Progress of Sphinx 3.X, From X=4 to X=5
350 likes | 1.03k Views
Progress of Sphinx 3.X, From X=4 to X=5. By Arthur Chan Evandro Gouvea Yitao Sun David Huggins-Daines Jahanzeb Sherwani. What is CMU Sphinx?. Definition 1 : a large vocabulary speech recognizer with high accuracy and speed performance. Definition 2 :

Progress of Sphinx 3.X, From X=4 to X=5
E N D
Presentation Transcript
Progress of Sphinx 3.X, From X=4 to X=5 By Arthur Chan Evandro Gouvea Yitao Sun David Huggins-Daines Jahanzeb Sherwani
What is CMU Sphinx? • Definition 1 : • a large vocabulary speech recognizer with high accuracy and speed performance. • Definition 2 : • a collection of tools and resources that enables developers/researchers to build successful speech recognizers
Brief History of Sphinx • More detail version can be found at, • www.cs.cmu.edu/~archan/presentation/SphinxDev20040624.ppt 1987 Sphinx I 1992 Sphinx II 1996 Sphinx III “S3 slow” 1999 Sphinx III “S3 fast” or S3.2 2001-2002 -Sphinx IV Development Initiated -S3.3 2004 Jul S3.4 2004 Oct S3.5 RCII 2000 Sphinx become open-source
What is Sphinx 3.X? • An extension of Sphinx 3’s recognizers • “Sphinx 3.X (X=5)” means “Sphinx 3.5” • It helps to confuse people more. • Provide functionalities such as • Real-time speech recognition • Speaker adaptation • Developers Application Interfaces (APIs) • 3.X (X>3) is motivated by Project CALO
Development History of Sphinx 3.X S3 -Sphinx 3 flat-lexicon recognizer (s3 slow) S3.2 -Sphinx 3 tree-lexicon recognizer (s3 fast) S3.3 -w live-mode demo S3.4 -fast GMM computation -support class-based LM -some support for dynamic LM S3.5 –some support on speaker adaptation -live mode APIs -Sphinx 3 and Sphinx 3.X code merge
This talk • A general summary of what’s going on. • Less technical than 3.4 talk • Folks were so confused by jargons in speech recognition’s black magic. • More for code development, less for acoustic modeling • Reason: I have not much time to do both • (Incorrect version): “We need to adopt the latest technology to clown 2 to 3 Arthur Chan(s) for the CALO project.” –Prof. Alex Rudnicky, in one CALO meeting in 2004 • (“Kindly” corrected by Prof. Alan Black): “We need to adopt the latest technology to clone 2 to 3 Arthur Chan(s) for the CALO project.” –Prof. Alex Rudnicky, in one CALO meeting in 2004 • More on a project point of view • Speech recognition software easily shows phenomena described in “Mythical Man-Month”.
This talk (outline) • Sphinx 3.X, The recognizer (From X=4 to X=5) (~10 pages) • Accuracy and Speed (5 pages) • Speaker Adaptation (1 page) • Application Interfaces (APIs) (2 pages) • Architecture (2 pages) • Sphinx as a collection of resources (~10 pages) • Code distribution and management (3 pages) • Infrastructure of Training (1 page) • SphinxTrain: tools of training acoustic models. (1 page) • Documentation (3 pages) • Team and Organization (2 pages) • Development plan for Sphinx 3.X (X >= 6) (2 pages) • Relationship between speech recognition and other speech researches. (4 pages)
Accuracy and Speed • Why Sphinx 3.X ? Why not Sphinx 2? • Due to the limitation of computation in 90s • S2 only support restricted version of semi-continuous HMM (SCHMM) • S3.X supports fully continuous HMM (FCHMM) • Accuracy improvement is around relative 30% • You will see benchmarking results two slides later • Speed • S3.X is still slower than S2 • But in many tasks, it seems to becomes reasonable to use it. • (YOU CAN FIND THE RESULTS FEWS SLIDES)
Speed • Fast Search techniques • Lexical tree search (s3.2) • Viterbi beam tuning and Histogram beam Pruning(s3.2) • Ravi’s talk www.cs.cmu.edu/~archan/presentation/s3.2.ppt • Phoneme look-ahead (s3.4 by Jahanzeb) • Fast GMM computation techniques (s3.4) • Using the measurement in the literature, that means • 75%-90% of GMM computation reduction with fast GMM computation + pruning. • <10% relative degradation can usually be achieved in clean database. • Further Detail: “Four-Layer Categorization Scheme of Fast GMM Computation Techniques“ A. Chan et al.
Accuracy Benchmarking (Communicator Task) • Test platform, 2.2G Pentium IV • CMU Communicator task • Vocabulary size (3k) , perplexity: ~90 • All tunings were done without sacrificing 5% performance. • Batch mode decoder is used. (decode) • Sphinx 2 (tuned w speed-up techniques) • WER: 17.8% (0.34xRT) • Baseline results Sphinx 3.X 32 gaussian-FCGMM • WER: 14.053% (2.40xRT) • Baseline results Sphinx 3.X, 64 gaussian-FCGMM • WER: 11.7% (~3.67xRT) • Tuned Sphinx 3.X 64 gaussian-FCGMM • WER: 12.851% (0.87 xRT), 12.152% (1.17xRT) • Rong can make it better: Boosting training results : 10.5%
Accuracy/Speed Benchmarking (WSJ Task) • Test platform, 2.2G Pentium • Vocabulary Size (5k) • Standard NVP task. • Trained by both WSJ0 and WSJ1 • Sphinx 2, 14.5% (?) • Sphinx 3.X, 8 gaussian-FCGMM • un-tuned 7.3% 1.6xRT • tuned: 8.29% 0.52xRT
Accuracy/SpeedBenchmarking (Future Plan) • Issue 1 : Large variance in GMM computation. • Average performance is good, worse case can be disastrous. • Issue 2 : Tuning requires a black magician • Automatic tuning is necessary. • Issue 3 : Still need to work on larger databases (e.g. WSJ 20k, BN) • training setup need to be dig up • Issue 4 : Speed up in noisy corpus is tricky. • Results are not satisfactory (20-30% degradation in accuracy)
Speaker Adaptation • Start to support MLLR-based speaker adaptation • y=Ax+b , estimate A, b in a maximum likelihood fashion (Legetter 94) • Current functionality of sphinx 3.X + SphinxTrain • Allow estimation of transformation matrix • Transforming means offline • Transforming means online • Decoder only support single regression class. • Code gives exactly the same results as Sam Joo’s code. • Not fully benchmarked yet, still experimental
Live-mode APIs • Thanks to Yitao • Sets of C APIs that provide recognition functionality • Close to Sphinx 2’s style of APIs • Speech recognition resource initialization/un-initialization • Functions for Utterance level begin/end/process waveforms
Live-mode APIs : What are missing? • What we lack • Dynamic LM addition and deletion • part of the plan of s3.6 • Finite state machine implementation • part of plan of s3.X where X=8 or 9 • End-pointer integration and APIs • Ziad Al Bawab’s model-based classifier • Now as a customized version, s3ep
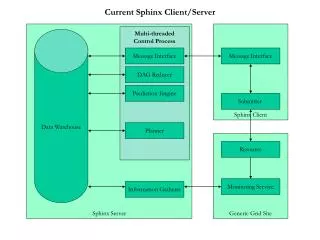
Architecture • “Code duplication is the root of many evils” • Four tools of s3 are now incorporated into S3.5 • align : an aligner • allphone : a phoneme recognizer • astar : lattice to N-best generation • dag : lattice best-path search • Many thanks to Dr. Carl Quillen of MIT Lincoln
Architecture : Next Step • decode_anytopo will be the next • Things we may incorporate someday • SphinxTrain • CMU-Cambridge LM Toolkit • lm3g2dmp and cepview
Code Distribution and Management • Distribution • Internal Release -> RC I -> RC II .. -> RC N • If no one yell during calm-down period of RC N • Then, put a tar ball on Sourceforge web page • At every release, • Distribution have to go through ~10 platforms of compilation • First announcement usually made at the RC period. • Web page is maintained by • Evandro (<-extremely sane)
Digression: Other versions of Sphinx 3.X • Code that are • Not satisfying design goal of the software • S3 slow w/ GMM Computation • www.cs.cmu.edu/~archan/software/s3fast.tgz • S3.5 with end-pointer • www.cs.cmu.edu/~archan/software/s3ep.tgz • CMU Researchers’ code and implementation • E.g. According to legend, Rita has >10 versions of Sphinx and SphinxTrain.
Code Management • Concurrent Versions System (CVS) is used in Sphinx • Also used in other projects e.g. CALO and Festival • A very effective way to tie resource and knowledge together • Problems : Still has a lot of separate versions of code in CMU not in Sphinx’s CVS. • Please kindly contact us if you work on something using Sphinx or derived from Sphinx
Infrastructure of Training • A need for persistence and version control • Baseline were lost after several years. • setup will be now available in CVS for • Communicator (11.5%) • WSJ 5k NVP (7.3%) • ICSI Phase 3 Training • Far from the state of the art • Need to re-engineer and do archeology • Will add more tasks to the archive • You are welcomed to change the setup if you don’t like it • But you need to check in what you have done
SphinxTrain • SphinxTrain is never officially released • Still under work. • For sphinx3.X (X>=5), corresponding timestamp of SphinxTrain will also be published. • Recent Progress • Better on-line help • Added support for adaptation • Better support in perl scripts for FCHMM (Evandro) • Silence deletion in Baum-Welch Training (experimental)
Hieroglyph: Using Sphinx for building speech recognizers • Project Hieroglyphs • An effort to build a set of complete documentation for using Sphinx, SphinxTrain and CMU LM Toolkit fo building speech applications. • Largely based on Evandro, Rita, Ravi, Roni’s docs. • “Editor”: Arthur Chan <- do a lot of editing • Authors: • Arthur, David, Evandro, Rita, Ravi, Roni, Yitao
Hieroglyph: An outline • Chapter 1: Licensing of Sphinx, SphinxTrain and LM Toolkit • Chapter 2: Introduction to Sphinx • Chapter 3: Introduction to Speech Recognition • Chapter 4: Recipe of Building Speech Application using Sphinx • Chapter 5: Different Software Toolkits of Sphinx • Chapter 6: Acoustic Model Training • Chapter 7: Language Model Training • Chapter 8: Search Structure and Speed-up of the Speech recognizer • Chapter 9: Speaker Adaptation • Chapter 10: Research using Sphinx • Chapter 11: Development using Sphinx • Appendix A: Command Line Information • Appendix B: FAQ
Hieroglyph: Status • Still in the drafting stage • Chapter I : License and use of Sphinx, SphinxTrain and CMU LM Toolkit (1st draft, 3rd Rev) • Chapter II : Introduction to Sphinx, SphinxTrain and CMU LM Toolkit (1st draft, 1st Rev) • Chapter VIII : Search Structure and Speed-up of Sphinx's recognizers (1st draft, 1st Rev) • Chapter IX: Speaker adaptation using Sphinx (1st draft, 2nd Rev) • Chapter XI: Development using Sphinx (1st draft, 1st Rev) • Appendix A.2: Full SphinxTrain Command Line Information (1st draft, 2nd Rev) • Writing Quality : Low • The 1st draft will be completed ½ year later (hopefully)
Team and Organization • “Sphinx Developers”: • A group of volunteers who maintain and enhance Sphinx and related resources • Current Members: • Arthur Chan (Project Manager / Coordinator) • Evandro Gouvea (Maintainer / Developer) • David Huggins-Daines (Developer) • Yitao Sun (Developer) • Ravi Mosur (Speech Advisor) • Alex Rudnicky (Speech Advisor) • All of you • Application Developers • Modeling experts • Linguists • Users
Team and Organization • We need help! • Several positions are still available for volunteers: • Project Manager : Enable Development of Sphinx • Translation: kick/fix miscellaneous people (lightly) everyday. • Maintainer : Ensure integrity of Sphinx code and resource • Translation: a good chance for you to understand life more • Tester : Enable test-based development in Sphinx • Translation: a good way to increase blood pressure. • Developers : Incorporate state-of-art technology into Sphinx • Translation: deal with legacy code and start to write legacy code yourself • For your projects, you can also send us temp people. • Regular meetings are scheduled biweekly. • Though, if we are too busy, we just skip it.
Next 6 months: Sphinx 3.6 • More refined speaker adaptation • More support on dynamic LM • More speed-up of the code • Better documentation (Complete 1st Draft of Hieroglyph?) • Confidence measure(?)
If we still survive and have a full team…… • Roadmap of Sphinx 3.X (X>6) • X=7, • Decoder, Trainer code merge • FSG implementation • Confidence annotation • X=8 : • Trainer fixes • LM manipulation support • X=9 : • Better covariance modeling and speaker adaptation • Hieroglyph completed • X>= 10 : To move on, innovation is necessary.
Speech recognition and other Research • The goal of Sphinx • Support innovation and development of new speech applications • A conscious and correct decision in long term speech recognition research • In Speech Synthesis: • aligner is important for unit selection • In Parsing/Dialog Modeling: • Sphinx 3.X still has a lot of errors! • We still need Phoenix! (Robust Parser) • We still need Ravenclaw House! (Dialog Manager) • In Speech Applications • Good recognizer is the basis
Cost of Research in Speech Recognition • 30% WER reduction is usually perceivable to users • i.e. roughly translate to 1-2 good algorithmic improvements • Under a well-educated researchers group • known techniques usually require ½ year to implement and test. • Unknown techniques will take more time. (1 year per innovation) • Experienced developers : • 1 month to implement known techniques • 3 months to innovate
Therefore…… • It still makes sense to continuously support on, • speech recognizer development • acoustic modeling improvement. • To consolidate, what we were lacking • 1, code and project management • Multi-developer environment is strictly essential. • 2, transferal of research to development • 3, acoustic modeling research: discriminative training, speaker adaptation
Future of Sphinx 3.X • ICSLP 2004 • “From Decoding Driven to Detection-Based Paradigms for Automatic Speech Recognition” by Prof. Chin-Hui Lee • Speech Recognition: • Still an open problem at 2004 • Role of Speech Recognition in Speech Application: • Still largely unknown • Require open minds to understand
Conclusion • We’ve done something in 2004 • Our effort starts to make a difference • We still need to do more in 2005 • Making a Sphinx 3.X a backbone of speech application development • Consolidation of the current research and development in Sphinx • Seek for ways for sustainable development