Download

1 / 17
170 likes | 198 Views
Introduction to Bioinformatics: Lecture VII Clustering and Unsupervised Learning. Jarek Meller Division of Biomedical Informatics, Children’s Hospital Research Foundation & Department of Biomedical Engineering, UC. Outline of the lecture.

E N D
Introduction to Bioinformatics: Lecture VIIClustering and Unsupervised Learning Jarek Meller Division of Biomedical Informatics, Children’s Hospital Research Foundation & Department of Biomedical Engineering, UC JM - http://folding.chmcc.org
Outline of the lecture • From information flood to knowledge: finding an inherent “structure” in the data using unsupervised learning approach • Clustering analysis as data mining and knowledge discovery approach • The notion of similarity and its importance in clustering • K-means and hierarchical clustering algorithms JM - http://folding.chmcc.org
Literature watch: “Mathematics in Biology” featured in Science From Bayesian networks to game theory in biology …. http://www.sciencemag.org/ Reading assignment: Friedman N., “Inferring Cellular Networks Using Probabilistic Graphical Models”, Science 303 (2004) JM - http://folding.chmcc.org
Clustering and cluster analysis: general considerations Definition The goal of clustering analysis is to group a collection of objects into subsets called clusters, such that the objects within each cluster are more closely related than objects assigned to different clusters. JM - http://folding.chmcc.org
One classical example: gene expression data Samples ... Picture: courtesy of B. Aronow
Another example: clustering and organizing hierarchically protein structures in CATH http://www.biochem.ucl.ac.uk/bsm/cath/ Orengo et. al. Overall structure of the protein universe: Which cluster does my protein belong to? Measuring similarity to cluster representatives … JM - http://folding.chmcc.org
Similarity and distance measures in clustering • Clustering (or segmentation) of objects starts with the arbitrary choice of a similarity measure that describes proximity between different objects • The choice of the similarity (or dissimilarity/distance) measure ultimately defines the outcome of the clustering and is far more important than the choice of the actual clustering algorithm • Subject specific considerations provide a suitable similarity notion, externally to the actual clustering JM - http://folding.chmcc.org
Distance and similarity measures for string matching JM - http://folding.chmcc.org
Similarity and distance measures in clustering • In general, any similarity measure can be converted into a dissimilarity measure by applying a suitable monotone-decreasing function • For N objects one may define an N times N matrix D with non-negative entries (and zero diagonal elements) representing dissimilarity for each pair of objects • Some clustering algorithms assume that the dissimilarity or distance measure is a metric Problem Assuming that D is not symmetric, define a modified symmetric distance measure. JM - http://folding.chmcc.org
Similarity measures JM - http://folding.chmcc.org
Some observations regarding similarity measures JM - http://folding.chmcc.org
K-mean heuristic as a solution to clustering problem • Definition For N objects and K<N postulated clusters find an assignment of each object to one of the clusters that minimizes “within cluster” point scatter cost function • The number of possible assignments scales exponentially (again ) and in fact clustering problem is another instance of global optimization problem • K-means is an iterative greedy descent algorithm that attempts to find good solution (local minimum) • Trying different initial solution may be a good idea JM - http://folding.chmcc.org
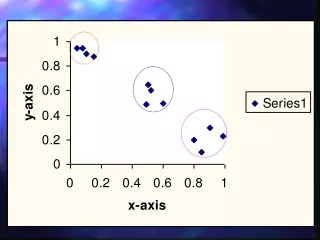
K-means algorithm Step 1: Choose K initial cluster centers (e.g. randomly chosen data points) and the resulting cluster assignment: each point is assigned to the closest cluster center. JM - http://folding.chmcc.org
K-means algorithm Step 2: Given the initial cluster assignment find new cluster centers as geometric centers of all the data points (vectors) in each cluster. Redefine cluster assignments using the new centers JM - http://folding.chmcc.org
K-means algorithm Iterate Step 2 until cluster assignments do not change. JM - http://folding.chmcc.org
Hierarchical clustering and its applications • As opposed to K-means there is no predefined number of clusters • Instead, groups (cluster) are built iteratively form pairwise dissimilarities (distances), such that at level of the hierarchy clusters are created by merging (or splitting) clusters at the next (previous) level • Representations of the data structure as rooted binary trees: a convenient analysis tool JM - http://folding.chmcc.org
Hierarchical clustering: agglomerative vs. divisive strategies One may use height of the nodes to indicate the intergroup dissimilarity between the two daughter nodes (subclusters at this level). One may also order the tree (dendogram) by flipping the branches, such that the tighter cluster is placed e.g. to the left. Cut K=2 Cut K=3 The example above is just an illustration of divisive (top-down) strategy JM - http://folding.chmcc.org