Download

1 / 44
481 likes | 1.37k Views
Least Squares Regression and Multiple Regression. Regression: A Simplified Example.

E N D
Regression: A Simplified Example Let’s find the best-fitting equation for predicting new, as yet unknown scores on Y from scores on X. The regression equation takes the form Y = a + bX + e where Y is the dependent or criterion variable we’re trying to predict, a is the intercept or point where the regression line crosses the Y axis, X is the independent or predictor variable, b is the weight by which we multiply the value of X (it is the slope of the regression line, and is how many units Y increases (decreases) for every unit change in X), and e is an error term (basically an estimate of how much our prediction is “off”). a and b are often called “regression coefficients. When Y is an estimated value it is usually symbolized as Y’
Finding the Regression Line with SPSS • First let’s use a scatterplot to visualize the relationship between X and Y. The first thing we notice is that the points appear to form a straight line and that that as X gets larger, Y gets larger, so it would appear that we have a strong, positive relationship between X and Y. Based on the way the points seem to fall, what do you think the value of Y would be for a person who obtained a score of 7 on X?
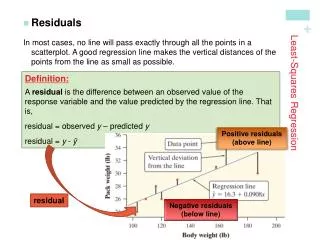
Fitting a Line to the Scatterplot • Next let’s fit a line to the scatterplot. Note that the points appear to be fit well by the straight line, and that the line crosses the Y axis (at the point called the intercept, or the constant a in our regression equation) at about the point y = 2. So it’s a good guess that our regression equation will be something like y = 2 + some positive multiple of X, since the values of Y look to be about 4-5 times the size of X
The Least Squares Solution to Finding the Regression Equation • Mathematically, the regression equation is that combination of constant and weights b on the predictors (the X’s) which minimizes the sum, across all subjects, of the squared differences between their predicted scores (e.g. the scores they would get if the regression equation were doing the predicting) and the obtained scores (their actual scores) on the criterion Y (that is, it minimizes the error sum of squares or residuals). This is known as the least squares solution • The correlation between the obtained scores on the criterion or dependent variable, Y, and the scores predicted by the regression equation is expressed in the correlation coefficient, r, or in the case of more than one independent variable, R.* Alternatively it expresses the correlation between Y and the weighted combination of predictors. R ranges from zero to 1 • *SPSS uses R in the regression output even if there is only one predictor
Using SPSS to Calculate the Regression Equation • Download the Data File simpleregressionexample.sav and open it in SPSS • In Data Editor, we will go to Analyze/ Regression / Linear and move X into the Independent box (in regression the Independent variables are the predictor variables) and move Y into the dependent box and click OK. The dependent variable, Y, is the one for which we are trying to find an equation that will predict new cases of Y given than we know X
Obtaining the Regression Equation from the SPSS Output This table gives us the regression coefficients. Look in the column called unstandardized coefficients. There are two values of β provided. The first one, labeled the constant, is the intercept a, or the point at which the regression line crosses the y axis. The second one, X, is the unstandardized regression weight or the b from our regression equation. So this output tells us that the best-fitting equation for predicting Y from X is Y = 2 + (4)X. Let’s check that out with a known value of X and Y. According to the equation, if X is 3, Y should be 2 + 4(3), or 14. How about when X = 5? The constant representing the intercept is the value that the dependent variable would take when all the predictors are at a value of zero. In some treatments this is called B0 instead of a
What is the Regression Equation when the Scores are in Standard (Z) Units? • When the scores on X and Y have been converted to Z scores, then the intercept disappears (because the two sets of scores are expressed on the same scale) and the equation for predicting Y from X just becomes Y = BetaX, where Beta is the standardized coefficient reported in your SPSS regression procedure output In the bivariate case, where there is only one X and one Y, the standardized beta weight will equal the correlation coefficient. Let’s confirm this by seeing what would happen if we convert our raw scores to Z scores
Regression Equation for Z scores • In SPSS I have converted X and Y to two new variables, ZX and ZY, expressed in standard score units. You achieve this by going to Analyze/ Descriptive/ Descriptives (don’t do this now), moving the variables you want to convert into the variables box, and selecting “save standardized values as variables”. This creates the new variables expressed as Z scores. Note that if you reran the linear regression analysis that we just did on the raw scores, that in the output for the regression equation for predicting the standard scores on Y the constant has dropped out and the equation is now of the form y = Beta x, where Beta is equal to 1. In this case the z scores are identical on X and Y although they certainly wouldn’t always be
Meaning of Regression Weights • The regression weights or regression coefficients (the raw score β s and the standardized Betas) can be interpreted as expressing this unique contribution of a variable: you can say they represent the amount of change in Y that you can expect to occur per unit change in Xi , where X is the ith variable in the predictive equation, when statistical control has been achieved for all of the other variables in the equation • Let’s consider an example from the raw-score regression equation Y = 2 + (b)X, where the weight b is 4: Y = 2 + (4) X. In predicting Y, what the weight b means is that for every unit change in X, Y will be increased fourfold. Consider the data from this table and verify that this is the case. For example, if X = 1, Y = 6. Now make a unit change of 1 in X, so that X is 2, and Y becomes equal to 10. Make a further unit change of 2 units to 3, and Y becomes equal to 14. Make a further unit change of 3 units to 4, and Y becomes equal to 18. So each unit change in X increases Y fourfold (the value of the b weight). If the b weight were negative (e.g. y = 2 –bx) the value of y would decrease fourfold for every unit increase in X
Finding the Regression Equation for Some Real-World Data • Download the World95.sav data file and open it in SPSS Data Editor. We are going to find the regression equation for predicting the raw (unstandardized) scores on the dependent variable, Average Female Life Expectancy (Y) from Daily Calorie Intake (X). Another way to say this is that we are trying to find the regression of Y on X. • Go to Graphs/Chart Builder/OK • Under Choose From select ScatterDot (top leftmost icon) and double click to move it into the preview window • Drag Daily Calorie Intake onto the X axis box • Drag Average Female Life Expectancy onto the Y axis box and click OK • In the Output viewer, double click on the chart to bring up the Chart Editor; go to Elements and select “Fit Line at Total,” then select “linear” and click Close
Scatterplot of Relationship between Female Life Expectancy and Daily Caloric Intake From the scatterplot it would appear that there is a strong positive correlation between X and Y (as daily caloric intake increases, life expectancy increases),and X can be expected to be a good predictor of as-yet unknown cases of Y. (Note, however, that there is a lot of scatter about the line and we may need additional predictors to “soak up” some of the variance left over after this particular X has done its work (also consider loess regression “In the loess method, weighted least squares is used to fit linear or quadratic functions of the predictors at the centers of neighborhoods. The radius of each neighborhood is chosen so that the neighborhood contains a specified percentage of the data points)”
Finding the Regression Equation • Go to Analyze/ Regression/ Linear • Move the Average Female Life Expectancy variable into the dependent box and the Daily Calorie Intake variable into the independent box • Under Options, make sure “include constant in equation” is checked and click Continue • Under Statistics, Check Estimates, Confidence intervals, and Model Fit. Click Continue and then OK • Compare your output to the next slide
Interpreting the SPSS Regression Output • From your output you can obtain the regression equation for predicting Average Female Life Expectancy from Daily Calorie Intake. The equation is Y = 25.904 + .016X + e, where e is the error term. Thus for a country where the average daily calorie intake is 3000 calories, the average female life expectancy is about 25.904 + (.016)(3000) or 73.904 years. This is a raw score regression equation Significance of constant of little use. Just says that it differs significantlyfrom zero (e.g when x is zero, y is not zero) This is a standardized partial regression coefficient or beta weight If the data were expressed in standard scores, the equation would be ZY = .775ZX + e, and .775 is also the correlation between X and Y. This is a standard score regression equation a b These weights are called unstandardized partial regression coefficients or weights
More Information from the SPSS Regression Output • There are some other questions we could ask about this regression • (1) Is the regression equation a significant predictor of Y? (That is, is it good enough to reject the null hypothesis, which is more or less that the mean of Y is the best predictor of any given obtained Y). To find this out we consult the ANOVA output which is provided and look for a significant value of F. In this case the regression equation is significant • (2) How much of the variation in Y can be explained by the regression equation? To find this out we look for the value of R square, which is .601 Residual SS is the sum of squared deviations of the known values of Y and the predicted values of Y based on the equation Regression SS is the sum of the squared deviations of the predicted variable about its mean
How Much Error do We Have? • Just how good a job will our regression equation do in predicting new cases of Y? As it happens the greater the departure of the obtained Y scores from the location that the regression equation predicted they should be, the larger the error • If you created a distribution of all the errors of prediction (what are called the residuals or the differences between observed and predicted score for each case), the standard deviation of this distribution would be the standard error of estimate • The standard error of estimate can be used to put confidence intervals or prediction intervals around predicted scores to indicate the interval within which they might fall, with a certain level of confidence such as .05
Confidence Intervals in Regression • Look at the columns headed “95% confidence intervals”. These columns put confidence intervals based on the standard error of estimate around the regression coefficients a and b. Thus for example in the table below we can say with 95% confidence that the value of the constant a lies somewhere between 17.583 and 34.225, and the value of the regression coefficient b (unstandardized) lies somewhere between .013 and .019) Looking at the standard error of the standardized coefficient we can see that the estimate R (which is also the standardized version of b) is 775. Thus we could say with 95% confidence that if ZX is the Z score corresponding to a particular calorie level, life expectancy is .775 (Zx) plus or minus 7.255 years SEE = SD of X multiplied by the square root of the coeffiecient of nondetermination.Says what an error standard score of 1 is equal to in terms of Y units
Multivariate Analysis • Multivariate analysis is a term applied to a related set of statistical techniques which seek to assess and in some cases summarize or make more parsimonious the relationships among a set of independent variables and a set of dependent variables • Multivariate analyses seeks to answer questions such as • Is there a linear combination of personal and intellectual traits that will maximally discriminate between people who will successfully complete freshman year of college and people who drop out? What linear combination of characteristics of the tax return and the taxpayer best distinguish between those whom it would and would not be worthwhile to audit? (Discriminant Analysis) • What are the underlying factors of an 94-item statistics test, and how can a more parsimonious measure of statistical knowledge be achieved? (Factor Analysis) • What are the effects of gender, ethnicity, and language spoken in the home and their interaction on a set of ten socio-economic status indicators? Even if none of these is significant by itself, will their linear combination yield significant effects? (MANOVA, Multiple Regression)
More Examples of Multivariate Analysis Questions • What are the underlying dimensions of judgment in a set of similarity and/or preference ratings of political candidates? (Multidimensional Scaling) • What is the incremental contribution of each of ten predictors of marital happiness? Should all of the variables be kept in the prediction equation? What is the maximum accuracy of prediction that can be achieved? (Stepwise Multiple Regression Analysis) • How do a set of univariate measures of nonverbal behavior combine to predict ratings of communicator attractiveness? (Multiple regression) • What is the correlation between a set of measures assessing the attractiveness of a communicator and a second set of measures assessing the communicator’s verbal skills? (Canonical Correlation)
An Example (sort of) of Multivariate Analysis: Multiple Regression • A good place to start in learning about multivariate analysis is with multiple regression. Perhaps it is not strictly speaking a multivariate procedure since although there are multiple independent variables there is only one dependent variable • Canonical correlation is perhaps a more classic multivariate procedure with multiple dependent and independent variables • Multiple regression is a relative of simple bivariate or zero-order correlation (two interval-level variables) • In multiple regression, the investigator is concerned with predicting a dependent or criterion variable from two or more independent variables. The regression equation (raw score version) takes the form Y = a + b1X1 + b2X2 + b3X3 + ……..bnXn + e • One motivation for doing this is to be able to predict the scores on cases for which measurements have not yet been obtained or might be difficult to obtain . The regression equation can be used to classify, rate, or rank new cases
Coding Categorical Variables in Regression • In multiple regression, both the independent or predictor variables and the dependent or criterion variables are usually continuous (interval or ratio-level measurement) although sometimes there will be concocted or “dummy” independent variables which are categorical (e.g., men and women are assigned scores of one or two on a dummy gender variable; or, for more categories, K-1 dummy variables are used where 1 equals “has the property” and 0 equals “doesn’t have the property” • Consider the race variable from one of our data sets which has three categories: White, African-American, and Other. To code this variable for multiple regression, you create two dummy variables, “White” and “African-American”. Each subject will get a score of either 1 or 0 on each of the two variables African- American Caucasian
Coding Categorical Variables in Regression, cont’d High Status Medium Status • You can use this same type of procedure to code assignments to levels of a treatment in an experiment, and thus you can use a “factor” from an experiment, such as interviewer status, as a predictor variable in a regression. For example if you had an experiment with three levels of interviewer attire, you would create one dummy variable for the high status attire condition and one for the medium status attire and the people in the low status attire condition would get 0,0 on both variables, where high status condition subjects would get 1,0 and medium status condition subjects would get 0, 1 scores on the two variables, respectively
Regression and Prediction • Most regression analyses look for a linear relationship between predictors and criterion although nonlinear trends can be explored through regression procedures as well • In multiple regression we attempt to derive an equation which is the weighted sum of two or more variables. The equation tells you how much weight to place on each of the variables to arrive at the optimal predictive combination • The equation that is arrived at is the best combination of predictors for the sample from which it was derived. But how well will it predict new cases? • Sometimes the regression equation is tested against a new sample of cases to see how well it holds up. The first sample is used for the derivation study (to derive the equation) and a second sample is used for cross-validation. If the second sample was part of the original sample reserved for just this cross-validation purpose, then it is called a hold-out sample.
Simultaneous Multiple Regression Analysis • One of the most important notions in multiple regression analysis is the notion of statistical control, that is, mathematical operations to remove the effects of potentially confounding or “third” variables from the relationship between a predictor or IV and a criterion or DV. Terms you might hear which refer to this include • Partialing • Controlling for • Residualizing • Holding constant
Meaning of Regression Weights • In multiple regression when you have multiple predictors of the same dependent or criterion variable Y the standardized regression coefficient, or Beta1 expresses the independent contribution to predicting variable Y of X1 when the effects of the other variables X2 through Xn are not a factor (have been statistically controlled for), and similarly for weights Beta2 through Betan • These regression weights or coefficients can be tested for statistical significance and it will be possible to state with 95% (or 99%) confidence that the magnitude of the coefficient differs from zero, and thus that that particular predictor makes a contribution to predicting the criterion or dependent variable, Y, that is unrelated to the contribution of any of the other predictors
Tests of the Predictors • The magnitude of the raw score weights (usually symbolized by b1, b2, etc) cannot be directly compared since they are associated with (usually) variables with different units of measurement • It is common practice to compare the standardized regression weights (the Beta1, Beta 2, etc) and make claims about the relative importance of the unique contribution of each predictor variable to predicting the criterion • It is also possible to do tests for the significance of the differences between two predictors: is one a significantly better predictor than the other • These coefficients vary from sample to sample so it’s not prudent to generalize too much about the relative ability of two predictors to predict • It’s also the case that in the context of the regression equation the variable which is a good predictor is not the original variable, but rather a residualized version for which the effects of all the other variables have been held constant. So the magnitude of its contribution is relative to the other variables, and only holds for this particular combination of variables included in the predictive equation
How Do we Find the Regression Weights (Beta Weights)? • Although this is not how SPSS would calculate them, we can get the Beta weights from the zero-order (pairwise) correlations between Y and the various predictor variables X1, X2, etc and the intercorrelations among the latter • Suppose we want to find the beta weights for an equation Y = Beta1X1 + Beta2X2 • We need three correlations: the correlation between Y and X1; the correlation between Y and X2, and the correlation between X1 and X2
How Do we Find the Regression Weights (Beta Weights)?, cont’d • Let’s suppose we have the following data: r for Y and X1 = .776; r for Y and X2 is .869; and r for X1 and X 2 is .682. • The formula for predicting the standardized partial regression weight for X1 with the effects of X2 removed is * Beta X1Y.X2 = r X1Y – (r X2Y)(r X1X2) 1 – r2X1X2 Substituting the correlations we already have in the formula, we find that the beta weight for the predictive effect of variable X1 on Y is equal to .776 – (.869)(.682) / 1 – (.682)2 = .342. To compute the second weight, Beta X2Y.X1, we just switch the first and second terms in the numerator. Now let’s see that in the context of an SPSS-calculated multiple regression *Read this as the Beta weight for the regression of Y on X1 when the effects of X2 have been removed
Multiple Regression using SPSS • Suppose we think that the ability of Daily Calorie Intake to predict Female Life Expectancy is not adequate, and we would like to achieve a more accurate prediction. One way to do this is to add additional variables to the equation and conduct a multiple regression analysis. • Suppose we have a suspicion that literacy rate might also be a good predictor, not only as a general measure of the state of the country’s development but also as an indicator of the likelihood that individuals will have the wherewithal to access health and medical information. We have no particular reasons to assume that literacy rate and calorie consumption are correlated, so we will assume for the moment that they will have a separate and additive effect on female life expectancy • Let’s add literacy rate (People who Read %) as a second predictor (X2), so now our equation that we are looking for is Y = a + b1X1 + b2X2where Y = Female Life Expectancy, Daily Calorie Intake is X1 andLiteracy Rate is X2
Multiple Regression using SPSS: Steps to Set Up the Analysis • Download the World95.sav data file and open it in SPSS Data Editor. • In Data Editor go to Analyze/ Regression/ Linear and click Reset • Put Average Female Life Expectancy into the Dependent box • Put Daily Calorie Intake and People who Read % into the Independents box • Under Statistics, select Estimates, Confidence Intervals, Model Fit, Descriptives, Part and Partial Correlation, R Square Change, Collinearity Diagnostics, and click Continue • Under Options, check Include Constant in the Equation, click Continue and then OK • Compare your output to the next several slides
Interpreting Your SPSS Multiple Regression Output • First let’s look at the zero-order (pairwise) correlations between Average Female Life Expectancy (Y), Daily Calorie Intake (X1) and People who Read (X2). Note that these are .776 for Y with X1, .869 for Y with X2, and .682 for X1 with X2 r YX1 r X1X2 r YX2
Examining the Regression Weights Above are the raw (unstandardized) and standardized regression weights for the regression of female life expectancy on daily calorie intake and percentage of people who read. Consistent with our hand calculation, the standardized regression coefficient (beta weight) for daily caloric intake is .342. The beta weight for percentage of people who read is much larger, .636. What this weight means is that for every unit change in percentage of people who read (that is, for every increase by a factor of one standard deviation on the people who read variable), Y (female life expectancy) will increase by a multiple of .636 standard deviations. Note that both the beta coefficients are significant at p < .001
R, R Square, and the SEE Above is the model summary, which has some important statistics. It gives us R and R square for the regression of Y (female life expectancy) on the two predictors. R is .905, which is a very high correlation. R square tells us what proportion of the variation in female life expectancy is explained by the two predictors, a very high .818. It gives us the standard error of estimate, which we can use to put confidence intervals around the unstandardized regression coefficients
F Test for the Significance of the Regression Equation Next we look at the F test of the significance of the Regression equation, Y = .342 X1 + .636 X2. Is this so much better a predictor of female literacy (Y) than simply using the mean of Y that the difference is statistically significant? The F test is a ratio of the mean square for the regression equation to the mean square for the “residual” (the departures of the actual scores on Y from what the regression equation predicted). In this case we have a very large value of F, which is significant at p <.001. Thus it is reasonable to conclude that our regression equation is a significantly better predictor than the mean of Y.
Confidence Intervals around the Regression Weights Finally, your output provides confidence intervals around the unstandardized regression coefficients. Thus we can say with 95% confidence that the unstandardized weight to apply to daily calorie intake to predict female life expectancy ranges between .004 and .010, and that the undstandardized weight to apply to percentage of people who read ranges between .247 and .383
Multicollinearity • One of the requirements for a mathematical solution to the multiple regression problem is that the predictors or independent variables not be highly correlated • If in fact two predictors are perfectly correlated, the analysis cannot be completed • Multicollinearity (the case in which two or more of the predictors are too highly correlated) also leads to unstable partial regression coefficients which won’t hold up when applied to a new sample of cases • Further, if predictors are too highly correlated with each other their shared variance with the dependent or criterion variable may be redundant and it’s hard to tell just using statistical procedures which variable is producing the effect • Moreover, the regression weights for the predictors would look much like their zero-order correlations with Y if the predictors are dependent; if the predictors are highly correlated this may produce regression weights that don’t really reflect the independent contribution to prediction of each of the predictors
Multicollinearity, cont’d • As a rule of thumb, bivariate zero-order correlations between predictors should not exceed .80 • This is easy to prevent; run complete analysis of all possible pairs of predictors using the correlation procedure • Also, no predictor should be totally accounted for by a combination of the other predictors • Look at tolerance levels. Tolerance for a predictor variable is equal to 1-R2 for an equation where one of the predictors is regressed on all of the other predictors. If the predictor is highly correlated with (explained by) the combination of the other predictors, it will have a low tolerance, approaching zero, because the R2 will be large • So, zero tolerance = BAD, near 1 tolerance = GOOD in terms of independence of a predictor • The best prediction occurs when the predictors are moderately independent of each other, but each is highly correlated with the dependent (criterion) variable Y • Some interpretive problems resulting from multicollinearity can be resolved using path analysis (see Chapter 3 in Grimm and Yarnold)
Multicollinearity Issues in our Current SPSS Problem • From our SPSS output we note that the correlation between our two predictors, Daily Calorie Intake (X1) and People who Read (X2) is .682. This is a pretty high correlation for two predictors to be interpreted independently: it means each explains about half the variation in the other. If you look at the zero order correlation of our Y variable, average life expectancy with % people who read, you note that the correlation is quite high, .869. However, the value of r for the two variable combination was .905, which is an improvement. r YX1 r X1X2 r YX2
Multicollinearity Issues in our Current SPSS Problem, cont’d • The table below is excerpted from the more complete table on Slide 32. Look at the tolerance value. Recall that zero tolerance means very high multicollinearity (high intercorrelation among the predictors, which is bad). Tolerance is .535 for both variables (since there are only two, the value is the same for either one predicting the other) • VIF (variance inflation factor) is a completely redundant statistic with tolerance (it is 1/tolerance). The higher it is, the greater the multicollinearity. When there is no multicollinearity the value of VIF equals 1. Multicollinearity problems have to be dealt with (by getting rid of redundant predictor variables or other means) if VIF approaches 10 (that means that only about 10% of the variance in the predictor in question is not explained by the combination of the other predictors) In the case of our two predictors, there is some indication of multicollinearity but not enough to throw out one of the variables
Specification Errors • One type of specification error is that the relationship among the variables that you are looking at is not linear (e.g., you know that Y peaks at high and low levels of one or more predictors (a curvilinear relationship) but you are using linear regression anyhow. There are options for nonlinear regression available that should be used in such a case • Another type of specification error occurs when you have either underspecified or overspecified the model by (a) failing to include all relevant predictors (for example including weight but not height in an equation for predicting obesity or (b) including predictors which are not relevant. Most irrelevant predictors will not even show up in the final regression equation unless you insist on it, but they can affect the results if they are correlated with at least some of the other predictors • For proper specification nothing beats a good theory (as opposed to launching a fishing expedition)
Types of Multiple Regression Analysis • So far we have looked at a standard or simultaneous multiple regression analysis where all of the predictor variables were “entered” at the same time, that is, considered in combination with each other simultaneously • But there are other types of multiple regression analyses which can yield some interesting results • Hierarchical regression analysis refers to the method of regression in which not all of the variables are entered simultaneously but rather one at a time or a few at a time, and at each step the correlation of Y, the criterion variable, with the current set of predictors is calculated and evaluated. At each stage the R square that is calculated shows the incremental change in variance accounted for in Y with the addition of the most recently entered predictor, and that is exclusively associated with that predictor. • Tests can be done to determine the significance of the change in R square at each step to see if each newly added predictor makes a significant improvement in the predictive power of the regression equation • The order in which variables are entered makes a difference to the outcome. The researcher determines the order on theoretical grounds (exception is stepwise analysis)
Stepwise Multiple Regression • Stepwise multiple regression is a variant of hierarchical regression where the order of entry is determined not by the researcher but on empirical criteria • In the forward inclusion version of stepwise regression the order of entry is determined at each step by calculating which variable will produce the greatest increase in R square (the amount of variance in the dependent variable Y accounted for) at that step • In the backward elimination version of stepwise multiple regression the analysis starts off with all of the predictors at the first step and then eliminates them so that each successive step has fewer predictors in the equation. Elimination is based on an empirical criterion that is the reverse of that for forward inclusion (the variable that produces the smallest decline in R square is removed at each step)
Reducing the Overall Level of Type I Error • One of the problems with doing multiple regression is that there are a lot of significance tests being conducted simultaneously, but for all practical purposes each test is treated as an independent one even though the data are related. When a large number of tests are done, theoretically the likelihood of Type I error increases (failing to reject the null hypothesis when it is in fact true) • This is particularly problematic in stepwise regression with the iterative process of assessing significance of R square over and over again not to speak of the significance of individual regression coefficients • Therefore it is desirable to do something to reduce the increased chance of making Type I errors (finding significant results that aren’t there) such as keeping the number of predictors to a minimum to reduce the number of times you go to the normal table to obtain a significance level, or “dividing” the usual required confidence level by the number of predictors, or keeping the intercorrelation of the predictors as low as possible (avoiding use of redundant predictors, which would cause you to basically test the significance of the same relationship to Y over and over)
Reducing the Overall Level of Type I Error, cont’d • This may be of particular importance when the researcher is testing a theory which has a network of interlocking claims such that the invalidation of one of them brings the whole thing tumbling down • An issue of HCR (July 2003) devoted several papers to exploring this question • As mentioned in class before, the Bonferroni procedure is sometimes used, but it’s hard to swallow, as you have to divide the usual confidence level of .05 by the number of tests you expect to perform, so if you are conducting thirty tests, you have to set your alpha level at .05/30 or .0017 for each test. With stepwise regression it’s not clear in advance how many tests you will have to perform although you can estimate it by the number of predictor variables you intend to start off with