbre, energy, zero crossing rate, and more. Discover the basics of speech production and phonetics. MATLAB examples included.

E N D
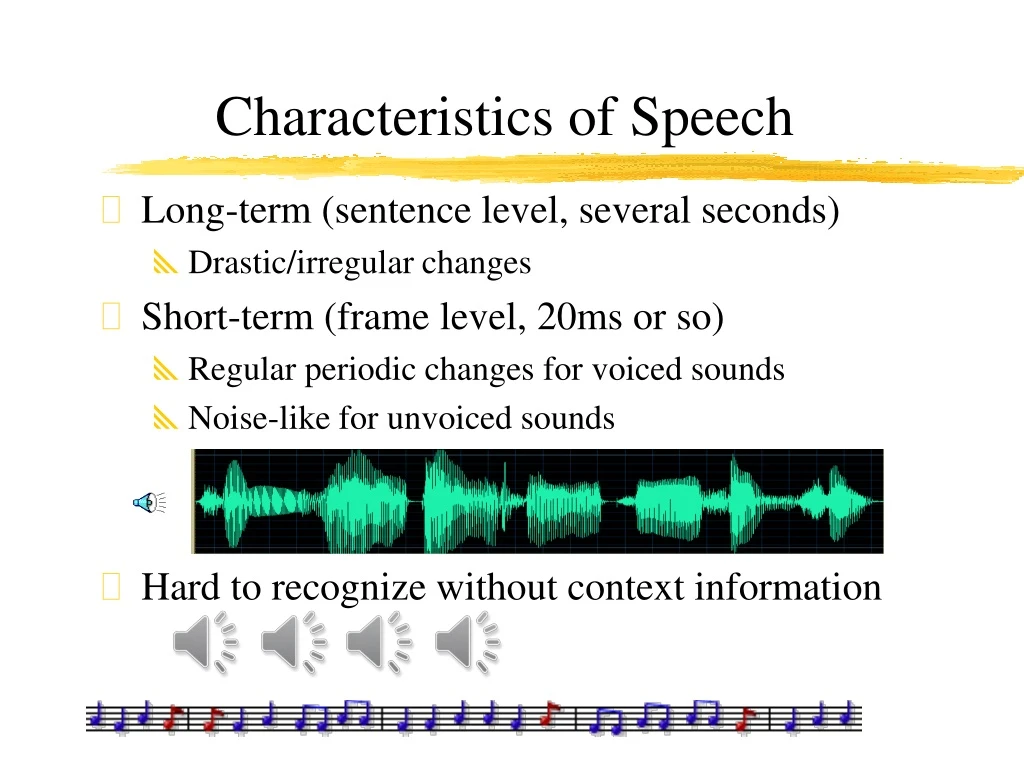
Characteristics of Speech • Long-term (sentence level, several seconds) • Drastic/irregular changes • Short-term (frame level, 20ms or so) • Regular periodic changes for voiced sounds • Noise-like for unvoiced sounds • Hard to recognize without context information
Spectrum in Frequency-Domain • Three basic characteristics in a spectrum: • Timbre: Spectrum after smoothing • Pitch: Distance between harmonics • Intensity: Magnitude of spectrum Second formant F2 Pitch freq First formant F1 Intensity
Timber Demo: Real-time Spectrogram • Simulink model for real-time display of spectrogram • dspstfft_audio (Before MATLAB R2011a) • dspstfft_audioInput (R2012a or later) Spectrum: Spectrogram:
Audio Feature Extraction & Recog. • Frame blocking • Frame duration of 20 ms • Feature extraction • Volume, pitch, MFCC, LPC, etc • Endpoint detection • Based on volume & ZCR • Recognition • DTW, HMM
Example: Audio Feature Extraction Overlap Zoom in Frame 256 points/frame 84 points overlap 11025/(256-84)=64 feature vectors per second
Three Basic Acoustic Features • Three basic speech features • Volume/Energy/Intensity(音量、能量、強度):Vibration Amplitude • Pitch(音高):Fundamental frequency (which is equal to the reciprocal of the fundamental period) • Timbre(音色):The waveform within a fundamental period • These features are perceived subjectively by humans. However, we can use some mathematics to “emulate” human and capture these features.
Acoustic Feature: Energy • Energy is the square sum of a frame, also known as intensity or volume. • Characteristics: • Usually noise and fricative have low energy. • Energy is influence a lot by microphone setup. • If we take log of square sum, and times 10, we have energy in terms of Decibel(分貝) • Energy is commonly used in endpoint detection. • In embedded system implementation, volume can be computed as the abs. sum of a frame in order to reduce computation.
Acoustic Feature: Zero Crossing Rate • Zero crossing rate (ZCR) • The number of zero crossing in a frame. • Characteristics: • Noise and unvoiced sound have high ZCR. • ZCR is commonly used in endpoint detection, especially in detection the start and end of unvoiced sound. • To distinguish noise/silence from unvoiced sound, usually we add a bias before computing ZCR.
Pitch • Computation • Pitch freq. is the reciprocal of fundamental period. • Pitch in terms of semitone:
一般聲音的產生與接收 • 基本流程 • 發音體的震動 • 空氣的波動 • 耳膜的振動 • 內耳神經的接收 • 大腦的辨識 • 發聲機制 • 敲擊所引發的自然震動頻率(例:音叉) • 空氣摩擦所引發的共振頻率(例:笛子)
Speech Production Glottal Pulses Vocal Tract Speech Signal = + + = (a) Source Spectrum (b) Filter Function (c) Output Energy Spectrum
× Speech Production Modeling Pitch Period phonation whispering frication compression vibration Vocal Tract Parameters Impulse Train Generator Time-varying digital filter u(n) s(n) G Noise Generator
Parametric Representation u(n) × s(n) A(z) Model G = gain of excitation u(n) = excitation source (quasi-periodic pulse train or random noise) G Z-Transform Write in A(z)
The Speech Model : A Summary • Voiced/unvoiced classification, • Pitch period for voiced sounds, • The gain parameter, and • The coefficients of the digital filters, {ak}.
Cochlea:耳蝸 Phoneme:音素、音位 Phonics:聲學;聲音基礎教學法(以聲音為基礎進而教拼字的教學法) Phonetics:語音學 Phonology:音系學、語音體系 Prosody:韻律學;作詩法 Syllable:音節 Tone:音調 Alveolar:齒槽音 Silence:靜音 Noise:雜訊 Glottis:聲門 larynx:喉頭 Pharynx:咽頭 Pharyngeal:咽部的,喉音的 Velum:軟顎 Vocal chords:聲帶 Esophagus:食管 Diaphragm:橫隔膜 Trachea:氣管 名詞對照
Hints for Exercises • How to generate a sine wave signal: • Math formula: • MATLAB code: duration=3; f=440; fs=16000; time=(0:duration*fs-1)/fs; y=0.8*sin(2*pi*f*t); plot(time, y); sound(y, fs);