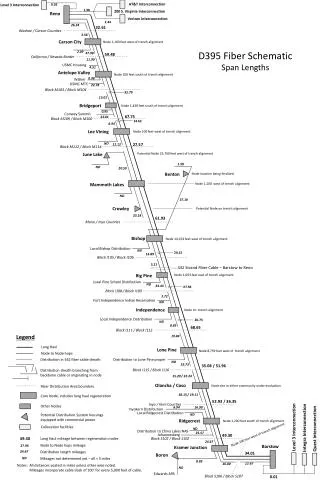
Download

1 / 11
110 likes | 123 Views
Object Recognition: A Statistical Learning Perspective. Christopher M. Bishop. Microsoft Research, Cambridge. Sicily, 2003. Question 1. “Will visual category recognition be solved by an architecture based on classification of feature vectors using advanced learning algorithms?” No

E N D
Object Recognition:A Statistical Learning Perspective Christopher M. Bishop Microsoft Research, Cambridge Sicily, 2003
Question 1 • “Will visual category recognition be solved by an architecture based on classification of feature vectors using advanced learning algorithms?” • No • large number of classes • many degrees of freedom of variability (geometric, photometric, ...) • transformations are highly non-linear in the pixel values(objects live on non-linear manifolds) • occlusion • expensive to provide detailed labelling of training data
Question 2 • “If we want to achieve a human like capacity to recognise 1000s of visual categories, learning from a few examples, what will move us forward most significantly?” • Large training sets • algorithms which can effectively utilize lots of unlabelled/partially labelled data • But: should the models be generative or discriminative?
Generative vs. Discriminative Models • Generative approach: separately model class-conditional densities and priorsthen evaluate posterior probabilities using Bayes’ theorem • Discriminative approaches: • model posterior probabilities directly • just predict class label (no inference stage)
Advantages of Knowing Posterior Probabilities • No re-training if loss matrix changes • inference hard, decision stage is easy • Reject option: don’t make decision when largest probability is less than threshold • Compensating for skewed class priors • Combining models • e.g. independent measurements:
Unlabelled Data Class 2 Test point Class 1
Generative Methods • Relatively straightforward to characterize invariances • They can handle partially labelled data • They wastefully model variability which is unimportant for classification • They scale badly with the number of classes and the number of invariant transformations (slow on test data)
Discriminative Methods • They use the flexibility of the model in relevant regions of input space • They can be extremely fast once trained • They interpolate between training examples, and hence can fail if novel inputs are presented • They don’t easily handle compositionality (e.g. faces can have glasses and/or moutaches and/or hats)
Hybrid Approaches • Generatively inspired models, trained discriminatively • state of the art in speech recognition • hidden Markov model handles time-warp invariances • parameters determined by maximum mutual information not maximum likelihood