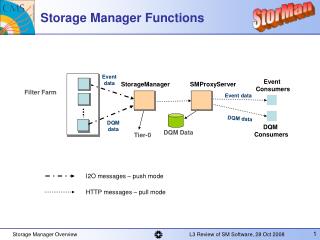
V Storage Manager
V Storage Manager. Shahram Ghandeharizadeh Computer Science Department University of Southern California. Traces. Make sure your persistent BDB is configured with 256 MB of memory.


V Storage Manager
E N D
Presentation Transcript
V Storage Manager Shahram Ghandeharizadeh Computer Science Department University of Southern California
Traces • Make sure your persistent BDB is configured with 256 MB of memory. • With a trace, say 21, use its “21Objs.Save” to create and populate your persistent database. Subsequently, use its “Trace21.1KGet” to debug your software. • Start with 1 thread and expand to 2, 3, and 4. • Try to make your software as efficient as possible. If it is too slow (maybe because of low byte hit rates) then you may not be able to run “Trace21.1MGet”.
Questions • Will there be another release of the workload generator before Friday? • I do not anticipate one unless there is a bug report. • Is there an obvious item missing from the current workload generator? • Mandatory: Invocation of the method to report cache and byte hit rates. • Optional: Dump the content of the cache to analyze the behavior of your cache replacement technique.
Hints • BDB-Disk is a full-fledged storage manager with a buffer pool, locking, crash-recovery, index structures. • Configure its buffer pool size to be 256 MB. V Functionalities Cache Replacement BDB-Disk BDB-Mem
Hints • Your implementation may need to keep track of different counters. Example: count the number of requests issued (and the number of requests serviced from the main-memory instance of BDB) to compute the cache hit rate. • How to do this with multiple worker threads?
Hints • Your implementation may need to keep track of different counters. Example: count the number of requests issued to compute the cache hit rate. • How to do this with multiple worker threads? • The interlocked function provides a mechanism for synchronizing access to a variable that is shared by multiple threads. • You may define a “long” variable and use InterlockedIncrement: “long cntr; InterlockedIncrement(&cntr);” • Make sure to include <windows.h>
Hints • To compute byte hit rates, you need to maintain two counters and increment them by the size of the referenced object. • Use “InterlockedExchangeAdd” function to perform an atomic addition of two 32 bit values. • Example: a = a + b; • InterlockedExchangeAdd(&a, &b); • Other Interlocked methods might be useful to you, such as InterlockedExchangePointer.
Hints • With invocation of methods, local variables are pushed on the stack of a thread. • 4 different threads invoking a method will have 4 different sets of mutually exclusive local variables as declared by that method. Foo(){ Char res[200]; Int cntr; … } • A global variable is not part of the stack and must be protected when multiple threads are manipulating it. How?
Hints • With invocation of methods, local variables are pushed on the stack of a thread. • 4 different threads invoking a method will have 4 different sets of mutually exclusive local variables as declared by that method. Foo(){ Char res[200]; Int cntr; … } • A global variable is not part of the stack and must be protected when multiple threads are manipulating it. How? • Consider making it a variable local to a method. Ask: Does this variable have to be global? • Use critical sections. • Manage memory.
Hints • With invocation of methods, local variables are pushed on the stack of a thread. • 4 different threads invoking a method will have 4 different sets of mutually exclusive local variables as declared by that method. Foo(){ Char res[200]; Int cntr; … } • Similarly, memory allocated from the heap (new/malloc) is not a part of the stack and must be managed. • No memory-leaks.
Hints • Consider an admission control technique. • Without admission control: • Everytime an object is referenced and it is not in memory then you place it in memory. • With admission control: • Every time a disk resident object is referenced, compare its Q value with the minimum Q value to see if it should be admitted into memory.
Fast Algorithms for Mining Association Rules (by R. Agrawal and R. Srikant) Shahram Ghandeharizadeh Computer Science Department University of Southern California
Terminology • Objective: Discover association Rule over basket data. • Example: 98% of customers who purchase tires and auto accessories also get automotive services done. • Motivation: valuable for cross-marketing and attached mailing applications. • Watch Googlezon, http://www.youtube.com/watch?v=AT9ho2G0N_Y • Requirements: • Fast algorithms, • Must manipulate large data sets.
Terminology • Association rule XY has confidence c, Out of those transactions that contain X, c% also contain Y. • Association rule XY has support s, s% of transactions in D contain X and Y. Note: • X A doesn’t mean X+YA • May not have minimum support • X A and A Z doesn’t mean X Z • May not have minimum confidence
Example • I = {beer, chips, salsa, nail-polish, toothpaste, toilet-paper} • D = {T1, T2, T3, …., T9999999} • T1 = {beer, chips, salsa} • T2 = {beer, toilet-paper} • T3 = {nail-polish, toothpaste} • TID is the unique identifier for each transaction. • If X = {beer} then both T1 and T2 contain X. • If X = {beer, chips} then T1 contains X. • If X = {beer, nail-polish} then no transaction contains X. • The rule {beer, chips} => {salsa} with confidence 90% if 90% of transactions that contain {beer, chips} also contain {salsa}. • NOTE: {beer, chips} intersect {salsa} is empty, satisfying the constraint of the formal problem specification. • The rule {beer, chips} => {salsa} has support 75% if 75% of transactions contain {beer, chips, salsa}.
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {nail-polish} => {tooth-paste}?
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {nail-polish} => {tooth-paste}? • 100% because 5000 out of 5,000 transactions that contain {nail-polish} also contain {tooth-paste}.
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {beer} => {salsa}? • 25% because 1000 out of 5000 transactions that contain {beer} also contain {salsa}
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {salsa} => {chips}?
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {salsa} => {chips}? • 100% because 6000 out of 6000 transactions that contain {salsa} also contain {chips}
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {salsa} => {nail-polish}?
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {salsa} => {nail-polish}? • 5/6 (83.33%) because 5000 out of 6000 transactions that contain {salsa} also contain {chips} • Note: • Support for {salsa, nail-polish} is
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {salsa} => {nail-polish}? • 5/6 (83.33%) because 5000 out of 6000 transactions that contain {salsa} also contain {chips} • Note: • Support for {salsa, nail-polish} is 50% (5000 out of 10000) • Support for {slasa} is
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {salsa} => {nail-polish}? • 5/6 (83.33%) because 5000 out of 6000 transactions that contain {salsa} also contain {chips} • Note: • Support for {salsa, nail-polish} is 50% (5000 out of 10000) • Support for {slasa} is 60% (6000 out of 10000) • Conf = 50% / 60% = 83.33%
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {beer, chips} => {toilet-paper}?
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the confidence in {beer, chips} => {toilet-paper}? • 0% because none of the transactions satisfy this association rule.
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the support in {beer} => {toilet-paper}?
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the support in {beer} => {toilet-paper}? • 40% because 4000 transactions (out of 10,000) contain {beer, toilet-paper}
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the support in {chips} => {salsa}?
Example (Cont…) • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • What is the support in {chips} => {salsa}? • 60%, 6000 transactions contain {chips, salsa}.
Example Queries • Compute all association rules with support and confidence greater than 55%. • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • Answer:
Example Queries • Compute all association rules with support and confidence greater than 55%. • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • Answer: • {chips} => {salsa}, • {salsa} => {chips}
Example Queries • Compute all association rules with support > 30% and confidence greater than 40%. • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • Answer:
Example Queries • Compute all association rules with support > 30% and confidence greater than 45%. • Assume: • 1000 transactions {beer, chips, salsa} • 4000 transactions {beer, toilet-paper} • 5000 transactions {nail-polish, tooth-paste, chips, salsa} • Answer: • {chips} => {salsa}, • {salsa} => {chips}, • {nail-polish} => {tooth-paste}, • {tooth-paste} => {nail-polish}, • {nail-polish} => {chips}, • {nail-polish}=>{tooth-paste}, • {nail-polish} => {salsa} • ….
Divide the Problem into Two • Find all sets of items that have support above minimum support. • Itemsets with minimum support are called large itemsets and all others small itemsets. • Algorithms: Apriori and AprioriTid. • Use large itemsets to generate the desired rules. • For every large itemset l, find all non-empty subsets of l. Let a denote one subset. • For every subset a, output a rule of the form a => { {l} – {a} } if support(l) / support(a) is at least minconf. • Say ABCD and AB are large itemsets • Compute conf = support(ABCD) / support(AB) • If conf >= minconf AB CD holds.
Conquer • Focus on item 1: • Find all sets of items that have support above a pre-specified minimum support. • Example: • Assume the following database: • Itemsets with minimum support of 2 transactions?
Conquer • Focus on item 1: • Find all sets of items that have support above a pre-specified minimum support. • Example: • Assume the following database: • Itemsets with minimum support of 2 transactions?
How? • General idea: • Multiple passes over the data • First pass – count the support of individual items. • Subsequent pass • Generate Candidates using previous pass’s large itemset. • Go over the data and check the actual support of the candidates. • Stop when no new large itemsets are found.
How? • Make several passes of DB. • Pass 1: count item occurrences to determine the large 1-itemsets.
How? • Make several passes of DB. • Pass 1: count item occurrences to determine the large 1-itemsets. • Notice that {4} is missing! • Pass 2: Compute the following query: SELECT p.item1, q.item1 FROM L1 p, L1 q WHERE p.item1 < q.item1
How? • Make several passes of DB. • Pass 1: count item occurrences to determine the large 1-itemsets. • Notice that {4} is missing! • Pass 2: Compute the priori-gen query and count the support for each by making a pass of DB.
How? • Make several passes of DB. • Pass 1: count item occurrences to determine the large 1-itemsets. • Notice that {4} is missing! • Pass 2: Compute the priori-gen query and count the support for each by making a pass of DB. • Drop those with support < minsup • Pass j (j >= 3): Compute candidate set using apriori-gen algorithm
Apriori-gen Algorithm • Intuition: Generate the candidate itemsets to be counted in a pass by using only the itemsets found large in the previous pass. • How? • Note that when k=2, this query computes a large number of rows: the cartesian product of L1 – number of rows in L1. If L1 has 100 rows, the resulting number of rows is 9900 (10000-100).
Apriori-gen Algorithm • Intuition: Generate the candidate itemsets to be counted in a pass by using only the itemsets found large in the previous pass. • What is the result when k = 3? What is the SQL command?
Apriori-gen Algorithm • Intuition: Generate the candidate itemsets to be counted in a pass by using only the itemsets found large in the previous pass. • What is the result when k = 3? INSERT into Ck SELECT p.item1, p.item2, q.item2 FROM L2 p, L2 q WHERE p.item1 = q.item1 and p.item2 < q.item2 Result?
Apriori-gen Algorithm • Intuition: Generate the candidate itemsets to be counted in a pass by using only the itemsets found large in the previous pass. • What is the result when k = 3? INSERT into Ck SELECT p.item1, p.item2, q.item2 FROM L2 p, L2 q WHERE p.item1 = q.item1
Apriori-gen Algorithm • Intuition: Generate the candidate itemsets to be counted in a pass by using only the itemsets found large in the previous pass. • What is the result when k = 3? Computed by the SQL query. Computed by making a pass on the DB.
Intuition Any subset of large itemset is large. Therefore To find large k-itemset • Create candidates by combining large k-1 itemsets. • Delete those that contain any subset that is not large.