Input Documents
Document Categorization and Related Concepts Prediction using Wikipedia Articles, Category Network and Page Links Graph Zareen Saba Syed zarsyed1@umbc.edu. Wikipedia The Free Encyclopedia.

Input Documents
E N D
Presentation Transcript
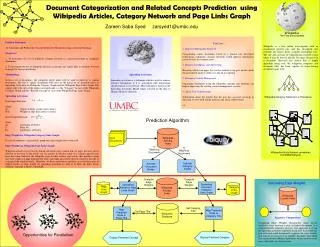
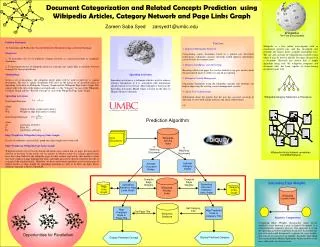
Document Categorization and Related Concepts Prediction using Wikipedia Articles, Category Network and Page Links Graph Zareen Saba Syed zarsyed1@umbc.edu Wikipedia The Free Encyclopedia Wikipedia is a free online encyclopedia with an exponential growth rate and has developed into probably the largest freely available knowledge base. The size and coverage of wikipedia has reached a limit where it may be used to identify the topics discussed in a document. Research has shown that a simple algorithm using only the wikipedia categories and document titles has been capable of characterizing documents quite well. Problem Statement: To Categorize and Predict the Concepts Related to Documents using a General Ontology. Objectives: 1. To investigate the use of wikipedia category network as a general ontology to categorize documents. 2. To investigate the use of wikipedia articles as concepts and article links as relations between concepts for concept prediction. Methodology: Given a set of documents, the wikipedia article index will be used to find top 'n' similar documents. The top 'n' similar documents will serve as the initial set of activated nodes in Spreading Activation on Wikipedia Category Graph and the Wikipedia Page Links Graph. The output will be the title of the highest activated node, i.e, the “Category” in case of the Wikipedia Category Graph and the “ Related Concept” in case of the Wikipedia Page Links Graph. Spreading Activation: Node Input Function: where Oi : Output of Node i connected to node j Wij : Weight on edge from node i to node j Node Output Function: where Aj : Activation of Node j k : Pulse No. Dj : Out Degree of Node j Edge Weights for Wikipedia Category Links Graph: In case of wikipedia category links graph unit edge weights have been used. Edge Weights for Wikipedia Page Links Graph: Wikipedia articles may be heavily linked and articles may contain links to pages that may not be relevant to the topic of the article, for eg. articles in which a name of a country appears may have that name linked to the wikipedia page for that country and articles that mention a term may have a link to a page defining that term, such links may not be directly related to the title or concept of the original article. Therefore, we have used lucene similarity score between pair of linked articles as edge weight for spreading activation as well as to filter out links where similarity measure is below a threshold. Use Cases 1. Improved Information Retrieval Categorizing corpus documents based on a general user developed folksonomy (wikipedia category network) would improve information retrieval tasks for common users. 2. Business Intelligence and Advertising Knowing which web pages the user has looked at can give an idea about the generalized interest of the user and aid in targeting. 3. Enterprise Content Management Organizing documents using the wikipedia concepts and ontology can help in improving the existing content management systems. 4. Aid in User Collaborations Information about the articles that the user has accessed can help in directing to users with similar interests and aid in collaboration. etc. Spreading Activation Spreading activation is a technique which is used to retrieve relevant information if it is associated with information already known to be relevant. This technique is based on the Spreading Activation Model which is based on the idea of Human Memory operation. Wikipedia Category Network is a Thesaurus Prediction Algorithm Input Documents Wikipedia Articles Index N Matching Documents N Matching Documents Wikipedia Article Network resembles the WWW Network Activate Category Nodes Activate Document Nodes Compute Edge Weights Compute Edge Weights Calculating Edge Weights Spreading Activation Category Links Graph Spreading Activation Page Links Graph Page Links Graph Category Links Graph Wikipedia Articles Index Wikipedia Lucene Index Get Category Title Map Predicted Node to Page Title Map Predicted Node to Category Title Get Page Title Wikipedia Database Expensive Computations Computing Edge Weights dynamically using lucene similarity score between a pair of linked documents is a computationally expensive process. One approach is to run the spreading activation algorithm in parallel. Each node that gets activated could dynamically compute the edge weights and activate its successors in parallel. Secondly, Spreading Activation involves Matrix Operations which could be done more efficiently on cell processor. Opportunities for Parallelism Display Predicted Category Display Predicted Concept