Download

1 / 18
190 likes | 419 Views
Molecular Basis of Heredity . Warm-Up / EOC Prep. 1. When nuclear membranes form and the cell separates, _____ has occurred. A. chromatid B. telophase C. prophase D. metaphase 2. During the interphase before both mitosis and meiosis occur, ______. A. one division occurs

E N D
Warm-Up / EOC Prep 1. When nuclear membranes form and the cell separates, _____ has occurred. A. chromatid B. telophase C. prophase D. metaphase 2. During the interphase before both mitosis and meiosis occur, ______. A. one division occurs B. 4 daughter cells are produced C. chromosomes are duplicated D. cells produced are identical to the parent cell
3/24/2010 DNA Structure and Replication
DNA • DNA is the called the “genetic blueprint” because it contains the instructions needed for your cells to carry out all of the functions to sustain life. DNA stands for deoxyribonucleic acid. • Information encoded in your cells’ DNA is organized into units called genes. A gene is a segment of DNA that codes for a protein or RNA molecule. By the 1950s, scientists knew that genes were made of DNA, but they didn’t know what this molecule looked like.
DNA • James Watson and Francis Crick, two researchers at Cambridge University, discovered the structure of DNA, which clarified how DNA served as the genetic material. • The DNA molecule is a doublehelix – two strands twisted around each other like a winding staircase or a twisted ladder.
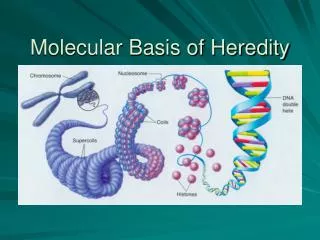
DNA • Each strand is made of linked nucleotides. Remember—nucleotides are the subunits that make up nucleic acids like DNA and RNA. • Each nucleotide is made of three parts: a phosphate group, a five-carbon sugar called deoxyribose, and a nitrogen-containing base. The sugar and the phosphate group are the same for each nucleotide in a DNA molecule, but the nitrogen base may be one of four kinds.
DNA AdenineGuanineCytosine Thymine • The sugar-phosphate backbones are like the side rails of a ladder, while the paired nitrogen bases are like the rungs (steps) of the ladder.
Discovering DNA’s Structure • In 1949, Erwin Chargraff observed that for each organism’s DNA that he studied, the amount of adenine always equaled the amount of thymine (A = T) and the amount of guanine always equaled the amount of cytosine (G = C).
Discovering DNA’s Structure • In 1952, Maurice Wilkins and Rosalind Franklin developed high-quality X-ray photographs of DNA and showed that it must be a tightly coiled helix composed of chains of nucleotides. • In 1953, Watson and Crick put together Chargraff’s findings and stolen X-ray data from Franklin and Wilson to come up with the three dimensional double helix model.
Base Pairing in DNA • Adenine always pairs with Thymine and Guanine always pairs with Cytosine • (A – T) (G – C) • These base-pairing rules are supported by Chargraff’s observations.
Base Pairing in DNA • The nucleotides are paired together with Hydrogen bonds, resulting in two strands that contain complementary base pairs. This means, the sequence of nitrogen bases on one strand determines the sequence of nitrogen bases on the other strand.
Base Pairing in DNA • In other words, one strand acts as a template for figuring out the complementary strand. Ex: T C G A A C T A G C T T G A
DNA Replication • The process of making a copy of the DNA is called DNA replication. Remember, this occurs during the S phase of the cell cycle, before the cell divides. • Step 1: The DNA double helix unwinds using an enzyme called DNA helicase. Proteins hold each strand apart from each other, forming a Y shape called a replication fork.
DNA Replication • Step 2: At the replication fork, enzymes called DNA polymerase move along each of the DNA strands, adding complementary bases to the exposed nitrogen bases according to base-pairing rules.
DNA Replication • Step 3: DNA polymerases add nucleotides to a growing double helix until all the DNA has been copied and the polymerases are signaled to detach. Result: two new DNA molecules, each composed of one original strand and one copied strand. The nucleotide sequences of the two DNA molecules are identical. • This process is called semi-conservative because each new DNA helix is made of half original DNA molecule and half new DNA molecule.
DNA Replication • During DNA replication, errors can occur in which the wrong nucleotide is added to a new strand. Changes to the DNA are called mutations. • DNA polymerases proofread the new strand as they build it to avoid these errors. This results in an error rate of only one error per 1 billion nucleotides.