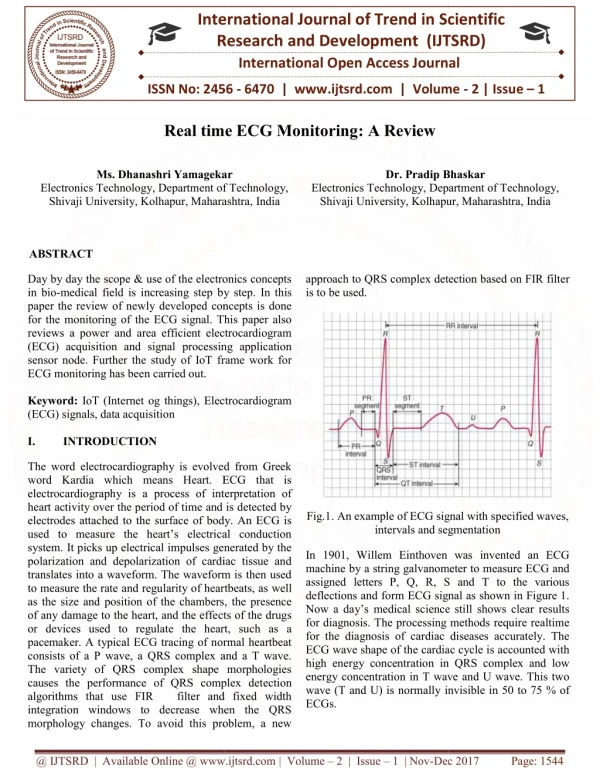
Download

1 / 4
0 likes | 3 Views
Datasets for Machine Learning Projects. The effectiveness of any machine learning initiative is significantly influenced by the quality and relevance of the dataset utilized for model training. Choosing an appropriate dataset is essential for attaining precise predictions and deriving valuable insights. This detailed guide will examine different categories of datasets, sources for obtaining them, methods for data preprocessing, and recommended practices for selecting datasets in machine learning endeavors.<br>

E N D
A Dataset for Monitoring Historical and Real-Time Air Quality to Support Pollution Prediction Models Globose Technology Solutions @Globose_Techn10 · 21h Introduction Datasets for Machine Learning Projects. The effectiveness of any machine learning initiative is significantly influenced by the quality and relevance of the dataset utilized for model training. Choosing an appropriate dataset is essential for attaining precise predictions and deriving valuable insights. This detailed guide will examine different categories of datasets, sources for obtaining them, methods for data preprocessing, and recommended practices for selecting datasets in machine learning endeavors. Significance of Datasets in Machine Learning A well-organized dataset is fundamental for the training of machine learning models. An appropriate dataset contributes to: Enhancing model accuracy Minimizing bias and overfitting Improving generalization Explore our developer-friendly HTML to PDF API Printed using PDFCrowd HTML to PDF
Yielding valuable insights Categories of Machine Learning Datasets 1. Structured vs. Unstructured Datasets Structured Data: Data that is systematically arranged in a tabular format, consisting of rows and columns (e.g., spreadsheets, databases). Unstructured Data: Data that lacks a predefined structure (e.g., images, videos, text, and audio). 2. Labeled vs. Unlabeled Datasets Labeled Data: Data that includes distinct input-output pairs, utilized in supervised learning. Unlabeled Data: Data that does not have labeled outcomes, employed in unsupervised learning. 3. Open vs. Proprietary Datasets Open Datasets: Datasets that are publicly accessible for research and training purposes. Proprietary Datasets: Exclusive datasets owned by businesses or organizations. Notable Datasets for Machine Learning Initiatives Explore our developer-friendly HTML to PDF API Printed using PDFCrowd HTML to PDF
1. Image Datasets MNIST: A dataset comprising handwritten digits intended for classification tasks. CIFAR-10 & CIFAR-100: A collection of small images designed for classification purposes. ImageNet: A comprehensive dataset utilized in deep learning applications. COCO: A dataset focused on object detection and image segmentation. 2. Text Datasets IMDb Reviews: A dataset used for sentiment analysis. 20 Newsgroups: A dataset for text classification. SQuAD: A dataset designed for question-answering tasks. 3. Audio Datasets LibriSpeech: An extensive collection of speech recordings. Common Voice: An open-source dataset aimed at speech recognition. 4. Tabular Datasets Titanic Dataset: A dataset used to predict survival outcomes on the Titanic. Iris Dataset: A well-known dataset utilized for classification. UCI Machine Learning Repository: A diverse collection of datasets addressing various machine learning challenges. 5. Healthcare Datasets MIMIC-III: A dataset containing data from ICU patients. COVID-19 Open Research Dataset: A dataset providing information for COVID-19 research. Data Preprocessing and Cleaning Raw datasets frequently contain issues such as missing values, duplicates, and extraneous noise. The preprocessing phase is essential for ensuring data integrity and preparing it for machine learning applications. Key steps involved include: Addressing Missing Values: Implement imputation methods. Eliminating Duplicates: Remove redundant entries. Normalizing Data: Adjust the scale of numerical features. Feature Engineering: Identify and extract pertinent features. Explore our developer-friendly HTML to PDF API Printed using PDFCrowd HTML to PDF
Guidelines for Selecting a Dataset Relevance: Opt for datasets that align with the specific problem being addressed. Size and Quality: Confirm that the dataset is sufficiently large and diverse. Elimination of Bias: Steer clear of datasets that exhibit inherent biases. Data Privacy: Utilize datasets that comply with legal standards. Conclusion The selection of an appropriate dataset is vital for the development of effective machine learning models. Whether the focus is on image recognition, natural language processing, or predictive analytics, the identification and preprocessing of the right dataset are fundamental Globose Technology Solutions achieving success. By utilizing open datasets and adhering to best practices, data scientists can enhance model performance and generate valuable insights. Vote: 0 0 0 Save as PDF 3 visits · 2 online Explore our developer-friendly HTML to PDF API Printed using PDFCrowd HTML to PDF