DNA sequencing
DNA sequencing. Part 1: Chemistry, instrumentation and data analysis Part 2: Large-scale operations, comparative sequencing. Part 3: Sequencing analysis, variation analysis. Abbrev 02/03/05. DNA sequencing: Importance. Basic blueprint for life; Aesthetics. Gene and protein. Function


DNA sequencing
E N D
Presentation Transcript
DNA sequencing • Part 1: Chemistry, instrumentation and data analysis • Part 2: Large-scale operations, comparative sequencing. • Part 3: Sequencing analysis, variation analysis. • Abbrev 02/03/05
DNA sequencing: Importance • Basic blueprint for life; Aesthetics. • Gene and protein. • Function • Structure • Evolution • Genome-based diseases- “inborn errors of metabolism.” • Genetic disorders • Genetic predispositions to infection • Diagnostics • Therapies
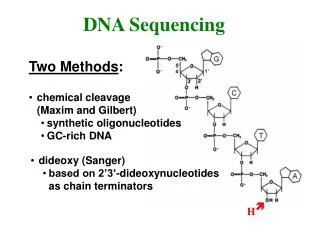
Maxam-Gilbert base modification by general and specific chemicals. depurination or depyrimidination. single-strand excision. not amenable to automation Sanger DNA replication. substitution of substrate with chain-terminator chemical. more efficient automation?? DNA sequencing methodologies: ca. 1977!
Sanger dideoxynucleotides versus “bio” based methods
O O O O O O P P P OH OH OH DNA sequencing: biochemistry 5’ purine or pyrimidine N HO C O purine or pyrimidine O N C O O O P OH 3’ OH
O O O O O O P P P OH OH OH DNA sequencing: Sanger dideoxy method I purine or pyrimidine N HO C O dideoxyribonucleoside triphosphate (ddNTP) H
O O O O O O P P P OH OH OH DNA sequencing: Sanger II purine or pyrimidine N HO C O purine or pyrimidine O chain termination method N C O O O P OH H
DNA sequencing: Chemistry template + primers + polymerase +label at? 1 dCTP dTTP dGTP dATP ddATP* 2 dCTP dTTP dGTP dATP ddGTP* 3 dCTP dTTP dGTP dATP ddTTP* 4 dCTP dTTP dGTP dATP ddCTP* electrophoresis A•T G•C A•T T•A C•G T•A G•C G•C A•T G•C T•A T•A C•G T•A G•C A•T extension
DNA sequencing: Chemistry template + polymerase + 1 dCTP dTTP dGTP dATP ddATP primer 2 dCTP dTTP dGTP dATP ddGTP primer 3 dCTP dTTP dGTP dATP ddTTP primer 4 dCTP dTTP dGTP dATP ddCTP primer electrophoresis A•T G•C A•T T•A C•G T•A G•C G•C A•T G•C T•A T•A C•G T•A G•C A•T extension
Semi-automated fluorescent DNA sequencing • Fred Sanger et. al., 1977. • Walter Gilbert et. al., 1977. • Leroy Hood et. al. 1986. • Applied Biosystems, Inc. • DuPont Company.
DNA sequencing: upgrade, second iteration, terminator-label • Disadvantages of primer-labels: • four reactions • tedious • limited to certain regions, custom oligos or • limited to cloned inserts behind ‘universal’ priming sites. • Advantages: • Solution: • fluorescent dye terminators
DNA sequencing: Chemistry template + polymerase + dCTP dTTP dGTP dATP ddATP ddGTP ddTTP ddCTP electrophoresis A•T G•C A•T T•A C•G T•A G•C G•C A•T G•C T•A T•A C•G T•A G•C A•T extension
ABI series: 370, 373 and 377 • semi-automated • “best” pre- and post- • higher throughput operations. • bioinformatics limitations, ‘scuze me- “opportunities.”
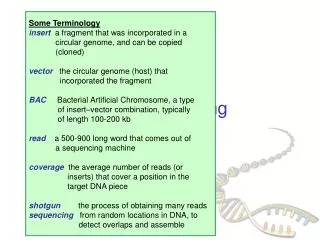
genome sequencing strategies • Shotgun • Directed primer walks • Modified directed primer walks
Sequencing strategies Whole genome Also on a smaller scale: 1. “Island walking” and 2. Primer walking.
Rapid re-sequencing of human Ad1: Time trial. Have sequence of Ad 1. In theory, have a minimally tiled set of PCR primers to cover entire 36,001 base genome. In theory, have a minimally tiled set of sequencing primers as well. Want draft sequence in a minimal time, including primer delivery from a vendor. In practice design two parallel sets of minimally tiled PCR primers and amplify two sets. In practice, assume 750 base reads--> 48 primers, one direction. Compare with consensus: Determine accuracy, timing and evaluate operation. 1 36,001 115 7,315 7,300 14,500 14,400 21,600 21,500 28,700 28,600 35,885
Custom primer walks and “island” hopping • Have scaffold of generic genome: related or compiled. • Have archived “islands of sequences” (lg, med, sm)- from other research interests. • Generate “in-bound” primers to re-sequence equivalents and known features, e.g., 3’-ITR. • Use custom “out-bound” primers to walk across “inter-island” sequences (PCR and sequencing. • Collect “1st +” draft genomic sequence as round 1. • Iterative walks to complete “2+1” consensus, with error rate 1/10,000 bases.
Target: HAdV4 • For 36,000 bases, need 90 primers for 1x coverage (1st draft) and 270 primers for 3x coverage (finished). • Have from GenBank: 10 “islands” @ 30%= 10,883 bases, • calling for 27x2= 54 primers for complementing coverage. • Theory (if continuous sequence): 36,000-10,883= 25,117 bases. • At 400 bases per read, need 63 primers for 1x coverage, or 126 for complementing coverage. • Practice: 10 “islands” @ 30%= 10,883 bases, 80 primers. • Example: “Island 1” is 149 bases. • 1 fragment at 400 bases/read. • 2 primers for 1x coverage. • “Terminal island,” need only 1 “outbound” primer. • Total of (1x2)+1= 3 primers. • Example: “Island 2” is 2042 bases. • 5 fragments at 400 bases/read. • “Internal island,” need 2 “outbound” primers. • Total of (5x2)+2= 12 primers.
Definition of tiled set of PCR primers: Data. C A B D G E F H PCR fragments “B” “C” “D” “E”
Input from sequencer peak intensities Output to user DNA sequence DNA sequencing: Computation • normalize intensities • apply mobility corrections • predict bands • call bases
Applications DNA sequencing • Whole genome analysis • Comparative genomics • Applications to subfields
DNA sequencing • HighER throughput
DNA sequencing technology • Manual. • ABI 370s series. • DuPont “Genesis.” • Capillary array: Hitachi, ABI, Amersham... • Ultrathin horizontal: GeneSys Tech. (MJResearch), Whitehead Inst., E. Yeung. • Thin channel. • “ABI” 310, 3100, 3710…….
Shimadzu, Ltd. • NEW ORLEANS, March 19, 2002. PittCon. • Faster and more economical DNA Sequencer. • 10 times faster and 90 percent cheaper to run than current state-of-the-art. • GenoMEMS, MA spinoff that has developed a microfabrication technology, based on Whitehead Inst. technology. • Microelectromechanical system, or MEMS, technology:microfabricated electrical and mechanical components • Five million bases per day. • Readlengths of 800 bases. • Target 2003.