Download

1 / 27
270 likes | 419 Views
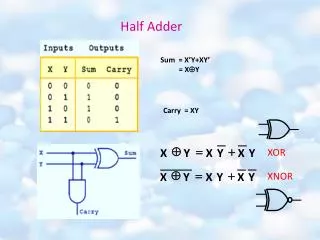
Half-Price Architecture. Ilhyun Kim Mikko H. Lipasti PHARM Team University of Wisconsin — Madison. http://www.ece.wisc.edu/~pharm. map table reads dependence checks. two operand wakeups. two RF read port accesses. Fetch. Decode. Rename. Queue. Sched. Disp. Disp. RF. RF. Exe.

E N D
Half-Price Architecture Ilhyun Kim Mikko H. Lipasti PHARM Team University of Wisconsin—Madison http://www.ece.wisc.edu/~pharm
map table reads dependence checks two operand wakeups two RF read port accesses Fetch Decode Rename Queue Sched Disp Disp RF RF Exe Retire Commit ready state checks bypass to FU’s two input ports Motivations • Processors are designed to handle 0, 1 and 2-source instructions at equal cost • Satisfy the worst-case requirements of instructions • No resource arbitrations / pipeline stalls in handling source operands • Simple controls over instruction and data stream • Handling source operands requires 2x machine bandwidth • e.g. 2 read ports / 1 write port per instruction • Heavily multi-ported structures in many pipeline stages Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-302
Making the common case faster • 2x HW configuration assumes 2 source operands are common • 18~36% of instructions have 2 source operands • But, structures for 2 source operands are not fully utilized • Scheduler • 4%~16% of instructions need two wakeups • Less than 3% of instructions handle 2 wakeups in the same clock cycle • Register File • 0.64 read port per instruction • Less than 4% of instructions need two register read ports • Handling 2 source operands may NOT be the common case Why notbuild a pipeline optimized for 1-source instructions? Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-303
Half-price Architecture • Restrict the processor’s capability to handle 2 source operands • 0- or 1-source instructions are processed without any restriction • 2-source instructions may execute more slowly • But, they are not the common case Reduce hardware complexity incurred by 2 source operands • ½ technique in scheduler: Sequential wakeup • ½ technique in RF: Sequential register access HW design point to match the worst-case requirements Opcode Rdst Rsrc 1 Rsrc 2 Opcode Rdst Rsrc 1 Half-price architecture design point Needs more hardware Opcode Rdst / Rsrc Opcode Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-304
2-source-format instructions • 18~36% of dynamic instructions have 2-source format (excluding stores) 2-src-format insts Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-305
Target identification:2-source instructions • 6~23% of instructions are 2-source instructions • 2 unique source operands with dependences • Dynamic behaviors of 2-source instructions will expose greater opportunities 2-src-format insts 2-src insts Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-306
Outline • Motivations • Half-price architecture • Reducing scheduler complexity • Sequential wakeup • Reducing register file complexity • Conclusions & Future work Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-307
readyL tagL tagR readyR tag W tag 1 … OR = = OR = = … … Scheduler complexity • Overdesign in wakeup logic • Tag comparators for two source operands • Tag broadcast is expensive • Delay is a function of # tag comparators and bus length • Speeding up the scheduler • Clustered scheduler (Palacharla et al.) • Making a small window look bigger (Michaud et al.) • Hierarchical scheduler (Lebeck et al., Hrishikesh et al.) • Reducing wakeup bus load capacitance • Tag elimination & last-tag speculation (Ernst & Austin) • Half-price technique: sequential wakeup Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-308
Last-tag speculation (Ernst & Austin, ISCA02) • Only the last-arriving operand initiates instruction issue • Remove tag comparison logic for the early-arriving operand • Fewer tag comparators reduced load on the bus + compact wakeup logic scheduling logic cycle time improvement • A scoreboard checks correctness of scheduling • May hurt performance due to its speculative nature • Implementation issue w/ broadcast-based selective recovery Our technique exploits last-arriving operands non-speculatively, achieving similar benefits Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-309
8-wide 4-wide 2-pending-source instructions • Many operands are already ready at insert time • 4~16% of instructions have 2-pending-source operands, requiring two wakeup signals before being issued 2-src insts 2-pending- src insts Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3010
4-wide 8-wide Slack between two wakeups • Many 2-pending-source instructions have wakeup slack • Less than 3% of instructions have 0-slack wakeups Exploit wakeup slack to prioritize operand wakeups 2-pending- src insts simultaneous wakeup (0 slack) Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3011
fast wakeup bus timing slow wakeup bus timing latch select delay clock t broadcast t-1 broadcast t latch select delay clock t+1 broadcast t broadcast t+1 latch ½ technique - Sequential wakeup • Sequentially wake up½ operands during wakeup slack • Decouples half of tag comparators reduced load on the bus • Flexible routing in slow wakeup bus compact fast wakeup logic • No recovery, lower misprediction penalty (1-cycle issue delay) • Instructions are issued non-speculatively in terms of operand readiness • Simultaneous (0-slack) wakeups always incur penalty • But, they are less than 3% of instructions tag W tag 1 … … OR = OR = = = readyL tagL readyR tagR … … put the tag predicted to be last-arriving latch Fast wakeup bus Slow wakeup bus (1 clk behind) Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3012
Machine models • Simplescalar-Alpha-based, 12-stage, 4/8-wide OoO + Speculative scheduling • Alpha-style squashingscheduling recovery • invalidates all issued instructions (dependent / independent) behind the miss • 4-wide: 64 RUUs, 32 LSQs, 2 memory ports • 8-wide: 128 RUUs, 64 LSQs, 4 memory ports • 64K IL1 (2), 64K DL1 (2), 512K unified L2 (8) • Combined (bimodal + gShare) branch prediction, fetch until the first taken branch • Sequential wakeup • Last-arriving operand predictor: 1k-entry, PC-direct-mapped, 2-bit bimodal • Last-tag speculation • Same predictor • Scoreboard located next to the scheduler Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3013
Sequential wakeup performance • Sequential wakeup slowdown is slight: avg 0.4 / 0.6%, worst 2.1% • Less than 4% of instructions incur penalty • Sequential wakeup is relatively insensitive to predictor accuracy Sequential wakeup can reduce wakeup logic delay with a minimal performance impact 4-wide 8-wide Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3014
Outline • Motivations • Half-price architecture • Reducing scheduler complexity • Reducing register file complexity • Sequential register file access • Conclusions & Future work Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3015
Register file complexity • Overdesign in register file • 2x read ports for two source operands • Superscalar processors need RF to be heavily multiported • Area increases quadratically, latency increases linearly • Two read ports are not fully utilized • 0- / 1-source instructions do not require two read ports • Many instructions frequently get values off the bypass path • 0.64 read ports / instruction (Balasubramonian et. al, ISCA01) • Speeding up the RF • Reducing the number of register entries • Hierarchical register file (Cruz, Borch, Balasubramonian, …..) • Reducing the number of ports • Fewer RF ports + crossbar (Balasubramonian et al, Park et al…) • Half-price technique: Sequential RF Access Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3016
Two RF read port accesses • Less than 4% of instructions need 2 read port accesses • Many 2-source instructions read at least one value off bypass path 4-wide 8-wide 2-src insts require 2 read ports Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3017
½ technique – Sequential RF access • Remove ½ register read ports • Only a single read port per issue slot • 0 or 1-source instructions are processed without any restriction • Sequentially access a single port twice for 2 values if needed(the execution latency increases by 1 clock cycle) • However, speculative scheduling does not allow variable-latency operations (Implementing optimizations at decode time, ISCA02) • Load latency misprediction scheduling recovery • Variable RF latency scheduling recovery, too Sequential RF access should be reflected in scheduling • How to detect if source values will be read off the bypass path? • How to schedule dependent instructions accordingly? Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3018
Scheduling Loop single-read ported Reg File Queue Wakeup Select Payload Ram FU MUX Rd MUX Wr Sequential Reg Access Disable select for 1 CLK sequence register accesses forward the first value through bypass network Scheduling in sequential RF access • Back-to-back issue ==Reading values off the bypass • Back-to-back issue makes dependent instructions fall within bypass window • Non-back-to-back issue or 2 ready sources at insert time incur sequential RF access (assuming 1-clk cycle bypass window) • Scheduler considerations • !(wakeup && selected) in the same cycle sequential RF access • Delay tag broadcast by 1 clock cycle • Block the issue slot (only the one w/ seq RF access) for 1 cycle fornon-pipelined RF access operation Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3019
Machine models • Simplescalar-Alpha-based, 12-stage, 4/8-wide OoO + Speculative scheduling (same as before) • Alpha-style squashing scheduling recovery • invalidates all issued instructions (dependent / independent) behind the miss • 4-wide: 64 RUUs, 32 LSQs, 2 memory ports • 8-wide: 128 RUUs, 64 LSQs, 4 memory ports • 64K IL1 (2), 64K DL1 (2), 512K unified L2 (8) • Combined (bimodal + gShare) branch prediction, fetch until the first taken branch • Sequential RF access • ½ read-ported RF (1 read port / issue slot) • Comparison cases • Pipelined RF (1 extra RF stage) • ½ read-ported RF (same as sequential RF access) + crossbar Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3020
Sequential RF access performance • Seq RF access slowdown is slight: avg 1.1 / 0.7%, worst 2.2% • 1-extra RF stage requires extra bypass paths • ½ read ports + crossbar almost achieves base performance • crossbar complexity, global RF port arbitration Sequential RF access reduces the number of RF read ports with a minimal performance impact 4-wide 8-wide Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3021
Sequential wakeup + RF access • Performance degradation: avg 2.2%, worst 4.8% • Reduced wakeup bus load capacitance, fewer read ports of RF Half-price techniques reduce HW complexity, reaping most of the performance of a conventional pipeline Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3022
Conclusions & Future work • Processors are overdesigned to process 0, 1, 2-source instructions at equal cost • Handling 2-source instructions may not be the common case • Only a small fraction of instructions utilize overdesigned hardware • Reduce HW complexity by restricting the processor’s capability of handling 2-source instructions • Sequential wakeup, sequential RF access • The performance impact is minimal • The basic concept can be extended to all pipeline stages • Register rename, ready information check, bypass logic… • Changing the pipeline design from instruction- to operand-granularity Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3023
Questions? Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3024
1k 4k 128 512 vpr gcc mcf eon gap perl bzip gzip twolf crafty vortex parser vpr gcc gap perl eon bzip gzip mcf twolf crafty vortex parser Last-arriving operand predictor accuracy 4-wide 8-wide Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3025
r1, r4 r2 r1@cycle2 r2@cycle1 r1 r5 r2 - r4 r3 r3 r2 r3 r2 r4 r1 r4 - - r1 r5 r5 1 0 1 0 0 1 1 0 0 0 0 0 1 1 1 1 1 0 ADD r4@cycle2 SUB ADD ADD ADD XOR XOR SUB XOR SUB r3 r6 r5 r6 r3 r6 r5 r3 r5 r3 SUB r5 XOR r2 - OP rdy rdy dest issue Cycle 1 Cycle 2 Fast bus Slow bus r3 r1, r4 Cycle 3 issue ½ technique - Sequential wakeup • Sequential wakeup example time ADD r1, r2, r3 SUB r3, r4, r5 XOR r5, 1, r6 Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3026
tag r1 r2 Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 OR OR = = granted seq_reg_access request Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 ADD G S R r4 Select only Seq read r1 Seq read r2 Execute/ Bypass ADD Select only Reg read r1,r2 Execute/ Bypass r3 ADD … selected Select Logic readyL nowL (not sticky) tagL tagR nowR (not sticky) readyR 2-src dest tag delay SUB Wait Bubble Wakeup/ Select Reg Read r4 Execute/ Bypass SUB granted seq_reg_access Wait Wakeup/ Select Reg Read r4 Execute/ Bypass SUB extra delay G S R r5 Wait Bubble Wait Wakeup/ Select Reg no Read Execute/ Bypass seq_reg_access XOR XOR Wait Wait Wakeup/ Select Reg no Read Execute/ Bypass XOR Disable Select for 1 CLK Bubble request wakeup bus ½ technique – Sequential RF access • Scheduler changes for sequential RF access • Sequential RF access example ADD r1, r2, r3 SUB r3, r4, r5 XOR r5, 1, r6 Ilhyun Kim and Mikko Lipasti—UW-MADISON PHARM Team ISCA-3027