Download

1 / 24
240 likes | 260 Views
This research outlines a novel PTL synthesis approach utilizing partitioned ROBDDs to ensure optimal circuit performance and minimize memory explosion. By using advanced buffering techniques with CODCs and Boolean division, circuit delay and area can be significantly reduced.

E N D
Generalized Buffering of PTL Logic Stages using Boolean Division and Don’t Cares Rajesh Garg Sunil P. Khatri Department of Electrical and Computer Engineering, Texas A&M University, College Station, TX 77843
Outline • Introduction • Objective • Previous Work • CODCs and ACODCs • Generalized Buffering With CODCs • Results • Conclusions
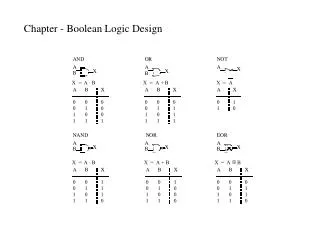
Introduction • Pass Transistor Logic (PTL) typically used for specific circuit implementations, like barrel shifters • No widely accepted PTL design methodology • There exists a direct mapping between an ROBDD node and a PTL mux f f f v v’ v v 1 0 fv fv fv’ fv’ fv fv’ ROBDD Node MUX PTL based MUX • Hence ROBDDs can be used to perform PTL based synthesis for general circuits
Introduction (contd) • Problems with direct mapping • Body Effect • Cannot connect more than 4-5 devices in series • Monolithic ROBDDs • Worst-case exponential size in number of the inputs (large) • Memory explosion can occur during ROBDD construction • Partitioned ROBDDs • Avoids memory explosion of monolithic ROBDDs • Output of each PTL structure needs to be buffered • Regenerate electrical drive capability after 4 or 5 levels using a pair of inverters (avoid body effect problems)
Objective • New PTL Synthesis Approach • Use partitioned ROBDDs • Avoid memory explosion • Guarantee no more than 4-5 series devices • Use generalized buffering • Buffers can be complex logic gates in general (not simple inverters/ buffers) • Use ACODCs or CODCs to improve the extraction of generalized buffers • Simplifies the logic function of the PTL block • Boolean Division based formulation • Elegant, powerful formulation to extract generalized buffers • Augmented with CODC / ACODCs • Reduces total circuit delay and area
Previous Work • Buch et. al, “Logic synthesis for large pass transistor circuits”, in Proceedings, IEEE/ACM ICCAD, Nov 1997, pp 663-670 • Lai et. al, “BDD decomposition for mixed CMOS/PTL logic circuit synthesis”, in Proceedings, IEEE ISCAS, May 2005, pp. 5649-5652 • Yamashita et. al, “Pass-transistor/CMOS collaborated logic: The best of both worlds”, in Digest of Technical Papers, Symposium on VLSI Circuits, June 1997, pp. 31-32. • Garg et. al, “Generalized buffering of PTL logic stages using Boolean division”, in Proceedings, IEEE ISCAS, May 2006.
CODCs • Observability Don’t Cares (ODCs) • ODCs used to minimize the logic function of a node • Need to re-compute the ODCs of the other nodes after optimization • Compatible Observability Don’t Cares • Can simultaneously change the function of all nodes • Subset of ODCs • full_simplify is used to compute CODCs in SIS • ROBDD based computation to compute CODCs
CODCs (contd.) • Memory intensive • Computation is possible only for small and medium sized circuits • Approximate CODCs by Saluja et. al • 30X faster than full CODCs • Requires 30X less memory than full CODCs • Literal count reduction is about 80% of that obtained by full CODCs • Can compute ACODCs for arbitrarily large circuits
PTL with Generalized Buffering Primary Output Primary Output Primary Inputs Primary Inputs
Boolean Division • Definition 1: g is a Boolean divisor of f if h and r exist such that f = gh + r where, gh≠ Ø • Definition 2: g is a Boolean factor of f if, g is a Boolean divisor of f, and in addition, r = Ø , i.e. f = gh • Theorem: If fg≠ Ø, then g is a Boolean divisor of f.
ROBDD Division • Consider a (partitioned) ROBDD f of a node n in the network • Let d represent the CODCs of node n • Consider a library gate g ≡ G • Division of f by g can be represented by following equations: // Upper bound of f //Lower bound of f Therefore, quotient remainder Finally,
Generalized Buffering with CODCs • Synthesize partitioned PTL blocks with • Maximum depth of 5 • No more than 5 transistors in series • Optimize and decompose network • Using only 2-input gates and inverters • PTL structure will grow in predictable manner • Initially any ROBBD can have maximum 8 variables • If division fails, we can make one of the fanins a ROBDD variable -- back-track
Algorithm: Generalized Buffering with CODCs A = dfs_and_levelize_nodes(η*) i =1 whilei ≤ size(A) do n = array_fetch(A,i) f = ntbdd_node_to_bdd(n) //creates ROBDD of node n if bdd_depth(f) ≥ 5 then forg ≡ GGate Library do d = compute_dc(n) f = test_division(f,g,d,G) end for if bdd_depth(f) > 5 then back-track else bdd_create_variable(n) continue end if else continueend if end while
test_division with CODCs test_division(f,d,g,G) { iffg≠ 0 then Z = bdd_between(L,U) Z* = bdd_smooth(Z,gvars) R = bdd_compose(Z*,G,g) iff R f + d && bdd_depth(Z*) < bdd_depth(f) then return(success, Z*) end if else return fail end if }
back-track Needs back-track n b Re-process b a n Make ‘c’ a variable c n-1 d n-2 n-2
Experimental Setup • Implemented in SIS • Process Technology- 100nm BPTM • Gate Library • AND2, AND3, AND4 • OR2, OR3, OR4 • A set of benchmark circuits were synthesized • Compared with traditional method • Inverters for buffering • Similar to method reported by Buch. et. al • Also compared with generalized buffering without don’t cares
Conclusions • Generalized buffering with ACODCs results in delay reduction by • 29% over traditional buffering • 5% over generalized buffering without don’t cares • Area reduction obtained by generalized buffering with ACODCs is • 5% compared to traditional buffering • 2% compared to generalized buffering without don’t cares • Multiplexers also reduced by • 27% compared to traditional buffering • 4% compared to generalized buffering without don’t cares
Conclusions (contd) • A large number of divisions were obtained for each circuit • Little advantage of using CODCs over ACODCs • Delay reduction is less than 1% • Area increases by 1% • Run-time is 76X slower • Can synthesize arbitrary sized circuits using partitioned ROBDDs and ACODC based division
Thank You!! Questions?